2019春招-网易数据分析工程师笔试
招聘要求
数据分析工程师
您可以:
- 负责网易游戏、网易CC(直播平台)、藏宝阁(虚拟道具电商)和网易大神(内容社交平台)等一至多款产品的数据分析工作;
- 配合产品、运营和营销等相关人员分析,理解需求,提供日常数据支持;
- 根据业务需要,设计数据日志埋点,并跟进数据质量;
- 根据业务特点,搭建数据监控和报警体系,实时发现问题,拆解分析核心KPI,解读数据波动;
- 对产品功能、运营活动等进行数据跟踪,输出优化建议,推动产品改进,帮助业务快速提升。
我们希望您具备以下条件:
- 2020届毕业,本科及以上学历,数据、统计、计算机等专业优先;
- 掌握一种数据分析工具,如python/sas等,熟练使用SQL和Excel;
- 逻辑清晰、好奇心强,良好的沟通能力和协作能力,敢于接受挑战,能够承受压力;
- 有大型网络游戏或直播产品使用经历,熟悉一款或多款网易旗下的网游者优先。
工作地点:广州
招聘人数:15人
招聘学校:国内重点高校、港澳台高校、海外高校
咨询邮箱:[email protected](注意:此邮箱仅提供咨询,不接受投递简历!简历投递请猛戳下方按钮)
咨询邮件主题格式:【姓名】【应聘职位】【学校】【学历】【年级】【专业】【电话】
笔试部分
2017 笔试部分 网易数据分析工程师
链接:https://www.nowcoder.com/discuss/22707
一.问答题(2道):
1.写出三个推荐系统的评价指标,并解释;
一个完整的推荐系统包括三部分用户,网站,内容提供方。
好的推荐系统设计,能够让推荐系统本身收集到高质量的用户反馈,不断完善推荐的质量,增加 用户和网站的交互,提高网站的收入。因此在评测一个推荐算法时,需要同时考虑三方的利益, 一个好的推荐系统是能够令三方共赢的系统。
二、测评指标
1.用户满意度:只能通过用户调查或在线实验获得。
对于用户调查方式,用调查问卷方式;对于在线实验方式,主要通过一些对用户行为的统计得到。
对于用户行为,可分为显性和隐性之分。若用户购买了推荐的商品,则说明在一定程度上满意,可用购买率度量。还可用用户反馈界面收集,通过统计两种按钮的单击情况度量。更一般的情况下,用点击率、用户停留时间和转化率等指标度量。
2.预测准确度:离线实验测评
表示一个推荐算法预测用户行为的能力。
2.1 评分预测(即打分)
一般用RMSE(均方根误差)和MAE(平均绝对误差)计算。RMSE加大了对预测不准的用户物品评分的惩罚,对系统的测评更加苛刻。
2.2 Top N推荐(即个性化推荐)
一般用准确率(precision)和召回率(recall)计算。准确率和召回率的定义如下:其中R(u)表示推荐的列表,T(u)表示真实的行为列表
为了全面测评TopN推荐,一般会选取不同的推荐列表长度计算出一组准确率和召回率,画出对应的曲线。
3.覆盖率
描述一个算法对长尾物品的挖掘能力。定义为推荐算法能推荐出的物品占总物品集合的比例,是内容提供商会关心的指标,热门排行榜的推荐覆盖率是很低的。
为了更细致地描述算法挖掘长尾的能力,需统计推荐列表中不同物品出现次数的分布。若所有的物品均出现在推荐列表中,且出现的次数差不多,则推荐系统发掘长尾的能力较好(这一点和最大熵模型很像!)。可用信息熵和基尼系数来表述。
很多研究表明,现在的主流推荐算法(如协同过滤算法)具有马太效应,即强者更强。测评一个推荐算法是否有马太效应的简单办法是使用基尼系数。具体方法是:分别计算推荐列表和初始用户行为的物品流行度的基尼系数,若推荐列表的基尼系数大,则推荐算法具有马太效应。
4.多样性
满足用户广泛的兴趣需求。描述了推荐列表中物品两两之间的不相似性。多样性和相似性对应。
5.新颖性
在网站中实现的最简单的做法是,把用户之前在网站中对其有过行为的物品从推荐列表中过滤掉,但金过滤掉本网站中用户有过行为的物品不能完全实现新颖性。
测评的最简单方法是利用推荐结果的平均流行度,越不热门的物品越可能让用户觉得新颖。要准确统计新颖性需作用户调查。
6.惊喜度(热点)
和新颖性的区别:若推荐结果和用户的历史兴趣不相似,但却让用户觉得满意,则表示惊喜度很高;而推荐结果的新颖性仅取决于用户是否听说过这个推荐结果。
7.信任度
只能通过问卷调查来度量。
提高信任度的方法主要有两种:首先需增加推荐系统的透明度,主要是提供推荐解释。其次是考虑用户的社交网络信息,即好友推荐。
