hive:函数:排名函数:Rank(笔记)
Rank
1.函数说明
RANK() 排序(排名)相同时会重复,总数不会变
DENSE_RANK() 排序(排名)相同时会重复,总数会减少
ROW_NUMBER() 依次进行排名2.数据准备
表6-7 数据准备
| name |
subject |
score |
| 孙悟空 |
语文 |
87 |
| 孙悟空 |
数学 |
95 |
| 孙悟空 |
英语 |
68 |
| 大海 |
语文 |
94 |
| 大海 |
数学 |
56 |
| 大海 |
英语 |
84 |
| 宋宋 |
语文 |
64 |
| 宋宋 |
数学 |
86 |
| 宋宋 |
英语 |
84 |
| 婷婷 |
语文 |
65 |
| 婷婷 |
数学 |
85 |
| 婷婷 |
英语 |
78 |
3.需求
计算每门学科成绩排名
4.创建本地score.txt,导入数据
vi score.txt
5.创建hive表并导入数据
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\t";
load data local inpath '/opt/module/datas/score.txt' into table score;6.按需求查询数据
select name,
subject,
score,
rank() over(partition by subject order by score desc) rank,
dense_rank() over(partition by subject order by score desc) dense_rank,
row_number() over(partition by subject order by score desc) row_number
from tmp.score;
扩展:求出每门学科前三名的学生?
select * from
(
select
name,
subject,
score,
rank() over(partition by subject order by score desc ) rank,
dense_rank() over(partition by subject order by score desc) dense_rank,
row_number() over(partition by subject order by score desc) row_number
from tmp.score
) s where row_number<=3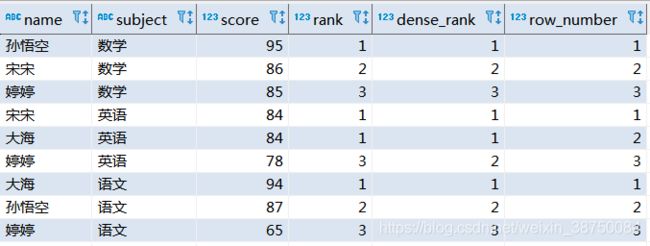
注意:partition后边有哪个字段只会影响最后的rank的排名,跟去重没关系,select后边字段可以指定多个,不一定跟partition后边的字段一致。
举例:
=================sql1:
select
create_time,creator_id,fullname,expectCity,positionName,keywords,row_number() over(partition by creator_id,fullname order by create_time desc) as rank
from (
select from_unixtime(ceil(c.create_time/1000),'yyyy-MM-dd') create_time,c.creator_id,e.fullname,
c.expectCity,c.positionName,c.keywords,c.degree,c.minage,c.maxage,c.isNationalUnified,c.isFamous,c.companyName,c.expectIndustry,c.workCity,c.gender,c.minCurrentSalary,c.maxCurrentSalary,c.minWorkYear,c.maxWorkYear
--,concat(expectCity,':',positionName,'(',keywords,' ',degree,' ',minage,'-',maxage,')') conditions
from tmp.t_conditions c
--select c.creator_id,explode(split(regexp_replace(regexp_replace(expectCity,'\\[',''),'\\]',''),',')) city from tmp.t_conditions c
left join ods.ods_aimsen_walre_anlle_base_employees e
on c.creator_id=e.number
where c.creator_id not in ('130000062','130000063','130000071','430000003')
and c.tag in(2)
and c.phone = ''
and c.resumeId = ''
and c.name = ''
and from_unixtime(ceil(c.create_time/1000),'yyyy-MM-dd') > '2020-07-20'
--and expectCity !='' and degree !='' and (maxAge!='' or minAge!='') and (positionName !='' or keyWords!='')
and creator_id=100400287
group by create_time,c.creator_id,e.fullname,c.expectCity,c.positionName,c.keywords,c.degree,c.minage,c.maxage,c.isNationalUnified,c.isFamous,c.companyName,c.expectIndustry,c.workCity,c.gender,c.minCurrentSalary,c.maxCurrentSalary,c.minWorkYear,c.maxWorkYear--,concat(expectCity,':',positionName,'(',keywords,' ',degree,' ',minage,'-',maxage,')')
) x
=================sql2:
select
create_time,creator_id,fullname,expectCity,positionName,keywords,row_number() over(partition by creator_id,fullname,expectCity order by create_time desc) as rank
from (
select from_unixtime(ceil(c.create_time/1000),'yyyy-MM-dd') create_time,c.creator_id,e.fullname,
c.expectCity,c.positionName,c.keywords,c.degree,c.minage,c.maxage,c.isNationalUnified,c.isFamous,c.companyName,c.expectIndustry,c.workCity,c.gender,c.minCurrentSalary,c.maxCurrentSalary,c.minWorkYear,c.maxWorkYear
--,concat(expectCity,':',positionName,'(',keywords,' ',degree,' ',minage,'-',maxage,')') conditions
from tmp.t_conditions c
--select c.creator_id,explode(split(regexp_replace(regexp_replace(expectCity,'\\[',''),'\\]',''),',')) city from tmp.t_conditions c
left join ods.ods_aimsen_walre_anlle_base_employees e
on c.creator_id=e.number
where c.creator_id not in ('130000062','130000063','130000071','430000003')
and c.tag in(2)
and c.phone = ''
and c.resumeId = ''
and c.name = ''
and from_unixtime(ceil(c.create_time/1000),'yyyy-MM-dd') > '2020-07-20'
--and expectCity !='' and degree !='' and (maxAge!='' or minAge!='') and (positionName !='' or keyWords!='')
and creator_id=100400287
group by create_time,c.creator_id,e.fullname,c.expectCity,c.positionName,c.keywords,c.degree,c.minage,c.maxage,c.isNationalUnified,c.isFamous,c.companyName,c.expectIndustry,c.workCity,c.gender,c.minCurrentSalary,c.maxCurrentSalary,c.minWorkYear,c.maxWorkYear--,concat(expectCity,':',positionName,'(',keywords,' ',degree,' ',minage,'-',maxage,')')
) x
sql1和sql2区别为:
sql2多个expectCity字段
create_time,creator_id,fullname,expectCity,positionName,keywords,row_number() over(partition by creator_id,fullname,expectCity order by create_time desc) as rank
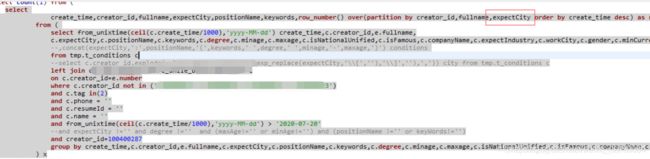
sql1查询效果:

sql2查询效果:

rank排名发生了变化,但最终查询出的结果条数并没有改变。