pytorch学习笔记:损失函数
0.定义
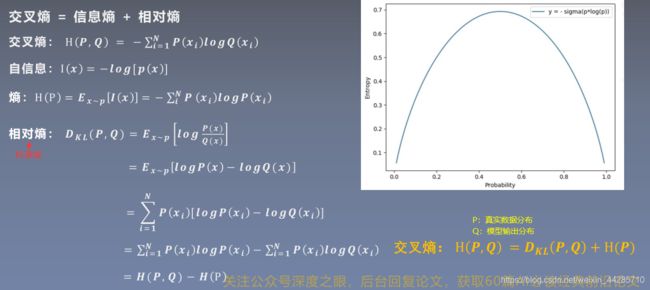
损失函数:衡量模型输出与真实标签的差异

- Cost:希望训练使得预测与标签的差异小一些
- Regularization:对模型增加一些约束,防止过拟合
1.损失函数
1.1 交叉熵损失函数
- labels必须是dtype=torch.long

- 关于weight的设置,有多少个类别,就要设置一个多长的向量,分别代表各weight损失的权重 。mean计算是加权平均,即1.8210/(1+2+2)=0.3642
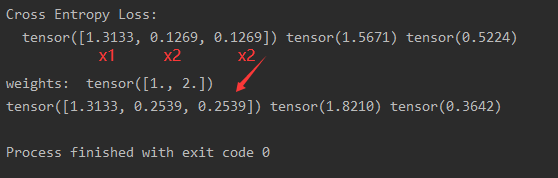
代码验证公式是没有问题的
# fake data
inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
target = torch.tensor([0, 1, 1], dtype=torch.long)
# ----------------------------------- CrossEntropy loss: reduction -----------------------------------
# flag = 0
flag = 1
if flag:
# def loss function
loss_f_none = nn.CrossEntropyLoss(weight=None, reduction='none')
loss_f_sum = nn.CrossEntropyLoss(weight=None, reduction='sum')
loss_f_mean = nn.CrossEntropyLoss(weight=None, reduction='mean')
# forward
loss_none = loss_f_none(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
# view
print("Cross Entropy Loss:\n ", loss_none, loss_sum, loss_mean)
# --------------------------------- compute by hand
# flag = 0
flag = 1
if flag:
idx = 0
input_1 = inputs.detach().numpy()[idx] # [1, 2]
target_1 = target.numpy()[idx] # [0]
# 第一项
x_class = input_1[target_1]
# 第二项
sigma_exp_x = np.sum(list(map(np.exp, input_1)))
log_sigma_exp_x = np.log(sigma_exp_x)
# 输出loss
loss_1 = -x_class + log_sigma_exp_x
print("第一个样本loss为: ", loss_1)
print("第一个样本loss为[手动计算]: ",-1+np.log(np.exp(1)+np.exp(2)))
Cross Entropy Loss:
tensor([1.3133, 0.1269, 0.1269]) tensor(1.5671) tensor(0.5224)
第一个样本loss为: 1.3132617
第一个样本loss为[手动计算]: 1.3132616875182226
softmax计算过程
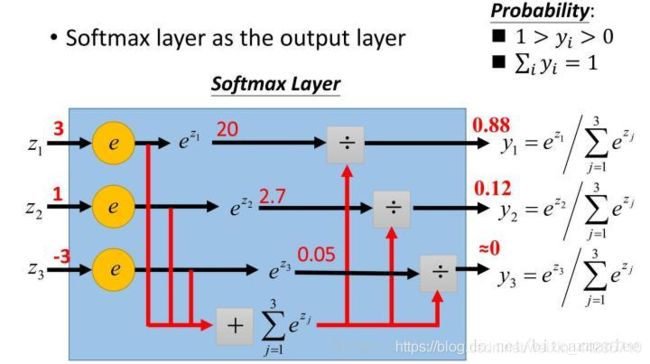


1.2 NLLLoss

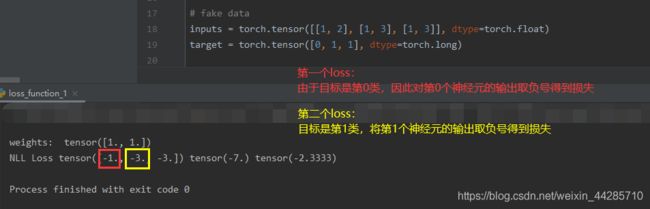
这个损失函数可以理解为:当目标类别的神经元输出经过softmax成为概率值时(比如为0.9),用输出值减去1得到的值(-0.1)计算NLLLoss即为预测概率与标签之间的差异(0.1),这么做不是多此一举吗?所以这个损失函数的用途是啥?
# fake data
inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
target = torch.tensor([0, 1, 1], dtype=torch.long)
flag = 0
# flag = 1
if flag:
weights = torch.tensor([1, 1], dtype=torch.float)
loss_f_none_w = nn.NLLLoss(weight=weights, reduction='none')
loss_f_sum = nn.NLLLoss(weight=weights, reduction='sum')
loss_f_mean = nn.NLLLoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
# view
print("\nweights: ", weights)
print("NLL Loss", loss_none_w, loss_sum, loss_mean)1.3 BCELoss