8.实时性(常在物品和新闻类网站中要求)
实时更新推荐列表来满足用户新的行为变化。很多推荐系统都会在离线状态每天计算一次用户推荐列表,然后于在线期间将推荐列表展示给用户,这样很不及时,效果不好。可通过推荐列表的变化速率测评。需能将新加入的物品推荐给用户,考验推荐系统处理物品的冷启动能力。可用用户推荐列表中有多大比例的物品是当天新加的来测评。
9.健壮性
衡量算法抗击作弊的能力。最著名的是行为注入攻击。主要用模拟攻击测评。
一、实验方法
1.离线实验
需要有一个日志数据集,不需一个实际的系统来供它实验。
优点:不需真实用户参与,直接快速、方便,可测试大量算法。
缺点:无法获得很多商业上关注的指标,如点击率、转化率等。离线实验的指标和商业指标存在差距,如预测准确率和用户满意度间存在很大差别。
2.用户调查
在上线测试前需做一次用户调查。
优点:得到与用户主观感受有关的指标,相对在线实验风险很低,出现错误后很容易弥补
缺点:调查成本很高,需用户花大量时间完成一个任务并回答相关问题。需花钱雇佣测试用户,大多数情况下很难进行大规模的用户调查,得出的结果大多没有统计意义。设计双盲实验非常困难,且结果在真实环境下无法重现。
3.在线实验
在离线实验和用户调查后将推荐系统上线做AB测试,将新系统和旧算法进行比较。将用户随机分成几组,对不同组用户采用不同算法,比较不同算法性能。
优点:可公平获得不同算法实际在线时的性能指标,包括商业上关注的指标
缺点:周期较长,需进行长期实验才能得到可靠的结果。故只测试在离线实验和用户调查中表现较好的算法。
一般来说,一个新推荐算法上线要完成上述的3个实验。首先,须通过离线实验证明它在很多离线指标上优于现有的算法;然后,通过用户调查确定它的用户满意度不低于现有的算法;最后,通过在线AB测试确定它在我们关心的指标上优于现有的算法
指标包括准确度、覆盖度、新颖度、惊喜度、信任度、透明度等
2.电商推荐系统冷启动期与高峰期的数据分析有什么不同,可举例说明。(啥叫冷启动期,晕)
冷启动期,即然而我们常常面对的情况是用户的行为是稀疏的,而且可能存在比例不一的新用户,如何给新用户推荐,是推荐系统中的一个著名问题,即冷启动问题在这个时期是尽可能多的去收集用户信息,包括用户信息网络,
主要分三类:
1.用户冷启动:如何给新用户做个性化推荐。
2.物品冷启动:如何将新的物品推荐给可能对它感兴趣的用户这一问题。
3.系统冷启动:如何在一个新开发的网站上设计个性化推荐系统。
解决方案:
1.提供非个性化的推荐:热门排行榜,当用户数据收集到一定的时候,再切换为个性化推荐
2.利用用户注册时提供的年龄、性别等数据做粗粒度的个性化,做个用户画像,基于用户的登录信息,利用历史特征下某种特征喜欢某种物品的喜好程度。
3.利用用户的社交网络帐号登录,导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的物品
4.要求用户在登录时对一些物品进行反馈,收集用户对这些物品的兴趣信息,然后给用户推荐那些和这些物品相似的物品。
用户,用这群用户对物品评分的方差度量这群用户兴趣的一致程度。如果方差很小,说明这一群用户的兴趣不太一致,也就是物品具有比较大的区分度,反之则说明这群用户的兴趣比较一致,用一个决策树解决。
5.对于新加入的物品,可以利用内容信息,将它们推荐给喜欢过和它们相似的物品的用户。
6.在系统冷启动时,可以引入专家的知识,通过一定的高效方式迅速建立起物品的相关度表
https://www.cnblogs.com/MarsMercury/p/5169071.html
而对于高峰期数据需要考虑的是如何去筛选一些重要信息为推荐做准备
总结,考的不难,主要考察 数据库、数理统计、计算机网络基础、编程基础、推荐系统。
二.选择题(20道):
- 来自甲地的概率为0.4,来自乙地的概率为0.6,来自甲地患A病的概率为0.01,来自乙地患A病的概率为0.02,现有一患A病患者,求其来自甲地的概率。
2.2016的阶乘尾部有几个0
出现零的情况就是 5 的倍数乘以偶数。
但是出现0的个数就不一定了,25=10 出现一个0。425=100会出现2个0。8*125=1000出现3个0.依次类推。
偶数乘以5会出现一个0,乘以5的平方会出现2个0,乘以5的立方会出现3个0.
