hadoop组件---spark实战-----airflow----调度工具airflow的介绍和使用示例
Airflow是什么
Airflow是一个可编程,调度和监控的工作流平台,基于有向无环图(DAG),airflow可以定义一组有依赖的任务,按照依赖依次执行。airflow提供了丰富的命令行工具用于系统管控,而其web管理界面同样也可以方便的管控调度任务,并且对任务运行状态进行实时监控,方便了系统的运维和管理,可视化方面和易用性都是很好的。
2019年airflow 已经成长为apache的顶级项目了,跟spark搭配是很常用的场景。
只要符合定时任务流的工作,都可以用Airflow来实现。我们主要用Airflow来实现定时的ETL处理。
我们经常会使用spark来做etl,但是etl的流程和步骤是很多的,比如先清洗什么,再清洗什么,有一个步骤需要上一个步骤清洗完了才能启动。最原始的肯定是人工监控 和 手动调度执行。但是这样太累了。
airflow能很好的实现自动化这部分的逻辑。
只需要我们编写好 相关 执行顺序以及依赖的DAG流程。 airflow就能按照定好的流程自动进行调度运行。
airflow官网
airflow官网文档
github
相关概念和原理
1、DAG
DAG 意为有向无循环图,在 Airflow 中则定义了整个完整的作业。同一个 DAG 中的所有 Task 拥有相同的调度时间。
2、Task
Task 为 DAG 中具体的作业任务,它必须存在于某一个 DAG 之中。Task 在 DAG 中配置依赖关系,跨 DAG 的依赖是可行的,但是并不推荐。跨 DAG 依赖会导致 DAG 图的直观性降低,并给依赖管理带来麻烦。
3、DAG Run
当一个 DAG 满足它的调度时间,或者被外部触发时,就会产生一个 DAG Run。可以理解为由 DAG 实例化的实例。
4、Task Instance
当一个 Task 被调度启动时,就会产生一个 Task Instance。可以理解为由 Task 实例化的实例
5、执行器(Executor)
Airflow本身是一个综合平台,它兼容多种组件,所以在使用的时候有多种方案可以选择。比如最关键的执行器就有四种选择:
SequentialExecutor:单进程顺序执行任务,默认执行器,通常只用于测试
LocalExecutor:多进程本地执行任务
DaskExecutor :动态任务调度,主要用于数据分析
CeleryExecutor:分布式调度,生产常用
celery是一个分布式调度框架,其本身无队列功能,需要使用第三方组件,比如redis或者rabbitmq,以rabbitmq为例,系统整体结构如下所示:
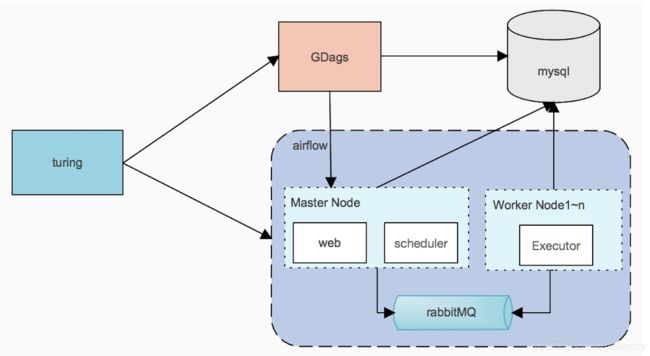
其中:
turing为外部系统
GDags服务帮助拼接成dag
master节点webui管理dags、日志等信息
scheduler负责调度,只支持单节点
worker负责执行具体dag中的task, worker支持多节点
在整个调度系统中,节点之间的传递介质是消息,而消息的本质内容是执行脚本的命令,也就是说,工作节点的dag文件必须和master节点的dag文件保持一致,不然任务的执行会出问题。
6、任务处理器
operator描述了工作流中的一个task,是一个抽象的概念,相当于抽象task定义
airflow内置了丰富的任务处理器,用于实现不同类型的任务:
BashOperator : 执行bash命令
PythonOperator : 调用python代码
EmailOperator : 发送邮件
HTTPOperator : 发送 HTTP 请求
SqlOperator : 执行 SQL 命令
除了这些基本的构建块之外,还有更多的特定处理器:DockerOperator,HiveOperator,S3FileTransferOperator,PrestoToMysqlOperator,SlackOperator
7、角色
webserver : 提供web端服务,以及会定时生成子进程去扫描对应的目录下的dags,并更新数据库
scheduler : 任务调度服务,根据dags生成任务,并提交到消息中间件队列中 (redis或rabbitMq)
celery worker : 分布在不同的机器上,作为任务真正的的执行节点。通过监听消息中间件: redis或rabbitMq 领取任务
flower : 监控worker进程的存活性,启动或关闭worker进程,查看运行的task
airflow特点
分布式任务调度:允许一个工作流的task在多台worker上同时执行
可构建任务依赖:以有向无环图的方式构建任务依赖关系
task原子性:工作流上每个task都是原子可重试的,一个工作流某个环节的task失败可自动或手动进行重试,不必从头开始任务
安装
