pytorch + visdom 处理cifar10图像分类
运行环境
系统:win10
cpu:i7-6700HQ
gpu:gtx965m
python : 3.6
pytorch :0.3
数据集使用
Cifar-10 由60000张32*32的 RGB 彩色图片构成,共10个分类。50000张训练,10000张测试(交叉验证)。这个数据集最大的特点在于将识别迁移到了普适物体,而且应用于多分类。
数据下载,使用pytorch 可以自动下载,但是由于下载速度很龟,还是去官网下吧,建议迅雷,挺快的,链接在这。
数据下载完成后解压,在project根目录创建data文件夹,把解压文件放入即可。

数据处理:
transform_train = transforms.Compose(
# 图像翻转
[transforms.RandomHorizontalFlip(),
# 数据张量化 (0,255) >> (0,1)
transforms.ToTensor(),
# 数据正态分布 (0,1) >> (-1,1)
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
transform_test = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 加载数据靠 train 做以区分 训练集和测试集
train_dataset = datasets.CIFAR10('./data', train=True, transform=transform_train)
test_dataset = datasets.CIFAR10('./data', train=False, transform=transform_test)
#加载数据,并分批
train_loader = DataLoader(train_dataset, BATCH_SIZE, True)
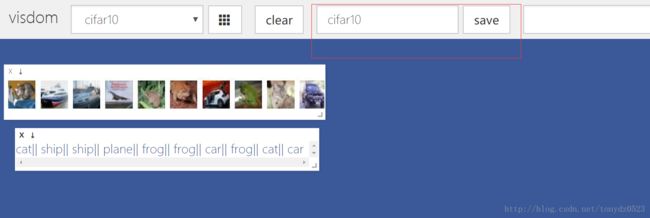
test_loader = DataLoader(test_dataset, BATCH_SIZE, False)可视化部分数据看看:
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
dataiter = iter(test_loader)
image, label = dataiter.next()
# 可视化visualize
image = viz.images(image[:10]/2+0.5, nrow=10, padding=3, env='cifar10')
text = viz.text('||'.join('%6s' % classes[label[j]] for j in range(10)))
每张图 32x32 ,很糊。
创建 cnn
创建network,用了两层卷积层-池化层 :
class CNN(nn.Module):
def __init__(self, in_dim, n_class):
super(CNN, self).__init__()
# 卷积部分
self.cnn = nn.Sequential(
nn.Conv2d(in_dim, 16, 5, 1, 2), # (32,32)
nn.ReLU(True),
nn.MaxPool2d(2), # (32,32) >> (16,16)
nn.ReLU(True),
nn.Conv2d(16, 32, 3, 1, 1),
nn.ReLU(True),
nn.MaxPool2d(2), # (16,16) >> (8,8)
)
# linear 部分
self.fc = nn.Sequential(
nn.Linear(32*8*8, 120),
nn.ReLU(True),
nn.Linear(120, 50),
nn.ReLU(True),
nn.Linear(50, n_class),
)
def forward(self, x):
out = self.cnn(x)
out = self.fc(out.view(-1, 32*8*8)) # 通过 view改变out形态
return out
# 因为是彩色图片 channel 为3 输入3 ,10分类 输出10
net = CNN(3, 10)loss ,优化函数:
# 交叉熵
loss_f = nn.CrossEntropyLoss()
# SGD加动量加快优化
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9)
# learning-rate 变化函数
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)训练前准备,可视化需要记录一些运行过程产生的数据值,训练时间记录,net最佳状态留存:
# 隔多少个batch输出数据
tr_num = len(train_dataset)/BATCH_SIZE/5
ts_num = len(test_dataset)/BATCH_SIZE/5
# 开始时间
start_time = time.time()
# visdom 创建 line 窗口
line = viz.line(Y=np.arange(10), env="cifar10")
# 记录数据的一些状态
tr_loss, ts_loss, tr_acc, ts_acc, step = [], [], [], [], []
# 记录net最佳状态
best_acc = 0.
best_state = net.state_dict()训练部分代码,10个epoch,每个batch 20个数据 初始learning-rate 0.005:
for epoch in range(EPOCHS):
# 检测运行中loss ,acc 变化
running_loss, running_acc = 0.0, 0.
