踩坑记录: Pytorch框架下--- 从零使用卷积神经网络实现人脸面部表情识别 (基于连续维度)
之前一直在自学深度神经网络的知识,在跟着书本一步一步走的时候,感觉每一个思路,每一句代码都特别容易,实现思路清晰明了,实验代码简单易懂。但当我真正课题需要用到的时候,想跳出书本的框架,自行实现并通透其中的过程时,一上手真的是泪流满面,书本上的两三句话可能在你实验中会遇到各种各样头大的问题。。。
不过还好,自己从头到尾实现一遍,理解的深刻程度也是看书不能比的,下面记录一下我之前的笔记,欢迎交流指导
基于深度学习的表情识别
废话不多说。出发点呢,是因为想自行实现一下,看别人代码总是看得吃力,自己写一遍就印象深刻了,下面让我们来从0开始吧,这次真的是从0开始,所以前期的准备工作都要做一遍。我的实验呢是基于连续维度下的面部表情识别,注意是连续维度下(arousal-valence维度),和以往的基于分类的面部表情识别(七种或N种离散表情)在网络框架上可能有些不同,然后具体的流程可能有:
1. 数据集准备,处理
2. 网络框架自定义
3. 定义训练、测试函数
4. 在笔记本上只要代码可以跑通,就搬移到带GPU的服务器上,将代码改成在GPU上运行
先一个一个分析,最终完整的测试代码,放在文章最后。
数据集、样本选择
首先,实验基于AffectNet数据库,标注包括特征点、离散表情类、AU单元、A/V标注值等等。 这个数据库的话感觉是表情识别数据库中样本量最广,表情类别最多的数据库了吧,图像都是在网上爬的,, 和电影桥段那种数据库可不一样,感觉基于这个数据库比其他的都有挑战性。 因为是小测验,我决定选取就10000个样本吧,然后基于连续维度应该是针对arousal维度和valence维度,但这两个描述维度,涉及到要给网络定义两个不同的损失函数去分别进行学习,所以我只用1个arousal标签,省时省力。
在arousal标签值 -1 到 1之间,我将其划分为10个区间,每个区间选取1000个样本。关于对数据记得划分,以及如何选取样本,可以参考我很早之前这篇文章Affectnet数据集 按标签值对图像进行分类,然后将分成的10个CSV文件合并,合并代码很简单,可以在关于划分数据库时及处理CSV文件的问题研究记录描述这篇文章找到。
最终存储的CSV文件,包含10000个样本的地址目录,以及其arousal标注,像这样就搞定了,方便之后的实验进行:

网络框架定义
因为我的网络输出输出是连续值,不是分类值,所以网络的最终输出层应该选择线性回归层,让它输出连续的预测值。**同时这里要注意:**损失函数要采用回归类的损失函数(如MSEloss等)。
然后网络框架定义,随便定义了一个小网络(仅供参考,这是随便写的,为了保证识别准确率后期自己进行了修改),如下:
class FaceCNN(nn.Module):
# 初始化网络结构
def __init__(self):
super(FaceCNN, self).__init__()
# 第一次卷积、池化
self.conv1 = nn.Sequential(
# 输入通道数in_channels,输出通道数(即卷积核的通道数)out_channels,卷积核大小kernel_size,步长stride,对称填0行列数padding
# input:(bitch_size, 1, 48, 48), output:(bitch_size, 64, 48, 48), (48-3+2*1)/1+1 = 48
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1), # 卷积层
nn.BatchNorm2d(num_features=64), # 归一化
nn.ReLU(inplace=True), # 激活函数
# output(bitch_size, 64, 24, 24)
nn.MaxPool2d(kernel_size=2, stride=2), # 最大值池化
)
# 第二次卷积、池化
self.conv2 = nn.Sequential(
# input:(bitch_size, 64, 24, 24), output:(bitch_size, 128, 24, 24), (24-3+2*1)/1+1 = 24
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(inplace=True),
# output:(bitch_size, 128, 12 ,12)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 第三次卷积、池化
self.conv3 = nn.Sequential(
# input:(bitch_size, 128, 12, 12), output:(bitch_size, 256, 12, 12), (12-3+2*1)/1+1 = 12
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(inplace=True),
# output:(bitch_size, 256, 6 ,6)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 全连接层
self.fc = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=256*6*6, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=1024),
nn.ReLU(inplace=True),
nn.Linear(in_features=1024, out_features=256),
nn.ReLU(inplace=True),
nn.Linear(in_features=256, out_features=1),
)
# 前向传播
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
# 数据扁平化
x = x.view(x.shape[0], -1)
y = self.fc(x)
return y
最终的全连接层输出未对其进行分类操作,且仅输出一个连续的值。
定义训练、测试函数
