机器学习pytorch平台代码学习笔记(8)——优化器 Optimizer
理论知识学习:deeplearning.ai 吴恩达网上课程学习(十一)——优化算法理论讲解和代码实战
用Spyder中如果有枚举enumerate都要在代码开始的地方加
- if __name__ == '__main__':
原因参考链接最后:https://blog.csdn.net/u010327061/article/details/80218836
以下包括以下几种模式:
Stochastic Gradient Descent (SGD) 比较基础Momentum
RMSProp
Adam

1. 引入库
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt2.初始化超参数
torch.manual_seed(1) # reproducible
#超参数一般大写:
LR = 0.01
BATCH_SIZE = 32
EPOCH = 12
3.制造伪数据
# fake dataset 数据
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
4.显示一下伪数据
plt.scatter(x.numpy(), y.numpy())
plt.show()
5. 先转换成 torch 能识别的 Dataset 把数据放入数据库
# 使用上节内容提到的 data loader, loader使训练变成小批。 把 dataset 放入 DataLoader
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)6,每个优化器优化一个神经网络
为了对比每一种优化器, 我们给他们各自创建一个神经网络, 但这个神经网络都来自同一个 Net 形式.
# 默认的 network 形式
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # hidden layer
self.predict = torch.nn.Linear(20, 1) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x
# 为每个优化器创建一个 net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]#放在list里面,可以用个for循环遍历接下来在创建不同的优化器, 用来训练不同的网络. 并创建一个 loss_func 用来计算误差. 我们用几种常见的优化器, SGD, Momentum, RMSprop, Adam.
# different optimizers,same learning rate
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8) #比sgd多了一个momentum参数
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]#放在list里面,可以用个for循环遍历
#回归误差
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # 记录 training 时不同神经网络的 loss8.训练/出图:
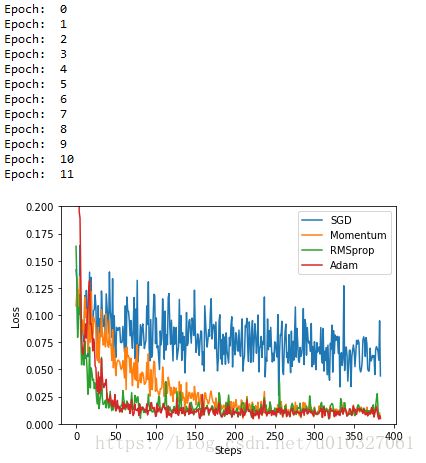
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x) # 务必要用 Variable 包一下,之前传进来的是Tensor的形式,需要转一下
b_y = Variable(batch_y)
# 对每个优化器, 优化属于他的神经网络
for net, opt, l_his in zip(nets, optimizers, losses_his):#三个都是list形式zip打包处理
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data[0]) # loss recoder9.打印:
labels = ['SGD','Momentum','RMSprop','Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his,label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim(0,0.2)
plt.show()10.结果
参考链接:
https://morvanzhou.github.io/tutorials/machine-learning/torch/3-06-optimizer/