求100!后面0的个数。
由上所说的方法,是5的倍数的数有20(除去25的倍数),是25的倍数的数有20/5个,结果应该为20+4=24个0.
如果是求2016!后面0的个数呢?
同样按照上面的方法。
5的倍数个数为: 2016/5 = 403个
25的倍数个数为: 403/5 = 80个
125的倍数的个数为:80/5 = 16个
625的倍数的个数为: 16/5 = 3个。
所以可以得出2016!后面0的个数为:403+80+16+3 = 502个.
3.256的阶乘尾部有几个0.
5的倍数个数为: 256/5 = 51个
25的倍数个数为: 51/5 = 10个
125的倍数的个数为:10/5 = 2个
所以可以得出256!后面0的个数为:51+10+2=63个.
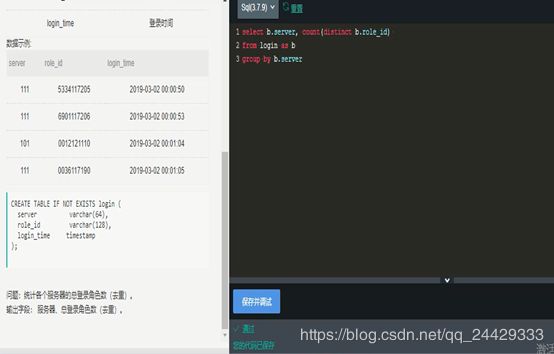
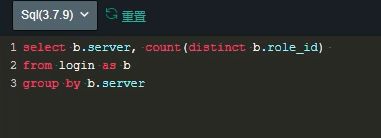
下列sql语句中与 selece * from math g.grade where g.grade not between 60 and 100等价的是
事务和读写锁的关系
小明头疼或者遇上堵车一定会迟到,小明头疼的概率是0.2,遇上堵车的概率是0.5,小明今天迟到了,请问他头疼的概率(?)0.2,遇上堵车的概率(?)0.5
链接:https://www.nowcoder.com/questionTerminal/9090b3de0fb541a5b3650c3114539634?pos=12&tagId=0&orderByHotValue=1
来源:牛客网
当未知是否迟到时:
(a) P(睡过头 and 堵车)=0.1,迟到
(b) P(睡过头and not堵车)=0.1,迟到
© P(not 睡过头 and 堵车)=0.4,迟到
(d) P(not 睡过头 and not 堵车)=0.4,不迟到
当已知迟到时,abc的概率分别为1/6 1/6 2/3,睡过头概率1/3,堵车概率5/6。
7.linux删除非空文件夹的命令 rm -rf 目录名
8.linux中的arp,ping, ifconfig,route命令的作用
arp实用arp命令,我们能够查看本地计算机或另一台计算机的ARP高速缓存中的当前内容
ping ping命令用于:确定网络和各外部主机的状态;跟踪和隔离硬件和软件问题;测试、评估和管理网络
ifconfig被用于配置和显示Linux内核中网络接口的网络参数。用ifconfig命令配置的网卡信息,在网卡重启后机器重启后,配置就不存在
route 用于显示和操作IP路由表
三.编程题
一个n*n的棋盘,B表示黑子,W表示白子,小易只在一列当中颜色连续相同的地方上色,求其上色区块的最长长度。
输入:
n
BWW
BBW
BWB
输出:3
解题思路:审题
拥有相同颜色的最大的区域必须连续
我们遍历棋牌中的每一列,计算每一列中颜色相同的最大区域数放入一个列表中,最后输出列表中最大的值即可
1. n = int(input())
2.
3.
4. def calc(col):
5. max_count = 1
6. count = 1
7. for x in range(1, n):
8. if col[x] == col[x-1]:
9. count += 1
10. if count > max_count:
11. max_count = count
12. else:
13. count = 1
14. return max_count
15.
16. maps = []
17. for i in range(n):
18. maps.append(input())
19. results = []
20. for i in range(n):
21. temp = ''
22. for each in maps:
23. temp += each[i]
24. results.append(calc(temp))
25.