定义训练函数:
def train(train_dataset, batch_size, epochs, learning_rate, wt_decay):
# 载入数据并分割batch
train_loader = data.DataLoader(train_dataset, batch_size)
#print(train_loader)
# 构建模型
model = FaceCNN()
# 损失函数
loss_function = nn.MSELoss()
# 优化器
optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=wt_decay)
# 学习率衰减
# scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.8)
# 逐轮训练
for epoch in range(epochs):
# 记录损失值
loss_rate = 0
# scheduler.step() # 学习率衰减
model.train() # 模型训练
for images, labels in train_loader:
arr1 = np.array(labels, dtype=float)
labels = torch.tensor(arr1, dtype=torch.float32)
# print(images)
# print(labels)
# 梯度清零
optimizer.zero_grad()
# 前向传播
output = model.forward(images)
# print(output)
# print(labels)
# 误差计算
loss_rate = loss_function(output, labels)
# 误差的反向传播
loss_rate.backward()
# 更新参数
optimizer.step()
# 打印每轮的损失
print('After {} epochs , the loss_rate is : '.format(epoch+1), loss_rate.item())
# if epoch % 5 == 0:
# model.eval() # 模型评估
# acc_train = validate(model, train_dataset, batch_size)
# print('After {} epochs , the acc_train is : '.format(epoch+1), acc_train)
return model
def main():
# 数据集实例化(创建数据集)
train_dataset = DatasetLoader(root='D:\\zhang\\zhangT')
#val_dataset = FaceDataset(root='E:\\WSD\\HW3\\FaceData\\val')
# 超参数可自行指定
model = train(train_dataset, batch_size=128, epochs=100, learning_rate=0.1, wt_decay=0)
# 保存模型
torch.save(model, 'model_net1.pkl')
def validate(model, test_dataset, batch_size):
#载入测试数据
test_loader = data.DataLoader(test_dataset, batch_size)
eval_loss = 0
eval_acc = 0
#for data in test_loader:
for images, labels in test_loader:
y_red = model.forward(images)
y_pred = pred.data.numpy()
labels = labels.data.numpy()
yg = []
yp = []
# testy = testlabel.tolist()
# y_pred = y_pred.tolist()
for i in range(0, len(labels)):
# print(testlabel[i])
yg.append(float(labels[i]))
yp.append(float(y_pred[i]))
rm = []
for i in range(0, len(yp)):
r = (yp[i] - yg[i]) ** 2
rm.append(r)
ar = np.sum(rm)
rmse = math.sqrt(ar / len(yp))
return rmse
定义主函数:
def main():
# 数据集实例化(创建数据集)
train_dataset = DatasetLoader(root='/home/wangyuzhuo/zhanglongtao/affectnet/training')
test_dataset = DatasetLoader(root='/home/wangyuzhuo/zhanglongtao/affectnet/testing')
#val_dataset = FaceDataset(root='E:\\WSD\\HW3\\FaceData\\val')
# 超参数可自行指定
model = train(train_dataset, batch_size=64, epochs=60, learning_rate=0.001)
# 保存模型
torch.save(model, 'model_net1.pkl')
model.eval() # 模型评估
rmse = validate(model, test_dataset, batch_size=64)
print("rmse: ", rmse)
if __name__ == '__main__':
main()
最终这样一个小的表情识别的网络就定义好了,我刚开始的问题主要出在不知道常用的离散表情的网络与连续维度下情感网络之间的具体区别,查找了很多资料代码,基本常实现的都是离散类的表情,所以自己测试了一下。另外,若要加上valence维度,可以考虑重新定义一个损失函数,对arousal、valence维度分别进行学习,然后输出层的2个维度,分别对应自己的损失函数,这样就能解决连续维度的问题了。或者可以对valence维度同样进行上述操作,定义两个网络分别学习arousal和valence也可以解决问题,但这样的方式显得有些臃肿。