scheduler.step()
# 训练环境设定
net.train()
for i, (img, label) in enumerate(train_loader, 1):
if gpu_status:
img, label = img.cuda(), label.cuda()
img, label = Variable(img), Variable(label)
out = net(img)
loss = loss_f(out, label)
pred = torch.max(out, 1)[1]
running_acc += sum(pred==label).data[0]
running_loss += loss.data[0]*len(label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 数据输出,观察运行状态
if i % tr_num == 0:
print("TRAIN : [{}/{}] | loss: {:.4f} | r_acc: {:.4f} ".format(epoch+1, EPOCHS, running_loss/(i*BATCH_SIZE),
running_acc/(i*BATCH_SIZE)))
# 训练loss,acc 可视化数据收集
tr_loss.append(running_loss/(i*BATCH_SIZE))
tr_acc.append(running_acc/(i*BATCH_SIZE))
为了,更好观察训练情况,每个epoch ,test一下:
net.eval()
eval_loss, eval_acc = 0., 0.
for i, (img, label) in enumerate(test_loader, 1):
if gpu_status:
img, label = img.cuda(), label.cuda()
# 因为是测试集 volatile1 不影响训练状态
img, label = Variable(img, volatile=True), Variable(label, volatile=True)
out = net(img)
loss = loss_f(out, label)
pred = torch.max(out, 1)[1]
eval_acc += sum(pred == label).data[0]
eval_loss += loss.data[0]*len(label)
if i % ts_num == 0:
print("test : [{}/{}] | loss: {:.4f} | r_acc: {:.4f} ".format(epoch + 1, EPOCHS,
eval_loss / (i*BATCH_SIZE),
eval_acc / (i*BATCH_SIZE)))
ts_loss.append(eval_loss / (i*BATCH_SIZE))
ts_acc.append(eval_acc / (i*BATCH_SIZE))
# visualize
viz.line(Y=np.column_stack((np.array(tr_loss), np.array(tr_acc), np.array(ts_loss), np.array(ts_acc))),
win=line,
opts=dict(legend=["tr_loss", "tr_acc", "ts_loss", "ts_acc"],
title="cafar10"),
env="cifar10")
# 保存训练最佳状态
if eval_acc / (len(test_dataset)) > best_acc:
best_acc = eval_acc / (len(test_dataset))
best_state = net.state_dict()
训练&优化
接下来开始训练,数据可视观察要用到 visdom ,开启visdom , cmd输入:
python -m visdom.server查看在浏览器: http://localhost:8097/
创建cifar 10 env
运行项目:
TRAIN : [10/10] | loss: 0.4257 | r_acc: 0.8526
TRAIN : [10/10] | loss: 0.4270 | r_acc: 0.8516
TRAIN : [10/10] | loss: 0.4383 | r_acc: 0.8522
test : [10/10] | loss: 0.7466 | r_acc: 0.7485
test : [10/10] | loss: 0.8148 | r_acc: 0.7415 10个 epoch 测试准确率 0.75 ,由图可见第5个epoch开始出现过拟合:
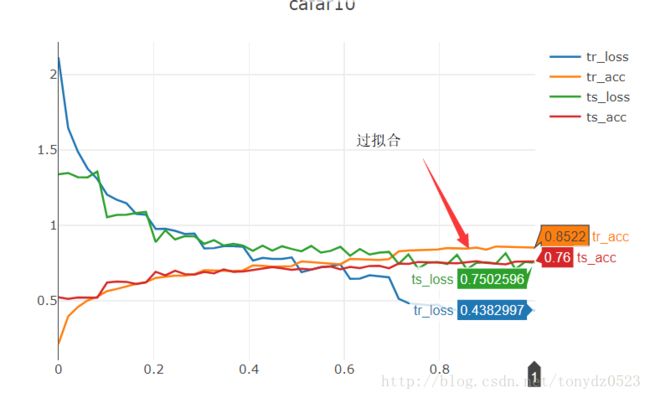
为了抑制过拟合出现,导致训练进入误区,我们加入归一化,对batch normalize , 修改net如下:
class CNN(nn.Module):
def __init__(self, in_dim, n_class):
super(CNN, self).__init__()