26. print(max(results))
2.小易说n个单词,系统给m个单词,如果小易记得单词在系统中出现,得分为单词长度的平方。求总得分。注意单词不能重复得分
输入:
3 4
apple orange strawberry
strawberry orange grape watermelon
输出:
136
n, m = [int(each) for each in input().split()]
Yi_words = set(input().split())
Sys_words = set(input().split()[0:m])
scores = 0
for each in Yi_words:
if each in Sys_words:
scores += len(each)**2
原文:https://blog.csdn.net/qq_34617032/article/details/78546956
这道编程笔试还是比较简单的。就直接说我的大概思路吧:
1.首先判断是否写正确;
2.其次判断是否写重,都满足则添加进一个list里;
3.遍历list求出得分情况。
ok,接下来是Python的实现
li = raw_input().split()
n = li[0]
m = li[1]
rem = raw_input().split()
leng = len(rem)
words = raw_input().split()
total = 0
i = 0
result = []
while i < leng:
if rem[i] in words and rem[i] not in result:
result.append(rem[i])1
i += 1
for i in result:
total += len(i) ** 2
print total
2018实习生招聘笔试题——数据分析师实习生解析
1、有2堆宝石,A和B一起玩游戏,假设俩人足够聪明,规则是每个人只能从一堆选走1个或2个或3个宝石,最后全部取玩的人获胜,假设2堆宝石的数目为12和13,请问A怎么可以必胜?
答:先*
取获胜的情况:总个数不能整除时,余数为一次可取的个数
后取获胜的情况:总个数能整除时
只有一堆时,12时后取获胜,13时先取获胜
两堆时,A先取12堆
25%2=1,25%3=1,25%4=1,25%6=1。所以B一定会输
A只要取完宝石后给B留4的倍数就能赢,留下4的倍数,B就没有办法取完。而A每次都可以按照B取的数量来修正,保证每次留给B的是4的倍数。到最后B没有办法一次取完4个,而且必须要取,剩下的A取完就赢了
用13+12=25,25/3余数为1,也就是说最终会多出一轮,只有a先选,才能拿到
2、从数字集合{1,2,3,4,… ,20}中选出3个数字的子集,如果不允许两个相连的数字出现在同一集合中,那么能够形成多少个这种子集?
"不邻问题"插空法,即在解决对于某几个元素要求不相邻的问题时,先将其它元素排好,再将指定的不相邻的元素插入已排好元素的间隙或两端位置,从而将问题解决的策略。
:找空格插空,算头又算尾
答:插空法,链接:
因为一共20本书,且不相邻,可以理解为把3本书插到17本书的间隔处,即加头尾的18个空格里,有多少种组合。如下:
1_2_3_4_5_6_7_8_9_10_11_12_13_14_15_16_17
(间隔数为 n + 1 = 17 + 1 = 18)
所以从上述18个位置中选择3个位置放书,即有 C(18, 3)=816 种。
3、将4个不一样的球随机放入5个杯子中,则杯子中球的最大个数为3的概率是?
答:C4,3 * C4,1 * C5C1 / (5^4) = 16/125
4、已知y=f(x)的均差f(x0, x1, x2)=14/3,f(x1, x2, x3)=15/3,f(x2, x3,x4)=91/15,f(x0, x2, x3)=18/3,那么均差f(x4, x2, x3)=( )
答:91/15(18/3、14/3、15/3、91/15)
均差f(x4, x2, x3)=f(x2, x3,x4)=91/15,(对称性)差商 与插值节点的顺序无关
5、一个快递公司对同一年龄段的员工,进行汽车,三轮车,二轮车平均送件量的比较,结果给出sig.=0.034,说明
答:按照0.05显著性水平,拒绝H0,说明三类交通工具送件量有显著差异。
6、小明在一次班干部二人竞选中,支持率为百分之五十五,而置信水平0.95以上的置信区间为百分之五十到百分之六十,请问小明未当选的可能性有可能是
答:3%
95%落在百分之五十到六十,落在百分之50以下和百分之60以上的概率分别为2.5%,所以不当选的概率(落在百分之50以下)为2.5%约等于3%
销售员需统计以下公式所示数据=SUM(SUMIF(C2:C9,{"<10","<6"})*{1,-1})
请问,该公式返回值为
答:14
C2:C9按照"<10","<6"条件分别求和,再按照1,-1求和,即23-9=14
8、SQL语句执行的顺序是
答
1.FROM
2.JOINON
3.WHERE
4.GROUP
9、随机地掷一骰子两次,则两次出现的点数之和等于8的概率为:
答:5/36,35,53,26,62,44
10、设随机变量X和Y都服从正态分布,且它们不相关,则( )
答:X与Y未必独立
错误答案:(X, Y)服从二维正态分布、X与Y一定独立、X + Y服从一维正态分布
A.只有当(X,Y) 服从二维正态分布时,X与Y不相关⇔X与Y独立,本题仅仅已知X和Y服从正态分布,因此,由它们不相关推不出X与Y一定独立,故A错误;
B.若X和Y都服从正态分布且相互独立,则(X,Y)服从二维正态分布,但题设并不知道X,Y是否独立,故B错误;
C.由A、B分析可知X与Y未必独立,故C正确;
D.需要求X与Y相互独立时,才能推出X+Y服从一维正态分布,故D错误.
