CenterNet姿势估计decode部分代码解读
代码链接:https://github.com/xingyizhou/CenterNet/blob/1085662179604dd4c2667e3159db5445a5f4ac76/src/lib/models/decode.py#L497
代码位置:src/lib/models/decode.py
代码注释
def multi_pose_decode(heat, wh, kps, reg=None, hm_hp=None, hp_offset=None, K=100):
'''
:param heat: keypoint heatmap 定位目标中心点的heatmap
:param wh: object size 确定矩形宽高
:param kps: joint locations 相对于目标中心的各关键点偏移
:param reg: local offset 包围框的偏移补偿
:param hm_hp: joint heatmap 一般的关键点估计heatmap
:param hp_offset: joint offset 关键点估计的偏移
:param K: top-K
:return:
'''
batch, cat, height, width = heat.size() # cat类别数
num_joints = kps.shape[1] // 2 # 需要估计的关键点数是通道数的一半
# heat = torch.sigmoid(heat)
# perform nms on heatmaps
heat = _nms(heat) # 通过3*3最大池化找出局部最大值
# 找到局部最大值里的top-K,返回[得分, 索引, 类别, Y值list, X值list]
scores, inds, clses, ys, xs = _topk(heat, K=K)
# 根据top-K的索引查找并收集对应的关键点偏移量
kps = _transpose_and_gather_feat(kps, inds)
kps = kps.view(batch, K, num_joints * 2)
# 将关键点偏移量加上中心点坐标,得到相对于图像原点的关键点坐标
kps[..., ::2] += xs.view(batch, K, 1).expand(batch, K, num_joints)
kps[..., 1::2] += ys.view(batch, K, 1).expand(batch, K, num_joints)
if reg is not None:
# 如果用了关键点量化误差补偿,则解码并加到先前的结果上
reg = _transpose_and_gather_feat(reg, inds)
reg = reg.view(batch, K, 2)
xs = xs.view(batch, K, 1) + reg[:, :, 0:1]
ys = ys.view(batch, K, 1) + reg[:, :, 1:2]
else:
# 如果没有用该分支,则都加0.5,减少量化误差
xs = xs.view(batch, K, 1) + 0.5
ys = ys.view(batch, K, 1) + 0.5
# 查找对应的包围框宽高信息
wh = _transpose_and_gather_feat(wh, inds)
wh = wh.view(batch, K, 2)
clses = clses.view(batch, K, 1).float()
scores = scores.view(batch, K, 1)
# 根据中心点坐标和包围框宽高计算xmin, ymin, xmax, ymax
bboxes = torch.cat([xs - wh[..., 0:1] / 2,
ys - wh[..., 1:2] / 2,
xs + wh[..., 0:1] / 2,
ys + wh[..., 1:2] / 2], dim=2)
# 一般的关键点估计分支
if hm_hp is not None:
hm_hp = _nms(hm_hp) # 通过3*3最大池化找极值
thresh = 0.1
# kps原shape[b x K x 2N] => [b * N * K * 2]
kps = kps.view(batch, K, num_joints, 2).permute(
0, 2, 1, 3).contiguous() # b x J x K x 2
# 添加一维[b * N * K * K * 2]
reg_kps = kps.unsqueeze(3).expand(batch, num_joints, K, K, 2)
# 对每个channel取top-K,即取到各种类型关键点的top-K
hm_score, hm_inds, hm_ys, hm_xs = _topk_channel(hm_hp, K=K) # b x J x K
# 如果起用了关键点分支的偏移,则对关键点坐标进行校正
if hp_offset is not None:
hp_offset = _transpose_and_gather_feat(
hp_offset, hm_inds.view(batch, -1))
hp_offset = hp_offset.view(batch, num_joints, K, 2)
hm_xs = hm_xs + hp_offset[:, :, :, 0]
hm_ys = hm_ys + hp_offset[:, :, :, 1]
else:
hm_xs = hm_xs + 0.5
hm_ys = hm_ys + 0.5
# 去掉小于阈值的
mask = (hm_score > thresh).float()
hm_score = (1 - mask) * -1 + mask * hm_score
hm_ys = (1 - mask) * (-10000) + mask * hm_ys
hm_xs = (1 - mask) * (-10000) + mask * hm_xs
# 使用一般的关键点估计网络预测出的关键点
hm_kps = torch.stack([hm_xs, hm_ys], dim=-1).unsqueeze(
2).expand(batch, num_joints, K, K, 2)
# 全排列计算距离
dist = (((reg_kps - hm_kps) ** 2).sum(dim=4) ** 0.5)
min_dist, min_ind = dist.min(dim=3) # b x J x K
hm_score = hm_score.gather(2, min_ind).unsqueeze(-1) # b x J x K x 1
min_dist = min_dist.unsqueeze(-1)
min_ind = min_ind.view(batch, num_joints, K, 1, 1).expand(
batch, num_joints, K, 1, 2)
hm_kps = hm_kps.gather(3, min_ind)
hm_kps = hm_kps.view(batch, num_joints, K, 2)
l = bboxes[:, :, 0].view(batch, 1, K, 1).expand(batch, num_joints, K, 1)
t = bboxes[:, :, 1].view(batch, 1, K, 1).expand(batch, num_joints, K, 1)
r = bboxes[:, :, 2].view(batch, 1, K, 1).expand(batch, num_joints, K, 1)
b = bboxes[:, :, 3].view(batch, 1, K, 1).expand(batch, num_joints, K, 1)
# 根据以下逻辑挑选在一般关键点估计分支输出上最终可以作为关键点refine结果的点(下面代码是剔除的逻辑):
# 1. 落在包围框内
# 2. 得分高于阈值
# 3. 与基于中心点回归出的对应关键点距离不能超过包围框尺寸的.3倍
mask = (hm_kps[..., 0:1] < l) + (hm_kps[..., 0:1] > r) + \
(hm_kps[..., 1:2] < t) + (hm_kps[..., 1:2] > b) + \
(hm_score < thresh) + (min_dist > (torch.max(b - t, r - l) * 0.3))
mask = (mask > 0).float().expand(batch, num_joints, K, 2)
# 使用匹配成功的refine关键点 + 其余的基于中心点回归出的关键点
kps = (1 - mask) * hm_kps + mask * kps
kps = kps.permute(0, 2, 1, 3).contiguous().view(
batch, K, num_joints * 2)
detections = torch.cat([bboxes, scores, kps, clses], dim=2)
return detections思考
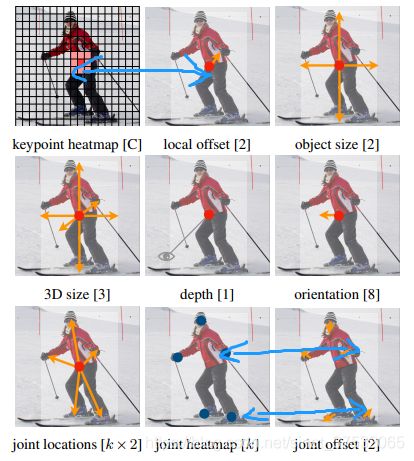
关键点的refine思想,和center point的refine思想相同。都是通过预测一个尺寸同对应heatmap的通道数为2的feature map,来得到heatmap上不同位置处,对应的X/Y方向上的offset。