# airflow needs a home, ~/airflow is the default,
# but you can lay foundation somewhere else if you prefer
# (optional)
export AIRFLOW_HOME=~/airflow
# install from pypi using pip
pip install apache-airflow
# initialize the database
airflow initdb
# start the web server, default port is 8080
airflow webserver -p 8080
# nohup airflow webserver -p 8080 > ~/airflow/active.log 2>&1 &
# start the scheduler
airflow scheduler
# 删除dag(需要先去~/airflow/dags中删除py文件)
airflow delete_dag -y {dag_id}
使用pip安装的安装路径一般在 python路径的site-packages中。
当在~/airflow/dags文件下添加py文件后,需要等待一会,才会在web中显示。
重新运行airflow scheduler可以立刻在web中显示py文件。
显示了py文件之后 我们就可以运行DAG了。
修改配置
基础配置airflow.cfg
安装好Airflow,第一次运行 airflow initdb 之后,会在Airflow文件夹下面产生一个airflow.cfg文件,这个就是基础配置文件。我们以这个基础文件作为模板来修改成为我们需要的配置文件。以下的操作都是找到对应的配置字段,修改其字段内容。
修改默认时区:default_timezone = Asia/Shanghai,说明:修改时区之后,Airflow前端页面仍旧会使用UTC时区显示,但是配合主机/容器的时区,这样我们在写dag任务执行时间的时候就不需要转换时区了。
修改执行器类型:executor = CeleryExecutor
不加载范例dag:load_example = False
不让同个dag并行操作:max_active_runs_per_dag = 1,说明:在ETL过程中,还是线性执行会比较好控制,如果里面需要批量操作,可以在ETL的具体处理过程中加入多线程或者多进程方式执行,不要在dag中体现
最高的dag并发数量:dag_concurrency = 16,说明:一般配置成服务器的CPU核数,默认16也没问题。
最高的任务并发数量:worker_concurrency = 16,说明:CeleryExecutor在Airflow的worker线程中执行的,这里配置的是启动多少个worker
数据库配置:sql_alchemy_conn = mysql://airflow:[email protected]:3306/airflow?charset=utf8,说明:我们一般是用MySQL来配合Airflow的运行
Celery Broker:broker_url = redis://:[email protected]:6379/0,说明:默认配置中两个redis配置被分到两个redis区,我们也照做吧。
Celery Result backend:result_backend = redis://:[email protected]:6379/1,说明:默认配置中两个redis配置被分到两个redis区,我们也照做吧。
五、MySQL需要注意的地方
mysql的配置中需要加入以下内容,不然执行会报错。需要在initdb之前加入并重启。
[mysqld]innodb_large_prefix = onexplicit_defaults_for_timestamp = 1
六、运行
由于使用的是CeleryExecutor,需要顺序执行三个进程:airflow webserver -Dairflow scheduler -Dairflow worker -D
常用管理airflow命令
airflow test dag_id task_id execution_date 测试task
示例: airflow test example_hello_world_dag hello_task 20200226
airflow run dag_id task_id execution_date 运行task
airflow run -A dag_id task_id execution_date 忽略依赖task运行task
airflow trigger_dag dag_id -r RUN_ID -e EXEC_DATE 运行整个dag文件
airflow webserver -D 守护进程运行webserver
airflow scheduler -D 守护进程运行调度
airflow worker -D 守护进程运行celery worker