11、某地区每个人的年收入是右偏的,均值为5000元,标准差为1200元。随机抽取900人并记录他们的年收入,则样本均值的分布为()
答:近似正态分布,均值为5000元,标准差为40元
 ,为标准差,n为人数
,为标准差,n为人数
当900人和某地区人数相比差距很大时可以默认前一项的值为1,于是1200/sqrt(900) = 1200 / 30 = 40
中心极限定理,样本量N只要越来越大,抽样样本n的样本均值会趋近于正态分布,并且这个正态分布以u为均值,sigma^2/n为方差。
中心极限定理: 多个独立同分布的变量之和(求个均值后肯定一样是服从的)近似服从正态分布
12、抽取30个手机用户,计算出他们通话时间的方差。要用样本方差推断总体方差,假定前提是所有用户的通话时间应服从()
答:正态分布
一个总体的方差的区间估计其前提条件是总体服从正态分布,在置信水平下的置信区间服从卡方分布
13、把黑桃、红桃、方片、梅花四种花色的扑克牌按黑桃10张、红桃9张、方片7张、梅花5张的顺序循环排列。问第2015张扑克牌是什么花色?
答:梅花
2015/31 = 65 所以最后一张应该是梅花
14、命题A:随机变量X和Y独立,命题B:随机变量X和Y不相关。A是B的______条件。
答:充分不必要
前者可推出后者,后者推不出前者
15、假定树根的高度为0,则高度为6的二叉树最多有_______个叶节点。
答:64
一棵树当中没有子结点(即度为0)的结点称为叶子结点。所以2^6=64
假定树根的高度为0,所以高度为6的二叉树其实是通常意义上的7层二叉树
16、已知一棵树具有10个节点,且度为4,那么:
答:该树的高度至多是7
树的高度:从所有叶节点开始数高度到根节点,其中的最大值;也就是从结点x向下到某个叶结点最长简单路径中边的条数。
树的深度:树根下中所有分支结点层数的最大值,递归定义。(一般以根节点深度层数为0)
4个度,说明有一个结点,连了4个子结点。那么还剩10-(4+1)=5个父结点,连在这个结点上,所以最大度是7,如图所
高度是从下往上数,深度是从上往下数,度是节点拥有的子树的个数,度为0的节点称之为叶子节点
链接:https://www.nowcoder.com/questionTerminal/6aa6013a2e9f4649b5c34fdcd52835a4
来源:牛客网
树的度为4,说明树的节点中最高度为4,树一共10个节点,最多的可能就是前面都是一个节点连着一个节点,最后一共节点连4个节点。但本题答案最多为7,貌似是将根节点的高度看做1,其实应该在题目中提一下,不然根节点高度为0,就选B了
17、对于以下关键字{55,26,33,80,70,90,6,30,40,20},增量取5的希尔排序的第一趟的结果是:
答:55,6,30,40,20,90,26,33,80,70
{55,26,33,80,70,90,6,30,40,20} 增量为5, 从55开始每隔5个距离取值分为1组,共分为5组,
分别为{55,90} {26,6}{33,30}{80,40}{70,20}
先组内排序取最小值:55,6,30,40,20,
后取剩余值:90,26,33,80,70
用13的瓷砖密铺320的地板有几种方式?
答:1278
一共可能有2,5,8,11,14,17块砖头竖着放((20-2)%3==0其余数字同理。)
#竖着放代表长度为3的边刚好接触。A6,6代表6!也等于6的阶乘
当有2块竖着放,一共有8(2+(20-2)/3=8)块转,其中6块为竖着放,2块横着。A8,8/(A6,6*A2,2)=28;
当有5块竖着放,一共有10块转,其中5块为竖着放,5块横着。A10,10/(A5,5*A5,5)=252;
当有8块竖着放,一共有12块转,其中8块为竖着放,4块横着。A12,12/(A8,8*A4,4)=495;
当有11块竖着放,一共有14块转,A14,14/(A11,11*A3,3)=364;
当有14块竖着放,一共有16块转,A16,16/(A14,14*A2,2)=120;
当有17块竖着放,一共有18块转,A18,18/(A17,17*A1,1)=18;
当有20块竖着放,结果为1;
以上加总为1278;
20、有20个人去看电影,电影票50元。其中只有10个人有50元钱,另外10个人都只有一张面值100元的纸币,电影院没有其他钞票可以找零,问有多少种找零的方法?