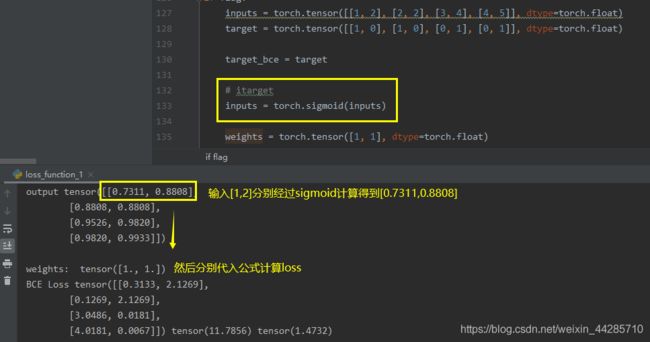
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype=torch.float)
target = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float)
target_bce = target
# itarget
inputs = torch.sigmoid(inputs)
weights = torch.tensor([1, 1], dtype=torch.float)
loss_f_none_w = nn.BCELoss(weight=weights, reduction='none')
loss_f_sum = nn.BCELoss(weight=weights, reduction='sum')
loss_f_mean = nn.BCELoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target_bce)
loss_sum = loss_f_sum(inputs, target_bce)
loss_mean = loss_f_mean(inputs, target_bce)
# view
print("output",inputs)
print("\nweights: ", weights)
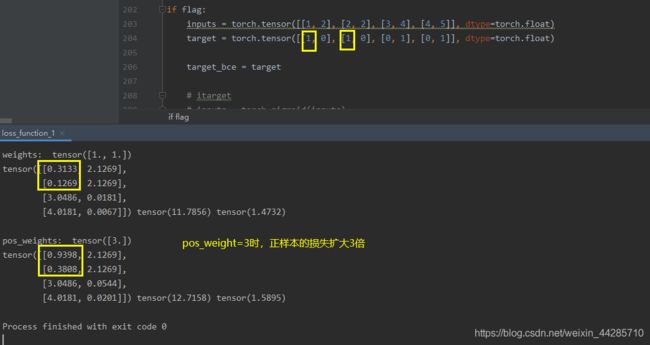
print("BCE Loss", loss_none_w, loss_sum, loss_mean)1.4 BCEwithLogitsLoss(BCELoss基础上加了个sigmoid函数)

1.5 L1Loss、1.6MSELoss

# -------------------- 5 L1 loss ------------------------------
# flag = 0
flag = 1
if flag:
inputs = torch.ones((2, 2))
target = torch.ones((2, 2)) * 3
loss_f = nn.L1Loss(reduction='none')
loss = loss_f(inputs, target)
print("input:{}\ntarget:{}\nL1 loss:{}".format(inputs, target, loss))
# ------------------- 6 MSE loss ------------------------------
loss_f_mse = nn.MSELoss(reduction='none')
loss_mse = loss_f_mse(inputs, target)
print("MSE loss:{}".format(loss_mse))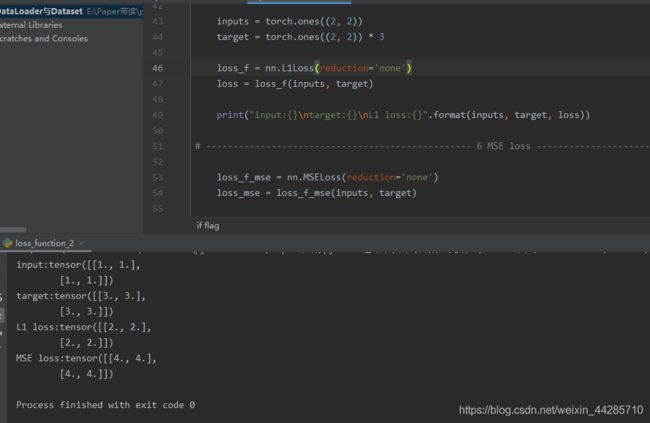
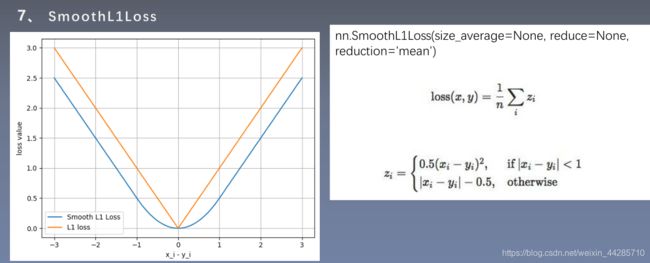
1.7 smoothL1loss
可以减轻离群点带来的影响

