sklearn实现PCA降维
PCA数据分析
pca听起来是不是很不怎么样,但是但凡你是大数据方向的,那么你可就要警惕一下了,没了它你可能会无从下手对于上千,万维度的数据特征处理起来,下来我就先简单解释一下PCA是何方神圣
PCA概要
PCA的思想是将n维特征映射到k维上(k
这个K维从某种程度造成了一部分的数据 “丢失” 但是不要慌,在某种程度上来说,你的数据不可能是完全的线性相关,那么PCA的另一个功效降噪就很强了,下面我会实现效果,原理有欲望的可以自己去寻找资料研究。
将使用sklearn实现
载入数据集
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits=load_digits()
X=digits.data
y=digits.target
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=0,stratify=digits.target)
使用KNN回归算法进行降维前后时间的对比
from sklearn.neighbors import KNeighborsClassifier
%%time
knn_elf=KNeighborsClassifier()
knn_elf.fit(X_train,y_train)
得到了时间后查看一下KNN
这一步不要和上面一起,这进行Test的运算是要进行一一对比的,超级花费时间的
knn_elf.score(X_test,y_test)
然后结果如下图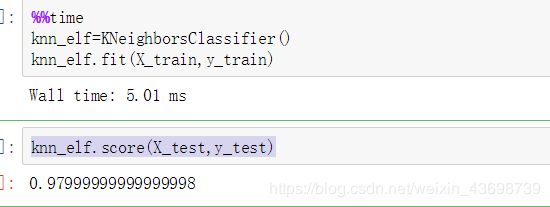
可能时间不一样,毕竟咱俩的计算机性能不同
然后PCA处理
pca=PCA(n_components=2) #只保留2个特征
pca.fit(X_train)
X_train_reduction=pca.transform(X_train)
X_test_reduction=pca.transform(X_test)
%%time
knn_elf=KNeighborsClassifier()
knn_elf.fit(X_train_reduction,y_train)
查看时间的差距
knn_elf.score(X_test_reduction,y_test)
如图

现在时间明显的下降,算法的运行速度明显上升,但是准确率确因为其特征的减少变得降低,很失望??别别才2个特征能高就出了鬼,下面就告诉一个更好的创建PCA的方式
其实如图可以看出PCA降维对于特征数的一个
横轴是特征数,纵族就是特征方差的和

pca=PCA(0.95) #保留 特征方差和 0.95 的特征数
pca.fit(X_train)
pca.n_components # pca降维后的方差总和
pca.n_components_ # pca 降维后的特征数量
X_train_reduction=pca.transform(X_train)
X_test_reduction=pca.transform(X_test)
后面见证奇迹的时刻
%%time
knn_elf=KNeighborsClassifier()
knn_elf.fit(X_train_reduction,y_train)
knn_elf.score(X_test_reduction,y_test)
准确率基本没下降,但是这个时间确降低了好几倍

测试PCA的降噪
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
import numpy as np
digit=load_digits()
X=digit.data
y=digit.target
noisy_digit = X + np.random.normal(0,4,size=X.shape)
example_digits=noisy_digit[y==0,:][:10]
for num in range(1,10):
X_num= noisy_digit[y==num,:][:10]
example_digits=np.vstack([example_digits,X_num])
def plot_digits(data):
fig,axes = plt.subplots(10,10,figsize=(10,10),
subplot_kw={'xticks':[],'yticks':[]},
gridspec_kw=dict(hspace=0.1,wspace=0.1))
for i, ax in enumerate(axes.flat):
ax.imshow(data[i].reshape(8,8),
cmap='binary',interpolation='nearest',
clim=(0,16))
plt.show()
plot_digits(example_digits)

这就是我进行了噪声的图片后面进行,PCA的降噪处理
pca=PCA(0.6)
pca.fit(noisy_digit)
components=pca.transform(example_digits) #降噪
filieter=pca.inverse_transform(components) #恢复数据(无法完全恢复)
plot_digits(filieter)

具体原理就不解释…