补充:
以上只给出了样例,对于DatasetLoader类,要重写一遍,对应自己的训练、测试数据。
同时,因为服务器没有pytorch,所以关于linux服务器安装pytorch以及依赖,还有支持GPU等一系列问题,我总结在了这篇博客:关于服务器使用pip 安装 pytorch安装问题 python3.5 + cuda9.0 + cudnn7.3.1
最后是将代码搬移到GPU,这里需要注意的是,搬移到GPU需要注意:
模型、数据、损失函数都要搬移到GPU,对于pytorch就是:
model = model.cuda()
loss_function = loss_function.cuda()
#训练函数中;
images = Variable(images).cuda()
labels = Variable(labels).cuda()
这个我为了图简便这样定义了,若后期训练工作比较多,可能用的机子不仅仅有CPU,GPU等,可以将以上板块定义一个类,在类中区分if else判断一下 是否可用cuda然后分别定义不同的载入方式。
最后若是自己的测试指标于本文不同(或是测试代码有问题),可以在主函数中只运行训练函数,执行训练函数之后,训练好的模型会被保存,之后我们无论是采用那种方式测试,可以直接载入模型即可。
最后,贴一下我载入训练好的模型,只进行测试的时候,遇到的一些问题:
注:
这部分当时是记在word里了,可能有些无头绪,但基本上能踩的坑我全部踩了一遍,若是遇到什么问题,可以参考下面的出错原因及解决办法:
错误1:
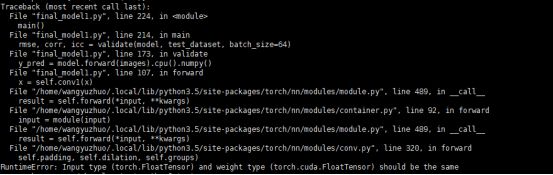
错误原因:这是因为在测试的时候,测试用例的输入并未转化为cuda的数据类型,所以才会报错。
将测试代码中的输入改为: images = Variable(images).cuda()
因为这是训练后出错了,所以,我必须重新加载模型,然后继续测试:
加载模型,并训练,这里粘贴上之前的Dataloader函数,导入的库等等,然后主代码改成这样:
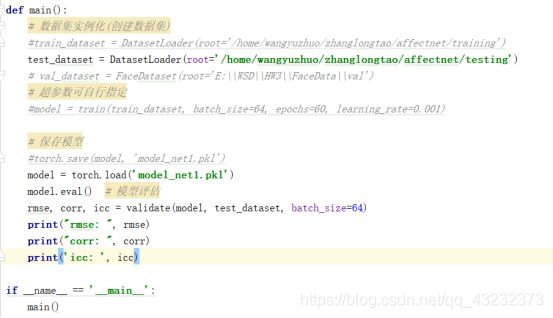
然后又出错了,发现提示的是这个
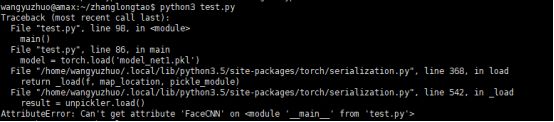
通过阅读官方文档,发现是因为之前训练的时候,定义了一个FaceCNN的类,但是在这测试代码中,我没有写这个类,导致找不到这个类出错了。于是,把FaceCNN类定义的代码,粘贴过来。或者从train程序中 import一下(就是这部分):
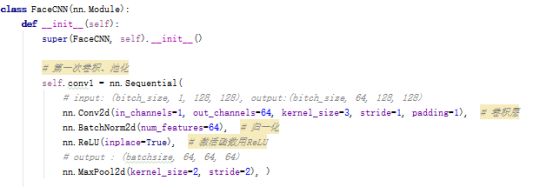
然后继续运行,发现又又又报错:
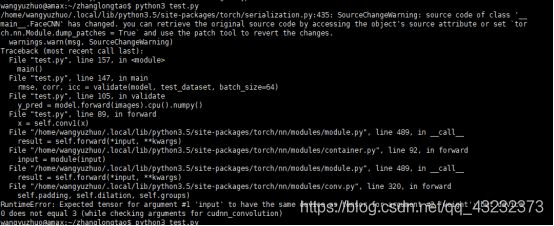
这次又是因为什么呢,这是因为啊,我训练模型的时候指定了 GPU3:
![]()
但是,测试的时候,没指定,GPU不同导致的报错,于是又赶快把这句代码加到程序的最前端。
满心欢喜以为搞定了,结果再次不出意外的出现了问题:
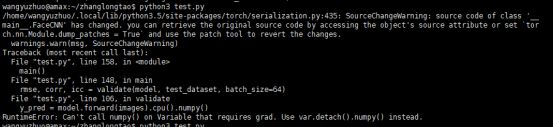
这里写着不让使用numpy(),让你换成detach().numpy(),那就换吧,换完了之后,终于好了。最后贴一下我最终测试用的经过修改的完整代码吧(已训练好模型,直接载入进行测试(模型时基于CUDA训练的,测试时要将模型输出转化为numpy类型)):
import torch
import numpy as np
import os, math
import cv2 as cv
import pandas as pd
from torch.autograd import Variable
import torch.optim as optim
from torch import nn
from torch.utils import data
torch.cuda.set_device(3)
class DatasetLoader(data.Dataset):
def __init__(self, root):
super(DatasetLoader, self).__init__()
self.root = root
df_path = pd.read_csv(root + '/csv/arousal.csv', header=None, usecols=[0])
df_label = pd.read_csv(root + '/csv/arousal.csv', header=None, usecols=[1])
self.path = np.array(df_path)[:, 0] # numpy.array df_path[0] str
self.label = np.array(df_label)[:, 0] # numpy.array de_label[0] float64
def __getitem__(self, item):
path = self.root + '/data/' + self.path[item]
image = cv.imread(path)
img = cv.resize(image, (128, 128)) #将图像大小重新改了下
# 转化为灰度图
img_gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
img_normalized = img_gray.reshape(1, 128, 128) / 255.0 # 标准化数据并reshape一下
img_tensor = torch.from_numpy(img_normalized) # 将python中的numpy数据类型转化为pytorch中的tensor数据类型
img_tensor = img_tensor.type('torch.FloatTensor') # 指定为'torch.FloatTensor'型,否则送进模型后会因数据类型不匹配而报错
label = self.label[item]