1.8 PoissonNLLLoss

# flag = 0
flag = 1
if flag:
inputs = torch.randn((2, 2))
target = torch.randn((2, 2))
loss_f = nn.PoissonNLLLoss(log_input=True, full=False, reduction='none')
loss = loss_f(inputs, target)
print("input:{}\ntarget:{}\nPoisson NLL loss:{}".format(inputs, target, loss))
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
loss_1 = torch.exp(inputs[idx, idx]) - target[idx, idx]*inputs[idx, idx]
print("第一个元素loss:", loss_1)
#输出
input:tensor([[0.6614, 0.2669],
[0.0617, 0.6213]])
target:tensor([[-0.4519, -0.1661],
[-1.5228, 0.3817]])
Poisson NLL loss:tensor([[2.2363, 1.3503],
[1.1575, 1.6242]])
第一个元素loss: tensor(2.2363)1.9 KLDivLoss

# flag = 0
flag = 1
if flag:
inputs = torch.tensor([[0.5, 0.3, 0.2], [0.2, 0.3, 0.5]])
inputs_log = torch.log(inputs)
target = torch.tensor([[0.9, 0.05, 0.05], [0.1, 0.7, 0.2]], dtype=torch.float)
loss_f_none = nn.KLDivLoss(reduction='none')
loss_f_mean = nn.KLDivLoss(reduction='mean')
loss_f_bs_mean = nn.KLDivLoss(reduction='batchmean')
loss_none = loss_f_none(inputs, target)
loss_mean = loss_f_mean(inputs, target)
loss_bs_mean = loss_f_bs_mean(inputs, target)
print("loss_none:\n{}\nloss_mean:\n{}\nloss_bs_mean:\n{}".format(loss_none, loss_mean, loss_bs_mean))
# --------------------------------- compute by hand
# flag = 0
flag = 1
if flag:
idx = 0
loss_1 = target[idx, idx] * (torch.log(target[idx, idx]) - inputs[idx, idx])
print("第一个元素loss:", loss_1)
#输出
loss_none:
tensor([[-0.5448, -0.1648, -0.1598],
[-0.2503, -0.4597, -0.4219]])
loss_mean:
-0.3335360586643219
loss_bs_mean:
-1.000608205795288
第一个元素loss: tensor(-0.5448)
1.10 MarginRankingLoss