airflow worker -c 1 -D 守护进程运行celery worker并指定任务并发数为1
airflow pause dag_id 暂停任务
airflow unpause dag_id 取消暂停,等同于在管理界面打开off按钮
airflow list_tasks dag_id 查看task列表
airflow clear dag_id 清空任务实例
web界面使用
启动web管控界面需要执行airflow webserver -D命令,默认访问端口是8080
假设部署在 192.168.30.11这台服务器上
在浏览器中访问 http://192.168.30.11:8080/admin/

(1) 任务启动暂停开关
(2) 任务运行状态
(3) 待执行,未分发的任务
(4) 手动触发执行任务
(5) 任务管控界面
选择对应dag栏目,点击(5)中的 Graph View即可进入任务管控界面
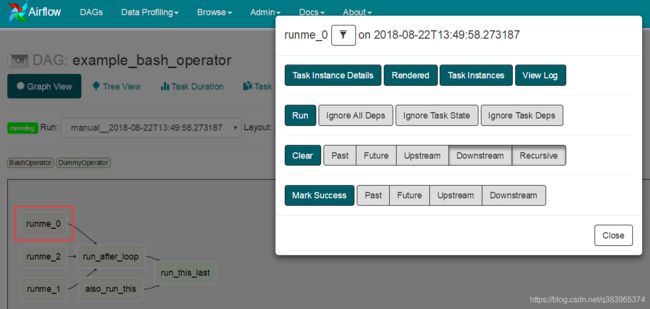
点击对应的任务,会弹出一个任务管控台,主要几个功能如下:
View Log : 查看任务日志
Run : 运行选中任务
Clear:清空任务队列
Mark Success : 标记任务为成功状态
在界面中配置参数
Menu -> Admin -> Variables

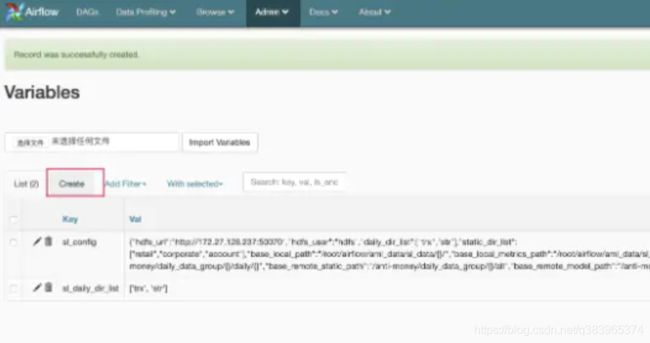
使用airflow
运行一个dag的流程
在~/airflow/dags文件下添加py文件,(需要等待一会,才会在web中显示,如果未开启webserver,也是可以运行的)
airflow unpause dag_id(取消暂停任务,任务会按照设定时间周期执行)
airflow trigger_dag dag_id(立刻运行整个dag)
重启一个dag的流程
rm -rf ~/airflow/dags/aml_sl_with_config.py
airflow delete_dag -y aml_sl_with_config
ps -ef |grep "airflow scheduler" |awk '{print $2}'|xargs kill -9
vi ~/airflow/dags/aml_sl_with_config.py
nohup airflow scheduler &
通过DAG文件实现定时任务
crontab语法
crontab格式如下所示:
# ┌───────────── minute (0 - 59)
# │ ┌───────────── hour (0 - 23)
# │ │ ┌───────────── day of month (1 - 31)
# │ │ │ ┌───────────── month (1 - 12)
# │ │ │ │ ┌───────────── day of week (0 - 6) (Sunday to Saturday;
# │ │ │ │ │ 7 is also Sunday on some systems)
# │ │ │ │ │
# │ │ │ │ │
# * * * * * command to execute
| 域 | 是否必须 | 取值范围 | 可用特殊符号 | 备注 |
|---|---|---|---|---|
| Minutes | Yes | 0–59 | * , - | |
| Hours | Yes | 0–23 | * , - | |
| Day of month | Yes | 1–31 | * , - ? L W | ? L W部分实现可用 |
| Month | Yes | 1–12 or JAN–DEC | * , - | |
| Day of week | Yes | 0–6 or SUN–SAT | * , - ? L # | ? L W 部分实现可用 |
| Year | No | 1970–2099 | * , - | 标准实现里无这一项 |
特殊符号功能说明:
逗号(,)
逗号用于分隔一个列表里的元素,比如 "MON,WED,FRI" 在第五域(day of week)表示Mondays, Wednesdays and Fridays。
连字符(-)
连字符用于表示范围,比如2000–2010表示2000到2010之间的每年,包括这两年(闭区间)。
百分号(%)
用于命令(command)中的格式化
L
表示last,最后一个,比如第五域,5L表示当月最后一个星期五
W
W表示weekday(Monday-Friday),指离指定日期附近的工作日,比如第三域设置为15L ,这表示临近当月15附近的工作日,假如15号是星期六,那么定时器会在14号执行,如果15号是星期天,那么定时器会在16号执行,也就是说只会在离指定日期最近的那天执行。
井号#
#用于第五域(day of week),#后面跟着一个1~5之间的数字,这个用于表示第几个星期,比如5#3表示第三个星期五
?