return img_tensor, label
def __len__(self):
return self.path.shape[0]
class FaceCNN(nn.Module):
def __init__(self):
super(FaceCNN, self).__init__()
# 第一次卷积、池化
self.conv1 = nn.Sequential(
# input: (bitch_size, 1, 128, 128), output:(bitch_size, 64, 128, 128)
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1), # 卷积层
nn.BatchNorm2d(num_features=64), # 归一化
nn.ReLU(inplace=True), # 激活函数用ReLU
# output : (batchsize, 64, 64, 64)
nn.MaxPool2d(kernel_size=2, stride=2), )
# 第二次卷积、池化
self.conv2 = nn.Sequential(
# input: (bitch_size, 64, 64, 64), output:(bitch_size, 128,64,64)
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(inplace=True),
# output:(bitch_size, 128, 32,32)
nn.MaxPool2d(kernel_size=2, stride=2), )
# 第三次卷积、池化
self.conv3 = nn.Sequential(
# input:(bitch_size, 128, 32, 32), output:(bitch_size, 256, 32, 32)
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(inplace=True),
# output:(bitch_size, 256, 16 ,16)
nn.MaxPool2d(kernel_size=2, stride=2), )
self.conv4 = nn.Sequential(
# input:(bitch_size, 256, 16, 16), output:(bitch_size, 512, 16, 16)
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(inplace=True),
# output:(bitch_size, 512, 8 ,8)
nn.MaxPool2d(kernel_size=2, stride=2), )
self.fc = nn.Sequential(
nn.Linear(512 * 8 * 8, 4096),
nn.ReLU(True),
nn.Dropout(p=0.3),
nn.Linear(4096, 1024),
nn.ReLU(True),
nn.Dropout(p=0.3),
nn.Linear(in_features=1024, out_features=1), )
self.apply(initialize_weights)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
# 数据扁平化
x = x.view(x.shape[0], -1)
y = self.fc(x)
return y
def validate(model, test_dataset, batch_size):
#载入测试数据
test_loader = data.DataLoader(test_dataset, batch_size)
#for data in test_loader:
for images, labels in test_loader:
images = Variable(images).cuda()
y_pred = model.forward(images).cpu()
y_pred = y_pred.detach().numpy()
labels = labels.data.numpy()
yg = []
yp = []
# testy = testlabel.tolist()
# y_pred = y_pred.tolist()
for i in range(0, len(labels)):
# print(testlabel[i])
yg.append(labels[i])
yp.append(y_pred[i])
rm = []
for i in range(0, len(yp)):
r = (yp[i] - yg[i]) ** 2
rm.append(r)
ar = np.sum(rm)
rmse = math.sqrt(ar / len(yp))
return rmse
def main():
# 数据集实例化(创建数据集)
#train_dataset = DatasetLoader(root='/home/wangyuzhuo/zhanglongtao/affectnet/training')
test_dataset = DatasetLoader(root='/home/wangyuzhuo/zhanglongtao/affectnet/testing')
# val_dataset = FaceDataset(root='E:\\WSD\\HW3\\FaceData\\val')
# 超参数可自行指定
#model = train(train_dataset, batch_size=64, epochs=60, learning_rate=0.001)
# 保存模型
#torch.save(model, 'model_net1.pkl')
model = torch.load('model_net1.pkl')
model.eval() # 模型评估
rmse = validate(model, test_dataset, batch_size=64)
print("rmse: ", rmse)
if __name__ == '__main__':
main()