# 卷积部分
self.cnn = nn.Sequential(
nn.BatchNorm2d(in_dim),
nn.ReLU(True),
nn.Conv2d(in_dim, 16, 5, 1, 2), # (32,32)
nn.BatchNorm2d(16),
nn.ReLU(True),
nn.MaxPool2d(2, 2), # (32,32) >> (16,16)
nn.ReLU(True),
nn.Conv2d(16, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(True),
nn.MaxPool2d(2, 2), # (16,16) >> (8,8)
)
# linear 部分
self.fc = nn.Sequential(
nn.BatchNorm2d(32*8*8),
nn.ReLU(True),
nn.Linear(32*8*8, 120),
nn.BatchNorm2d(120),
nn.ReLU(True),
nn.Linear(120, 50),
nn.BatchNorm2d(50),
nn.ReLU(True),
nn.Linear(50, n_class),
)再次运行:

果然抑制了过拟合现象,没normalize的训练到10epoch时达到了0.85,而加了normalize的训练到10epoch时只有0.77,而且准确率也有些许提高 。
不过我们会发下,76%的准确率对于分类来说,似乎太低了,准确率低的原因很多(epoch数,LR,优化函数,神经网络太薄等等),最主要的就是训练不充分,10个epoch 太少了,这回我们训练20个epoch:
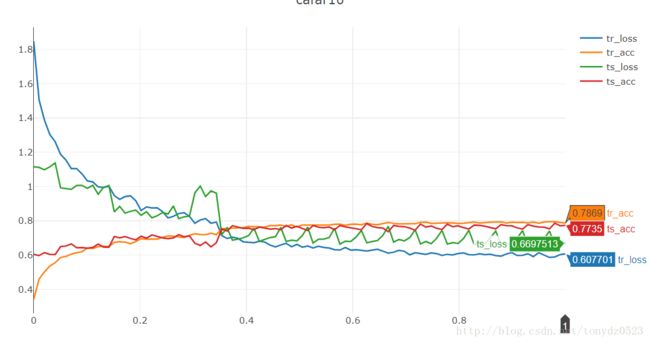
多加了10个epoch ,准确率77%仅仅加了1%,虽然epoch太少,但是这不是最根本的原因,是不是神经层太薄了导致的,加一层试试:
self.cnn = nn.Sequential(
nn.BatchNorm2d(in_dim),
nn.ReLU(True),
nn.Conv2d(in_dim, 16, 5, 1, 2), # (32,32)
nn.BatchNorm2d(16),
nn.ReLU(True),
nn.MaxPool2d(2, 2), # (32,32) >> (16,16)
nn.ReLU(True),
nn.Conv2d(16, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(True),
#添加一层
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(True),
nn.MaxPool2d(2, 2), # (16,16) >> (8,8)
)训练10个epoch,看结果:
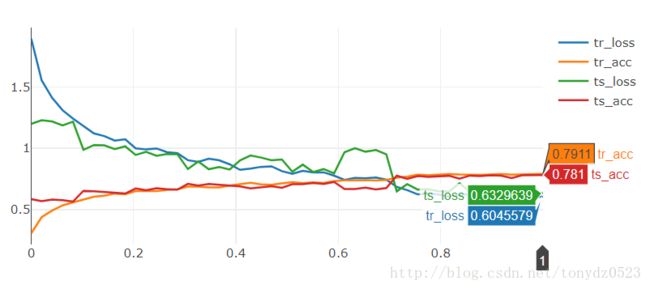
准确率 78%,提高2%,当然可以即增加epoch又加神经层,这里就不再尝试。
torchvision 附带models
注:cpu不要试了
torchvision上models模块带有一些已经写好的network可以直接引用,我们就看看比较简单的resnet18,由于cifar10图片太小,直接使用resnet18 会报错,我们把models文件夹复制到project根目录,进行更改:

ResNet类,更改两个pool的kernel-size:

引用net:
from models import resnet18
# net = CNN(3, 10) #注销原net
net = resnet18()
num_ftrs = net.fc.in_features
# 更改输出数
net.fc = nn.Linear(num_ftrs, 10)训练10个epoch ,看看效果……………………龟速……………………慢慢等…………………………:
9000 | loss : 0.4682 | acc : 0.8581|time:1263.9
10000 | loss : 0.4657 | acc : 0.8572|time:1271.9跑了21分钟。。。,上面我自己写的net的平均5分钟
不过效果也是很好的2个epoch 就75%了,10个epoch 到了准确率85% :
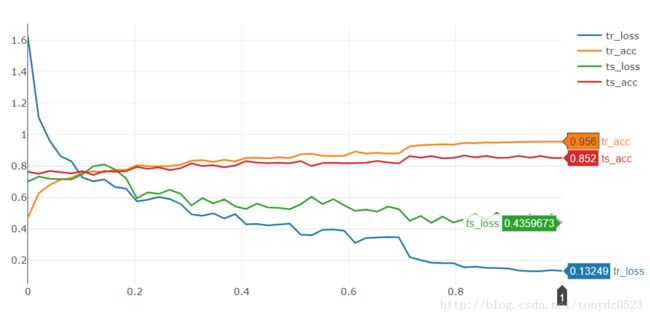
我们print一下net看看,为啥能比我自己写的network准确率高那么多:
ResNet(
(conv1): Conv2d (3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(maxpool): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=(1, 1), dilation=(1, 1))
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d (64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
)
(1): BasicBlock(