在有些实现里面,?与*的功能相同,还有一些实现里面?表示cron的启动时间,比如 当cron服务在8:25am启动,则? ? * * * *会更新为25 8 * * * *, 直到下一次cron服务重新启动,定时器会再次更新。
/
/一般与*组合使用,后面跟着一个数字,表示频率,比如在第一域(Minutes)中*/5表示每5分钟,是普通列表表示5,10,15,20,25,30,35,40,45,50,55,00的缩写
普通任务–helloWorld
from datetime import timedelta, datetime
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.dummy_operator import DummyOperator
default_args = { #默认参数
'owner': 'zzq', #dag拥有者,用于权限管控
'depends_on_past': False, #是否依赖上游任务
'start_date': datetime(2020, 2, 26), #任务开始时间,默认utc时间
'email': ['[email protected]'], #告警通知邮箱地址
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'example_hello_world_dag', #dag的id
default_args=default_args,
description='my first DAG', #描述
schedule_interval='*/20 * * * *', # crontab
start_date=datetime(2020, 2, 26) #开始时间,覆盖默认参数
)
def print_hello():
return 'Hello world!'
dummy_operator = DummyOperator(task_id='dummy_task', dag=dag)
hello_operator = BashOperator( #通过BashOperator定义执行bash命令的任务
task_id='sleep_task',
depends_on_past=False,
bash_command='echo `date` >> /home/py/test.txt',
dag=dag
)
dummy_operator >> hello_operator #设置任务依赖关系
#dummy_operator.set_downstream(hello_operator)
定义http任务并使用本地时间
import os
from datetime import timedelta, datetime
import pytz
from airflow.operators.http_operator import SimpleHttpOperator
from airflow.models import DAG
default_args = {
'owner': 'zzq',
# 'depends_on_past': False,
'depends_on_past': True,
'wait_for_downstream': True,
'execution_timeout': timedelta(minutes=3),
'email': ['[email protected]'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
#将本地时间转换为utc时间,再设置为start_date
tz = pytz.timezone('Asia/Shanghai')
dt = datetime(2020, 2, 26, 12, 20, tzinfo=tz)
utc_dt = dt.astimezone(pytz.utc).replace(tzinfo=None)
os.environ['AIRFLOW_CONN_HTTP_TEST']='http://localhost:9090'
dag = DAG(
'testtag01',
default_args=default_args,
description='my DAG',
schedule_interval='*/2 * * * *',
start_date=utc_dt
)
#通过SimpleHttpOperator定义http任务
task1 = SimpleHttpOperator(
task_id='get_op1',
http_conn_id='http_test',
method='GET',
endpoint='test1',
data={},
headers={},
dag=dag)
task2 = SimpleHttpOperator(
task_id='get_op2',
http_conn_id='http_test',
method='GET',
endpoint='test2',
data={},
headers={},
dag=dag)
task1 >> task2
参数细节
这里我们要特别注意一个关于调度执行时间的问题。在谈这个问题前,我们先确定几个名词:
start date: 在配置中,它是作业开始调度时间。而在谈论执行状况时,它是调度开始时间。
schedule interval: 调度执行周期。
execution date: 执行时间,在 Airflow 中称之为执行时间,但其实它并不是真实的执行时间。
那么现在,让我们看一下当一个新配置的 DAG 生效后第一次调度会在什么时候。很多人会很自然的认为,第一次的调度时间当然是在作业中配置的 start date,但其实并不是。
第一次调度时间是在作业中配置的 start date 的第二个满足 schedule interval 的时间点
并且记录的 execution date 为作业中配置的 start date 的第一个满足 schedule interval 的时间点。
另外,当作业已经执行过之后,start date 的配置将不会再生效,这个作业的调度开始时间将直接按照上次调度所对应的 execution date 来计算。
这个例子只是简要的介绍了一下 DAG 的配置,也只介绍了非常少量的配置参数。Airflow 为 DAG 和作业提供了大量的可配置参数,详情可以参考 Airflow 官方文档。
跳过非最新 DAG Run
假如有一个每小时调度的 DAG 出错了,我们把它的调度暂停,之后花了3个小时修复了它,修复完成后重新启动这个作业的调度。于是 Airflow 一下子创建了 3 个 DAG Run 并同时执行,这显然不是我们希望的,我们希望它只执行最新的 DAG Run。
我们可以创建一个 Short Circuit Operator,并且让 DAG 中所有没有依赖的作业都依赖这个作业,然后在这个作业中进行判断,检测当前 DAG Run 是否为最新,不是最新的直接跳过整个 DAG。
def skip_dag_not_latest_worker(ds, **context):
if context['dag_run'] and context['dag_run'].external_trigger:
logging.info('Externally triggered DAG_Run: allowing execution to proceed.')
