双目测距系列(七)monodepth2训练前数据集准备过程的简析
前言
上一篇文章说过,monodepth2模型有三种训练方式。针对我们的双目场景,准备使用stereo training方法。
monodepth2的训练入口函数在train.py中,如下图所示。

总共就2行代码,第一行代码(类Trainer的构造函数)主要是来初始化和数据集准备;第二行代码(Trainer类的成员函数)是真正执行训练过程。
下文将结合代码讲解数据集准备过程。
数据加载
在Train()构造函数中,首先会对Trainer类成员变量进行初始化。这里会摘取重点部分进行讲解。
1)
self.num_scales = len(self.opt.scales)
self.num_input_frames = len(self.opt.frame_ids)
代码中的opt是对options.py中的参数parse得到的dict。其参数对应值可以通过运行train.py脚本时输入参数来进行设置,如下所示。如果在运行train.py时没有显示指定参数值,那么该参数就对应使用缺省值。
python train.py --frame_ids 0 --use_stereo回到代码,因为在运行train.py时没有输入scales参数,所以其为缺省值[0,1,2,3],其含义是在encoder和decoder时进行4级缩小和放大的多尺度,其倍数分别对应为1, 2, 4, 8。
frame_ids的缺省值为[0,-1,1],这里如果采用stereo training的话 要显示输入参数:--frame_ids 0,即当前图片,而不考虑它的时间域上的上一帧和下一帧。
2)
if self.opt.use_stereo:
self.opt.frame_ids.append("s")如果是stereo training,那么需要显示添加参数--use_stereo,这样上面代码if条件为true, frame_ids就变成了["0", "s"]
3)接下来就到了数据加载部分
datasets_dict = {"kitti": datasets.KITTIRAWDataset,
"kitti_odom": datasets.KITTIOdomDataset}
self.dataset = datasets_dict[self.opt.dataset]KITTI数据集有两个子类型:KITTIRAW和KITTIOdom,monodepth使用的是前者,本系列四(https://blog.csdn.net/ltshan139/article/details/105794584)有专门对它进行说明。
fpath = os.path.join(os.path.dirname(__file__), "splits", self.opt.split, "{}_files.txt")
train_filenames = readlines(fpath.format("train"))
val_filenames = readlines(fpath.format("val"))
img_ext = '.png' if self.opt.png else '.jpg'上面第一行代码来获取train和valid的文件路径:fpath。在monodepth2开源项目根目录下有一个splits的子目录,然后在它的下面又分了eigen, eigen_full和eigen_zhou等子目录,最后每个子目录下才带有train_files.txt和val_files.txt。其目录结构如下所示:
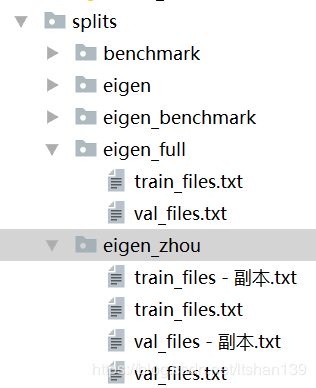
根据github上的readme,单目训练时推荐用的是eigen_zhou,双目用的是eigen_full。
最后一行img_ext用来显示告诉当前训练和验证样本图片的格式是png还是jpg。
train_dataset = self.dataset(
self.opt.data_path, train_filenames, self.opt.height, self.opt.width,
self.opt.frame_ids, 4, is_train=True, img_ext=img_ext)
self.train_loader = DataLoader(
train_dataset, self.opt.batch_size, True,
num_workers=self.opt.num_workers, pin_memory=True, drop_last=True)
val_dataset = self.dataset(
self.opt.data_path, val_filenames, self.opt.height, self.opt.width,
self.opt.frame_ids, 4, is_train=False, img_ext=img_ext)
self.val_loader = DataLoader(
val_dataset, self.opt.batch_size, True,
num_workers=self.opt.num_workers, pin_memory=True, drop_last=True)上面的代码就是真正数据加载部分。因为train和valid数据加载原理一样,而且DatalLoader是pytorch的API,没啥好讲的,所以这里主要分析下train_dataset = self.dataset(...)的运行过程。
前面已经讲过了 self.dataset=datasets.KITTIRAWDataset。调用self.dataset(...)实际上调用的是datasets.KITTIRAWDataset的构造函数,如下所示。
class KITTIRAWDataset(KITTIDataset):
"""KITTI dataset which loads the original velodyne depth maps for ground truth
"""
def __init__(self, *args, **kwargs):
super(KITTIRAWDataset, self).__init__(*args, **kwargs)
其构造函数只有一行代码: super(KITTIRAWDataset, self).__init__(*args, **kwargs),实际上它会调用其父类KITTIDataset的构造函数,如下所示。
class KITTIDataset(MonoDataset):
"""Superclass for different types of KITTI dataset loaders
"""
def __init__(self, *args, **kwargs):
super(KITTIDataset, self).__init__(*args, **kwargs)
。。。 。。。里面的super函数又会调用KITTIDataset的父类MonoDataset的构造函数。
class MonoDataset(data.Dataset):
"""Superclass for monocular dataloaders
Args:
data_path
filenames
height
width
frame_idxs
num_scales
is_train
img_ext
"""
def __init__(self,
data_path,
filenames,
height,
width,
frame_idxs,
num_scales,
is_train=False,
img_ext='.jpg'):
super(MonoDataset, self).__init__()
self.data_path = data_path
self.filenames = filenames
self.height = height
self.width = width
self.num_scales = num_scales
self.interp = Image.ANTIALIAS
self.frame_idxs = frame_idxs
self.is_train = is_train
self.img_ext = img_ext
self.loader = pil_loader
self.to_tensor = transforms.ToTensor()
。。。 。。。注意,self.dataset(。。。)所带的实参全部赋值给了MonoDataset(。。。),比如说data_path, filenames等。相当于把全部训练和验证样本文件名拿到了,以便后面训练时一个一个batch来从数据集里面随机抽取。
MonoDataset的构造函数运行完成后再回到KITTIDataset的构造函数剩余部分执行。