(conv1): Conv2d (64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d (64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
(downsample): Sequential(
(0): Conv2d (64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
)
)
(1): BasicBlock(
(conv1): Conv2d (128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d (128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True)
(downsample): Sequential(
(0): Conv2d (128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True)
)
)
(1): BasicBlock(
(conv1): Conv2d (256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d (256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
(downsample): Sequential(
(0): Conv2d (256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
)
)
(1): BasicBlock(
(conv1): Conv2d (512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
)
)
(avgpool): AvgPool2d(kernel_size=2, stride=1, padding=0, ceil_mode=False, count_include_pad=True)
(fc): Linear(in_features=512, out_features=10)
)
因为神经层多么啊。。。。
其实不是的,适当的增加神经层可以增加效果但是并非越多越好,有实验表明简单的累加神经层到很高会出现梯度消失现象,反而降低了训练的效果,ResNet 残差网络 可以实现深层神经网络的构建,详细看这里。
可视化 (visualize)
完整测试 一次,并计入测试结果,对测试结果做heatmap,以观察相关性:
net.eval()
eval_loss, eval_acc = 0., 0.
match = [0]*100
# 因为要记录每一个图片的测试结果,batch_size设为1
test_loader = DataLoader(test_dataset, 1, False)
for i, (img, label) in enumerate(test_loader, 1):
if gpu_status:
img, label = img.cuda(), label.cuda()
img, label = Variable(img, volatile=True), Variable(label, volatile=True)
out = net(img)
loss = loss_f(out, label)
pred = torch.max(out, 1)[1]
eval_acc += sum(pred == label).data[0]
eval_loss += loss.data[0]
# 对 测试集 数据准确率进行记录 注意:本数据集为等比例 每个分类数量相等,否者要用占比
number = int(label.data.cpu().numpy()[0]*10+pred.data.cpu().numpy()[0])
match[number] = match[number] + 1
if i % 1000 == 0:
print("{} | loss : {:.4f} | acc : {:.4f}|time:{:.1f}".format(i, eval_loss/i, eval_acc/i,time.time()-start_time))
count = np.array(match).reshape(10,10)
viz.heatmap(X=count, opts=dict(
columnnames=classes, # 添加分类
rownames=classes,
colormap='Jet', # 选取colormap 用颜色梯度 可视 数值梯度
title="ACC: {:.4f}".format(eval_acc/len(test_dataset)), #标题
xlabel="pred",
ylabel="label"),
env="cifar10")
对colormap颜色的选取可以看看这里:
http://blog.csdn.net/tonydz0523/article/details/79072258

根据图片可见,猫和狗的混淆情况最为严重,相对于交通工具,动物的区分效果更差一些。
代码在这。