return True
skip = False
now = datetime.now()
left_window = context['dag'].following_schedule(context['execution_date'])
right_window = context['dag'].following_schedule(left_window)
logging.info('Checking latest only with left_window: %s right_window: %s now: %s', left_window, right_window, now)
if not left_window < now <= right_window:
skip = True
return not skip
ShortCircuitOperator(
task_id='skip_dag_not_latest',
provide_context=True,
python_callable=skip_dag_not_latest_worker,
dag=dag
)
当存在正在执行的 DAG Run 时跳过当前 DAG Run
依旧是之前提到的每小时调度的 DAG,假设它这次没有出错而是由于资源、网络或者其他问题导致执行时间变长,当下一个调度时间开始时 Airflow 依旧会启动一次新的 DAG Run,这样就会同时出现 2 个 DAG Run。如果我们想要避免这种情况,一个简单的方法是直接将 DAG 的 max_active_runs 设置为 1。但这样会导致 DAG Run 堆积的问题,如果你配置的调度是早上 9 点至晚上 9 点,直至晚上 9 点之后 Airflow 可能依旧在处理堆积的 DAG Run。这样就可能影响到我们原本安排在晚上 9 点之后的任务。
我们可以创建一个 Short Circuit Operator,并且让 DAG 中所有没有依赖的作业都依赖这个作业,然后在这个作业中进行判断,检测当前是否存在正在执行的 DAG Run,存在时则直接跳过整个 DAG。
def skip_dag_when_previous_running_worker(ds, **context):
if context['dag_run'] and context['dag_run'].external_trigger:
logging.info('Externally triggered DAG_Run: allowing execution to proceed.')
return True
skip = False
session = settings.Session()
count = session.query(DagRun).filter(
DagRun.dag_id == context['dag'].dag_id,
DagRun.state.in_(['running']),
).count()
session.close()
logging.info('Checking running DAG count: %s' % count)
skip = count > 1
return not skip
ShortCircuitOperator(
task_id='skip_dag_when_previous_running',
provide_context=True,
python_callable=skip_dag_when_previous_running_worker,
dag=dag
)
使用的最佳实践
1、利用provide_context和XCOM在任务间传递信息
在default_args里面配置’provide_context’: True,这样在每个任务执行完之后都可以返回一个信息(当你需要的时候),可以使用xcom在不同的operator间传递变量。
这样每个任务都可以获取到之前任务执行返回的信息,以进行自身的处理操作。
以下是一个简单的例子:
# 任务1,获得数据并保存到文件中,返回文件名
def job_get_datas(**kwargs):
filename = get_datas() # 数据获取的函数,返回的是存储数据的文件名
return filename
operator_get_datas = PythonOperator(
task_id='task_get_datas',
python_callable=job_get_datas,
dag=dag
)
# 把存储文件的数据导入数据库
def job_data_2_mysql(**kwargs):
filename = kwargs['task_instance'].xcom_pull(task_ids='task_get_datas') # 获取task_get_datas任务返回的数据
result = data_2_mysql(filename) # 数据入库的函数
return result
operator_data_2_mysql = PythonOperator(
task_id='task_data_2_mysql',
python_callable=job_data_2_mysql,
dag=dag)
# 或者 先push到xcom中再pull
def processing_data(**kwargs):
kwargs['ti'].xcom_push(key='X', value=X)
kwargs['ti'].xcom_push(key='str_with_trx_with_retail_with_corporate_with_account', value=str_with_trx_with_retail_with_corporate_with_account)
processing_data_operator = PythonOperator(
task_id='processing_data_operator',
provide_context=True,
python_callable=processing_data,
dag=dag,
)
def predict(**kwargs):
ti = kwargs['ti']
X = ti.xcom_pull(key='X', task_ids='processing_data_operator')
predict_operator = PythonOperator(
task_id='predict_operator',
provide_context=True,
python_callable=predict,
dag=dag,
)
注意:由于这里的上下文信息(任务返回的数据)是存到Airflow的MySQL中,字段长度有限,所以不推荐返回具体数据,而是通过其他途径存储临时数据(例如临时文件形式),返回关键信息(例如临时文件的文件名),这样既不会因为异常断开导致整个任务流需要重跑,也不会因为数据量过大导致Airflow存储MySQL的时候报错。
2、处理逻辑与任务流执行分离
虽然在dag里面可以直接写python代码(Airflow本身也是用python实现的),但是不推荐将处理逻辑写在dag上面。这里有两方面的考虑:
在Airflow的前端界面中,是可以看到dag的代码的,将处理逻辑、特别是数据库或其他服务的用户密码暴露出来未必是好事;
如果将逻辑写在dag里面,那么在测试逻辑的时候,就太依赖Airflow了。这与解耦的开发逻辑思路相违背了,我们是需要一个松耦合的代码世界。
那么推荐在项目下面添加一个etl_utils目录(或者你喜欢的名称),用于存放处理逻辑。这个目录下一般分成三个子目录config、etl、system,分别是配置信息(数据库密码等)、逻辑代码、通用工具(如封装好的es操作类)。那么一般项目的目录结构如下:
-/dag_xxx.py-/test_xxx.py-/etl_utls/-/etl_utls/config/...-/etl_utls/etl/...-/etl_utls/system/...