答:16796
卡特兰数问题C(n,2n)/(n+1)=C(10,20)/11=16796
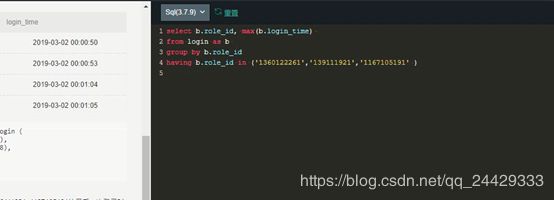
select sum(case when sat_name =‘好评’ then count(sat_name) end) / count(sat_name) as “好评率”
from a join b on a.good_id = b.good_id
where a.user_name =‘小明’
and b.bu_name = ‘母婴’
and b.brand_name =‘花王’
and a.sub_time between to_date(‘2018-1-1’,‘yyyy-mm-dd’) and to_date(‘2018-1-31’,‘yyyy-mm-dd’)
3、考拉海购始终以用户为中心,为用户提供高品质的商品,帮助用户“用更少的钱,过更好的生活”。为了满足不同用户的需求(比如新客户的要求可能跟老客户不同,流失客户需要特殊的关怀) ,请你设计一套具体的方案,合理划分不同用户,并能给出相应的建议。
针对用户类型进行划分。
1、新用户——引导性信息收集
任何电商品牌都有一套属于自己的推荐算法,但是对于新用户和新商品这种冷启动问题一般还是没有很好的解决方法。实际上,新商品有很多性能参数,可以根据相近商品进行预测,而新用户对于算法来说是一个完全空白的样本,不利于探测客户需求,所以建议在新用户注册时设计一套能够捕捉购买方向和趋势的问卷,并配合问卷选择发放一些对应的优惠券,这样一方面可以引导新用户在情愿的情况下给出真是的购买意愿,另一方面也能够在最快的时间内捕捉到该用户的一些信息,再一方面促进了用户购买商品的几率。
2、规律用户——捕捉规律行为
大部分用户的购买行为存在周期性,比如优惠周期,使用周期,系统可以根据用户在过去的购买和浏览行为探索用户购买周期,然后预测下一个购买周期,并且发送优惠信息,这样既让用户享受到了优惠,又实现了营销。
3、流失用户——捕捉细节
万事皆有原因,一个用户流失要么是在这里吃过亏,要么是觉得买不到想要的,要么是别的平台更便宜,无非这三大类原因,所以应该捕捉用户最后的浏览信息,浏览表明有购买意愿,针对这些商品基于一些优惠,吸引用户再次浏览,根据一次次吸引浏览来判断不购买原因,再对症下药。
注:要区分流失用户和规律用户,这两类行为存在很大的相似性,但是后者其实并不需要太多优惠或行为进行挽留
2019数据分析工程师笔试
单选题(20道题,40分)
-
bootstrap 是什么原理—有放回的从N个样本中抽样n个
bootstrap方法是从大小为n的原始训练数据集中随机选择n个样本点组成一个新的训练集,这个选择过程独立重复B次,然后用这B个数据集对模型统计量进行估计(如均值、方差等)。由于原始数据集的大小就是n,所以这B个新的训练集中不可避免的会存在重复的样本。
统计量的估计值定义为独立的B个训练集上的估计值的平均:
区分bootstrap、bagging、boosting和adaboost
https://blog.csdn.net/wangjian1204/article/details/50668929
bootstrap、bagging、boosting和adaboost是机器学习中几种常用的重采样方法。其中bootstrap重采样方法主要用于统计量的估计,bagging、boosting 和 adaboost方法则主要用于多个子分类器的组合。
Bootstrap 是对统计量的估计,有放回的从N个样本中抽样n个样本,独立重复B次,然后用这B 个数据集对模型统计量进行估计(如均值,方差),这个B个样本中必然会存在重复样本
Bagging (Bootstrap Aggregating),第一步采样就是使用Bootstrap Sample (Bagging是对训练样本采样) 方法是从大小为n的原始训练数据集D中随机选择n′(n′
Random Forest,结合了Bagging和Feature Selection方法,当然也使用林Bootstrap Sample方法 (不仅仅对训练样本采样,还对Feature采样)
https://www.jianshu.com/p/708dff71df3a -
用户消费表中时间格式是“年-月-日-时-分-秒”,在MySQL中获取“年-月-日”的函数是(A)
A DATE --返回日期
B GETDATE —返回日期和时间
C DAY()–1、day(date_expression) 返回date_expression中的日期值
D GETDAY()—无此函数 -
假设使用较短的时间在一个足够大的数据集上训练决策树,可以采用什么办法(C)
A 增加树的深度
B 增加学习率
C减少树的深度
D 减少树的数量
解析: 增加树的深度, 会导致所有节点不断分裂, 直到叶子节点是纯的为止. 所以, 增加深度, 会延长训练时间.决策树没有学习率参数可以调. (不像集成学习和其它有步长的学习方法)决策树只有一棵树, 不是随机森林。
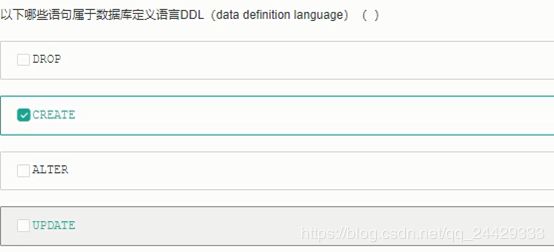
- 需要删除表user的数据,但是保留表结构且不释放空间,以下哪个语句可以实现()
A DELETE TABLE user
B REMOVE TABLE user
C DROP TABLE user
D TRUNCATE TABLE user
在SQL中,能快速删除数据表中所有记录,但保留数据表结构的语句是Truncate。
使用Truncate删除所有行,该语句总是比不带条件的DELETE语句要快,因为DELETE语句要记录对每行的删除操作,而Truncate 语句只记录整个数据页的释放。Truncate语句立即释放由该表的数据和索引占用的所有空间,所有索引的分发页也将释放。
Delete 删除 表中的行
DROP删除整个表,包括表结构和表定义
REMOVE没有这个查询定义
- 某抽卡公司出示出SSR的概率是0.1,用户画符500次,得到45个符,问在5%的显著水平下,能够认为游戏商在谎报概率吗?()
A 能
B不能
C 不确定
D 就算画符5000次,得到450个符,也不能
对于统计检验来说,这里设置的是a=0.05, Ho 假设如果计算的概率p>a大于显著水平,即是没有足够的证据去拒绝原假设,即尚不能拒绝H0, 如果p 令L代表服务器请求处理失败,A,B,C,D分别代表对应的集群处理响应。 大数定理说的是随机现象平均结果的稳定性 关于MySQL中数据类型的描述,以下错误的是(C) 以下哪些机器学习模型没有用到learning rate 学习率 作为超参数() 游戏中的武器攻击值是60, 使用宝石可以增加攻击值,如果是A有40%的概率打出暴击,攻击值增加一倍,是宝石B的话有20%的概率打出暴击,攻击值增加三倍,如果是C的话10% 攻击值增加5倍, 各个事件均为独立事件,但是多个暴击同时发生时,支取最高值, 这个数学期望是多少()–?? 40% 20% 10% 30% 过抽样:过抽样也叫做上采样(over-sampling).这种方法通过增加分类中少数样本的数量来实现样本均衡。最直接的方法是简单复制少数样本形成多条记录。比如正负比例为1:10,那么我们可以将正例复制9遍来达到正负比例1:1。但是这种方法的缺点就是如果样本特征少而可能导致过拟合的问题;经过改进的过抽样方法通过在少数类中加入随机噪声、干扰数据或通过一定规则产生新的合成样本,例如SMOTE算法。 2,通过正负样本的惩罚权重解决样本不均衡。 SQL 中 语句正确的执行顺序是 RNN 在特定的神经元给定任意输入,得到的输出是-0.001. 那么RNN中隐藏层使用的激活函数可能是() 在含有一个或者两个均值的假设检验中要使用()??? 不确定 下面说法错误的是() C???? One vs rest 分类法 对于n 个类别的分类任务,需要训练多少模型—n 现在需要查询包括‘_’的数据,以下SQL 不能实现的是: 多选题(10道,30分) 假如出现以下哪种情况,可以表明训练RNN模型过程中出现了梯度爆炸? 关于SQL 的优化,以下说法正确的是() 关于线性回归的描述,以下正确的是() 皮尔森系数 编程题(全部是SQL)
A 集群A、
B 集群B
C 集群C
D 集群D
则有P(A)=10%,P(B)=20%,P©=30%,P(D)=40%
P(L|A)=10%,P(L|B)=7%,P(L|C)=1%,P(L|D)=0.1%