所有的文件之间的调用层级以根目录为起点。我们在实现逻辑之后,就可以在根目录下编写测试代码,按顺序执行我们需要实现的流程。按这种方式测试完流程之后再组织dag。
3、关于中间数据
在处理逻辑中,我们尽量将每个处理过程细分出来,每个处理完成之后都将数据保存到临时文件中(中间处理过程,一般不要存数据库了,加大数据库的存取压力不是一件好事情,而且这些都是临时的信息),这些文件可以是同一个文件进行反复覆盖(每个任务流都取一个相对唯一的文件名,例如使用uuid,或者第一次处理的时间戳,加上任务流名字作为唯一辨识)。千万不要将这些信息放在内存里,万一挂了,就找不回来了,又要整个流程重新跑过。
4、临时文件
临时文件,注意同个任务流中保持一致,但是在不同任务流中需要能区分,有时候上一个任务流失败了,下一个任务流继续执行,那么如果没有区分能力,就会把上一个任务流的数据给覆盖掉了。注意在最后加上一个删除文件的处理,减少系统空间压力。
5、关于处理频率
机器的处理能力总是有限的,所以我们在条件允许的情况下,每次处理的数据量尽量减小。一般减小每次处理的数据量的方法,就是增加处理频率。但是加大处理频率,又会加大Airflow自身运行需要占用的资源。所以需要在数据量和频率之间找到一个平衡,这里每个项目可能有自己的特点,需要在每个项目的实际情况中找到适合项目的处理频率。
高可用airflow集群安装步骤
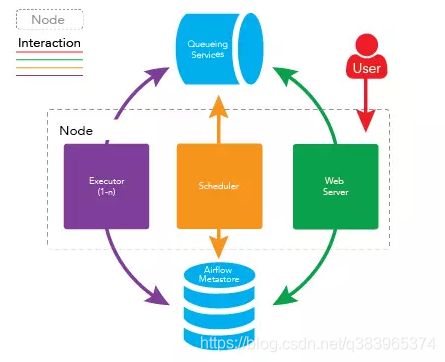
airflow 单节点部署
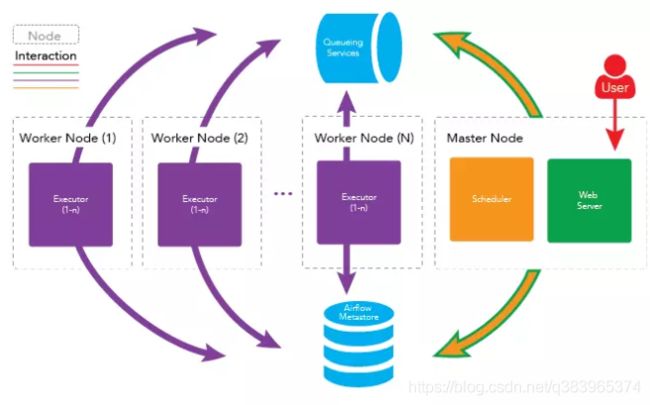
将以所有上守护进程运行在同一台机器上即可完成 airflow 的单结点部署,架构如下图所示
airflow 多节点(集群)部署
在稳定性要求较高的场景,如金融交易系统中,一般采用集群、高可用的方式来部署。Apache Airflow 同样支持集群、高可用的部署,airflow 的守护进程可分布在多台机器上运行,架构如下图所示:
这样做有以下好处
1)高可用
如果一个 worker 节点崩溃或离线时,集群仍可以被控制的,其他 worker 节点的任务仍会被执行。
2)分布式处理
如果你的工作流中有一些内存密集型的任务,任务最好是分布在多台机器上运行以便得到更快的执行。
扩展 worker 节点
水平扩展
你可以通过向集群中添加更多 worker 节点来水平地扩展集群,并使这些新节点指向同一个元数据库,从而分发处理过程。由于 worker 不需要在任何守护进程注册即可执行任务,因此所以 worker 节点可以在不停机,不重启服务下的情况进行扩展,也就是说可以随时扩展。
垂直扩展
你可以通过增加单个 worker 节点的守护进程数来垂直扩展集群。可以通过修改 airflow 的配置文件-{AIRFLOW_HOME}/airflow.cfg 中 celeryd_concurrency 的值来实现,例如:
celeryd_concurrency = 30
您可以根据实际情况,如集群上运行的任务性质,CPU 的内核数量等,增加并发进程的数量以满足实际需求。
扩展 Master 节点
您还可以向集群中添加更多主节点,以扩展主节点上运行的服务。您可以扩展 webserver 守护进程,以防止太多的 HTTP 请求出现在一台机器上,或者您想为 webserver 的服务提供更高的可用性。需要注意的一点是,每次只能运行一个 scheduler 守护进程。如果您有多个 scheduler 运行,那么就有可能一个任务被执行多次。这可能会导致您的工作流因重复运行而出现一些问题。
下图为扩展 Master 节点的架构图:

看到这里,可能有人会问,scheduler 不能同时运行两个,那么运行 scheduler 的节点一旦出了问题,任务不就完全不运行了吗?
答案: 这是个非常好的问题,不过已经有解决方案了,我们可以在两台机器上部署 scheduler ,只运行一台机器上的 scheduler 守护进程 ,一旦运行 scheduler 守护进程的机器出现故障,立刻启动另一台机器上的 scheduler 即可。我们可以借助第三方组件 airflow-scheduler-failover-controller 实现 scheduler 的高可用。
具体步骤如下所示:
下载 failover
git clone https://github.com/teamclairvoyant/airflow-scheduler-failover-controller
使用 pip 进行安装
cd{AIRFLOW_FAILOVER_CONTROLLER_HOME}
pip install -e .
初始化 failover
scheduler_failover_controller init
注:初始化时,会向airflow.cfg中追加内容,因此需要先安装 airflow 并初始化。
更改 failover 配置
scheduler_nodes_in_cluster= host1,host2
注:host name 可以通过scheduler_failover_controller get_current_host命令获得
配置安装 failover 的机器之间的免密登录,配置完成后,可以使用如下命令进行验证:
scheduler_failover_controller test_connection
启动 failover
scheduler_failover_controller start
因此更健壮的架构图如下所示:
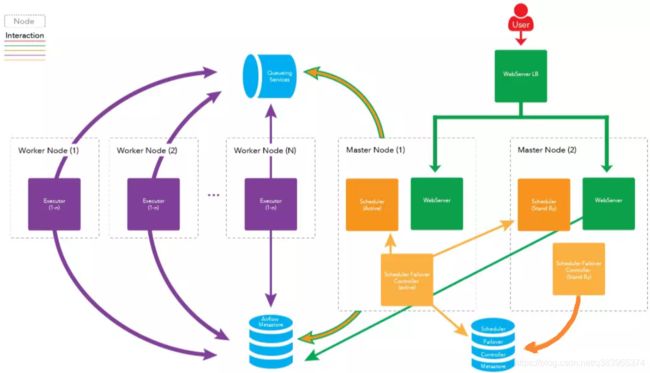
队列服务及元数据库(Metestore)的高可用。
队列服务取决于使用的消息队列是否可以高用可部署,如 RabbitMQ 和 Redis。
RabbitMQ 集群并配置Mirrored模式见:http://blog.csdn.net/u010353408/article/details/77964190
元数据库(Metestore) 取决于所使用的数据库,如 Mysql 等。
Mysql 做主从备份见:http://blog.csdn.net/u010353408/article/details/77964157
airflow 集群部署的具体步骤
前提条件
节点运行的守护进程如下:
master1
运行: webserver, scheduler
master2
运行:webserver
worker1
运行:worker
worker2
运行:worker
队列服务处于运行中. (RabbitMQ, Redis, etc)
安装 RabbitMQ 方法参见: http://site.clairvoyantsoft.com/installing-rabbitmq/
如果正在使用 RabbitMQ, 推荐 RabbitMQ 也做成高可用的集群部署,并为 RabbitMQ 实例配置负载均衡。
步骤
在所有需要运行守护进程的机器上安装 Apache Airflow。具体安装方法可参考 上面的简单安装。
修改 {AIRFLOW_HOME}/airflow.cfg 文件,确保所有机器使用同一份配置文件。
修改 Executor 为 CeleryExecutor
executor = CeleryExecutor
指定元数据库(metestore)
sql_alchemy_conn = mysql://{USERNAME}:{PASSWORD}@{MYSQL_HOST}:3306/airflow
设置中间人(broker)
如果使用 RabbitMQ
broker_url = amqp://guest:guest@{RABBITMQ_HOST}:5672/
如果使用 Redis
broker_url = redis://{REDIS_HOST}:6379/0 #使用数据库 0
设定结果存储后端 backend
celery_result_backend = db+mysql://{USERNAME}:{PASSWORD}@{MYSQL_HOST}:3306/airflow
#当然您也可以使用 Redis :celery_result_backend =redis://{REDIS_HOST}:6379/1
在 master1 和 master2 上部署您的工作流(DAGs)。
在 master 1,初始 airflow 的元数据库
$ airflow initdb
在 master1, 启动相应的守护进程
$ airflow webserver
$ airflow scheduler
在 master2,启动 Web Server
$ airflow webserver
在 worker1 和 worker2 启动 worker
$ airflow worker
使用负载均衡处理 webserver
可以使用 nginx,AWS 等服务器处理 webserver 的负载均衡,不在此详述
至此,所有均已集群或高可用部署,apache-airflow 系统已坚不可摧。
官方文档如下:
Documentation: https://airflow.incubator.apache.org/
Install Documentation: https://airflow.incubator.apache.org/installation.html
GitHub Repo: https://github.com/apache/incubator-airflow
参考链接:
如何部署一个健壮的 apache-airflow 调度系统
优化–架构和高可用集群
airflow中web server和worker都可以启动多个,但是scheduler只能启动一个,这样造成了airflow的单点,目前已经有第三方开源方案来解决这个问题:
Airflow Scheduler Failover Controller
地址:https://github.com/teamclairvoyant/airflow-scheduler-failover-controller
实现原理
The Airflow Scheduler Failover Controller (ASFC) 是一种保证机制,保证至少有一共scheduler在运行。
首先需要启动ASFC 在每个我们规划的用于运行scheduler的实例中。 当我们启动多个 ASFC时, 有一个会是启用状态,其他是备用状态。ASFC之间通过心跳机制跟踪确认scheduler可用,如果 心跳丢失,则启用备用ASFC。