题目要求P(X|L),知识点:全概率公式、贝叶斯公式;对于4个集群而言,分母P(失败)是恒定的,因此只需比较分子P(失败|集群=i)*P(集群=i)的大小。
X可取A,B,C,D,求其中的最大值。
根据贝叶斯概率公式
P(A|L)P(L)=P(L|A)P(A)=10% * 10%=0.01
P(B|L)P(L)=P(L|B)P(B)=20% *7%=0.014
P(C|L)P(L)=P(L|C)P©=0.003
P(D|L)P(L)=P(L|D)P(D)=0.0004
其中,P(L)虽然未知,但不用计算,即可比较大小,得P(B|L)最大
所以选B
A 大数定理和中心极限定理都是用来描述 独立同分布的随机变量的和的渐进表现
B 它们描述的是在不同收敛速率之下的表现,大数定理的前提条件强一点
C 利用大数定理可以用样本均值估计总体分布的均值
D 中心极限定理描述的是某种形式的随机变量之和的分布
http://www.360doc.com/content/17/0207/09/9200790_627187280.shtml
中心极限定理 论证随机变量的极限分布是正态分布
大数定理比中心极限定理宽松,中心极限条件强,结论更强
A VARCHAR 用于描述可变长度的非二进制字符串
B DATETIME 和TIMESTAMP 是相同的数据类型,可以相互替换 √
C 以“hh:mm:ss”格式存储时间值的是DATETIME 数据类型 ×是TIME
D TINYINT属性只适合数字类型的数据
A 随机森林
B Adaboost
C Gradient Boosting
D lightGBM
决策树没有参数可以调节
只要使用了梯度下降法就会有学习率
A 129.38
B139.68
C152.18
D 145.98
120 240 360
E(x)= 1200.4+ 2400.2+360*0.1==
A 对训练集的负样本进行欠采样
B 直接基于原始数据集进行训练 在预测的时候改变阈值
C 对训练集的正负比例进行升采样
D 对正例进行升采样
2,欠抽样:欠抽样也叫做下采样(under-sampling),这种方法通过减少分类中多数分类的样本数量来实现样本均衡,最直接的方法就是随机的去掉一些多数类样本来减小多数类的规模,缺点是会丢失多数类样本中的一些重要信息。
总而言之,过抽样和欠抽样更适合于大数据分布不均衡的情况,尤其是第一种(过抽样)应用更加广泛。
过采样(英语:Oversampling)是指以远远高于信号带宽两倍或其最高频率对其进行采样的过程。
3,通过组合集成方法解决样本不均衡。
4,通过特征选择解决样本不均衡
From—where—group by —having –select----order by –limit
A ReLu(0,x)
B Tanh (-1,1)
C Sigmoid–(0,1)
D 其他都不是
????
A 卡方检验
B t 变量
C F变量
D z 变量
A 零假设提出一个参数是否等于某个特殊值的问题
B p值越小,拒绝零假设的理由就越充分
C p 值和零假设的对错的概率有关
D p值描述的是在总体的许多样本中,某一类数据出现的经常程度
16. 贝叶斯分类利用以下哪种概率计算( 后验概率)
利用先验概率计算后概率 应该是先验概率
不可以的是修改主键,以及插入一个和主键学号一样的信息
A 梯度模型快速变大
B 模型权重为NAN
C 每个节点和层的误差梯度值持续超过1.0
D 损失函数持续减少
E梯度模型以指数形式衰减
A select 子句 中尽量避免使用 *, 尽量列出需要查询的字段
B 大小表连接是,把大表写入内存,再拼接小表
C KEY键NULL值较多时,把 NULL赋值为特定字符串
D 进行去重时,使用DISTINCT比order by 效率更高
A 基本假设包括随机干扰项是均值为0,方差为1的标准正态分布
B 基本假设是包括随机干扰是均值为0的同方差正态分布
C 在违背基本假设是,普通最小二乘法不是是最佳线性无偏估计量
D 在违背基本假设
模型不再可以估计

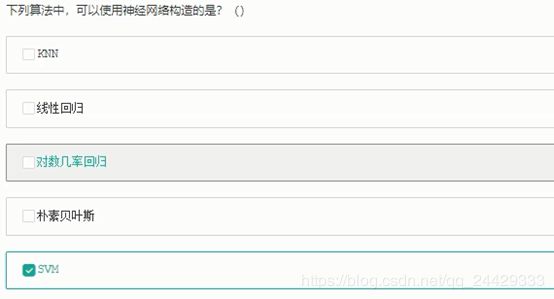

B C D

选AD

是A D