活动状态的ASFC 每10秒会检查 scheduler的状态。 如果没有找到scheduler,会尝试重启schduler的daemon进程。
如果还是无法启动,则会在其他节点启用scheduler的进程。
安装
# git clone https://github.com/teamclairvoyant/airflow-scheduler-failover-controller
# cd airflow-scheduler-failover-controller
# pip install -e .
报错
Collecting airflow>=1.7.0 (from scheduler-failover-controller==1.0.1)
Could not find a version that satisfies the requirement airflow>=1.7.0 (from scheduler-failover-controller==1.0.1) (from versions: 0.6)
No matching distribution found for airflow>=1.7.0 (from scheduler-failover-controller==1.0.1)
查看
# vi setup.py
install_requires=[
'airflow>=1.7.0',
'kazoo>=2.2.1',
'coverage>=4.2',
'eventlet>=0.9.7',
],
# pip list|grep airflow
apache-airflow 1.10.0
需要将setup.py中airflow改为apache-airflow,安装之后启动
# scheduler_failover_controller -h
会报错
pkg_resources.ContextualVersionConflict: (Flask-Login 0.2.11 (/usr/lib64/python2.7/site-packages), Requirement.parse('Flask-Login<0.5,>=0.3'), set(['flask-appbuilder']))
重装Flask-Login
# pip uninstall Flask-Login
# pip install Flask-Login
重装之后是Flask-Login 0.4.1,满足要求,但是又会报错
apache-airflow 1.10.0 has requirement flask-login==0.2.11, but you'll have flask-login 0.4.1 which is incompatible.
Airflow Scheduler Failover Controller和airflow1.10.0不兼容;需要选用兼容的版本
优化–Sensor 的替代方案
Airflow 中有一类 Operator 被称为 Sensor,Sensor 可以感应预先设定的条件是否满足(如:某个时间点是否达到、某条 MySQL 记录是否被更新、某个 DAG 是否完成),当满足条件后 Sensor 作业变为 Success 使得下游的作业能够执行。Sensor 的功能很强大但却带来一个问题,假如我们有一个 Sensor 用于检测某个 MySQL 记录是否被更新,在 Sensor 作业启动后 3 个小时这个 MySQL 记录才被更新。于是我们的这个 Sensor 占用了一个 Worker 整整 3 小时,这显然是一个极大的浪费。
因此我们需要一个 Sensor 的替代方案,既能满足 Sensor 原来的功能,又能节省 Worker 资源。有一个办法是不使用 Sensor,直接使用 Python Operator 判断预先设定的条件是否满足,如果不满足直接 raise Exception,然后将这个作业的 retry_delay(重试间隔时间) 设为每次检测的间隔时间,retries(重试次数) 设为最长检测时间除以 retry_delay,即满足:最长检测时间 = retries * retry_delay。这样既不会长时间占用 Worker 资源,又可以满足 Sensor 原来的功能。
优化–Airflow DAG Creation Manager Plugin
Airflow 虽然具有强大的功能,但是配置 DAG 并不是简单的工作,也有一些较为繁琐的概念,对于业务人员来说可能略显复杂。因此,笔者编写了 Airflow DAG Creation Manager Plugin(https://github.com/lattebank/airflow-dag-creation-manager-plugin) 以提供一个 Web界面来让业务人员可视化的编写及管理 DAG。具体的安装及使用方法请查看插件的README。
插件的 Web 界面中可以直接所见即所得的编写 DAG 图。
插件中尽量简化了一些繁琐的诸如上文所述的作业开始调度时间等一系列的概念,并提供了一些在实际工作中常常会用到的一些额外的功能(如上文提到的跳过非最新 DAG Run、当存在正在执行的 DAG Run 时跳过当前 DAG Run 等),以及版本控制和权限管理。如果大家在使用 Airflow 的过程中也有类似的问题,欢迎尝试使用 Airflow DAG Creation Manager Plugin。