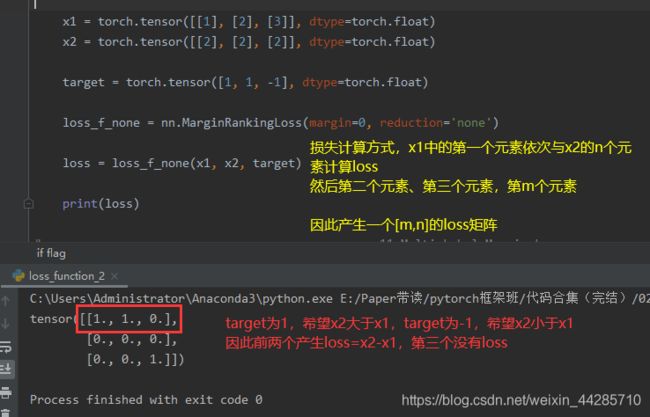
图中红色标注写反了
1.11 MultiLabelMarginLoss

标签所在神经元的输出分别减去非标签所在神经元的输出求和再除以类别数 ,训练的目的就是让标签所在的神经元输出比其他神经元输出都大
# ---------------------------------------------- 11 Multi Label Margin Loss -----------------------------------------
# flag = 0
flag = 1
if flag:
x = torch.tensor([[0.1, 0.2, 0.4, 0.8]])
y = torch.tensor([[0, 3, -1, -1]], dtype=torch.long)
loss_f = nn.MultiLabelMarginLoss(reduction='none')
loss = loss_f(x, y)
print(loss)
# --------------------------------- compute by hand
# flag = 0
flag = 1
if flag:
x = x[0]
item_1 = (1-(x[0] - x[1])) + (1 - (x[0] - x[2])) # [0]
item_2 = (1-(x[3] - x[1])) + (1 - (x[3] - x[2])) # [3]
loss_h = (item_1 + item_2) / x.shape[0]
print("手动计算",loss_h)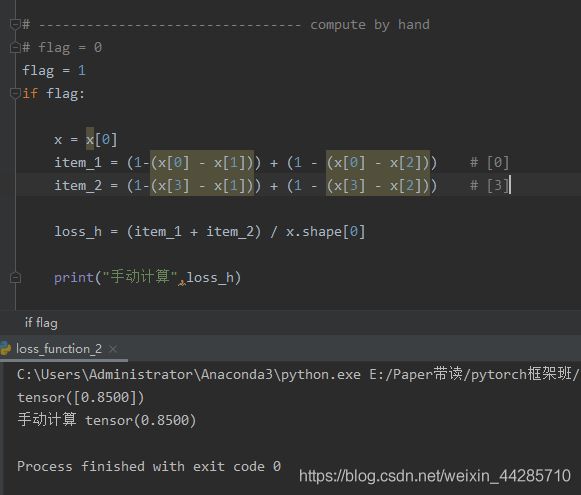
1.12 SoftMarginLoss

# ---------------------------------------------- 12 SoftMargin Loss -----------------------------------------
# flag = 0
flag = 1
if flag:
inputs = torch.tensor([[0.3, 0.7], [0.5, 0.5]])
target = torch.tensor([[-1, 1], [1, -1]], dtype=torch.float)
loss_f = nn.SoftMarginLoss(reduction='none')
loss = loss_f(inputs, target)
print("SoftMargin: ", loss)
# --------------------------------- compute by hand
# flag = 0
flag = 1
if flag:
idx = 0
inputs_i = inputs[idx, idx]
target_i = target[idx, idx]
loss_h = np.log(1 + np.exp(-target_i * inputs_i))
print("手动计算第一个神经元损失",loss_h)1.13

# ---------------------------------------------- 13 MultiLabel SoftMargin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[0.3, 0.7, 0.8]])
target = torch.tensor([[0, 1, 1]], dtype=torch.float)
loss_f = nn.MultiLabelSoftMarginLoss(reduction='none')
loss = loss_f(inputs, target)
print("MultiLabel SoftMargin: ", loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
i_0 = torch.log(torch.exp(-inputs[0, 0]) / (1 + torch.exp(-inputs[0, 0])))
i_1 = torch.log(1 / (1 + torch.exp(-inputs[0, 1])))
i_2 = torch.log(1 / (1 + torch.exp(-inputs[0, 2])))
loss_h = (i_0 + i_1 + i_2) / -3
print(loss_h)1.14
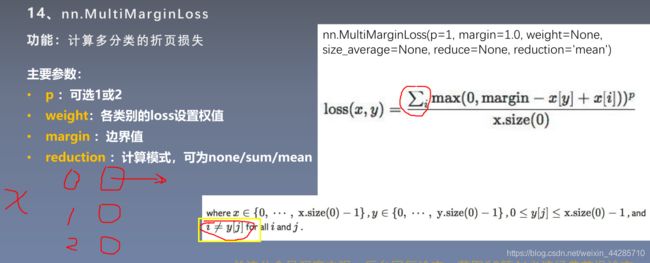
# ---------------------------------------------- 14 Multi Margin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
x = torch.tensor([[0.1, 0.2, 0.7], [0.2, 0.5, 0.3]])
y = torch.tensor([1, 2], dtype=torch.long)
loss_f = nn.MultiMarginLoss(reduction='none')
loss = loss_f(x, y)
print("Multi Margin Loss: ", loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
x = x[0]
margin = 1
i_0 = margin - (x[1] - x[0])
# i_1 = margin - (x[1] - x[1])
i_2 = margin - (x[1] - x[2])
loss_h = (i_0 + i_2) / x.shape[0]
print(loss_h)1.15 TripletMarginLoss

# ---------------------------------------------- 15 Triplet Margin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
anchor = torch.tensor([[1.]])
pos = torch.tensor([[2.]])
neg = torch.tensor([[0.5]])
loss_f = nn.TripletMarginLoss(margin=1.0, p=1)
loss = loss_f(anchor, pos, neg)
print("Triplet Margin Loss", loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 1
a, p, n = anchor[0], pos[0], neg[0]
d_ap = torch.abs(a-p)
d_an = torch.abs(a-n)
loss = d_ap - d_an + margin
print(loss)1.16 HingeEmbeddingLoss

# ---------------------------------------------- 16 Hinge Embedding Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[1., 0.8, 0.5]])
target = torch.tensor([[1, 1, -1]])
loss_f = nn.HingeEmbeddingLoss(margin=1, reduction='none')
loss = loss_f(inputs, target)
print("Hinge Embedding Loss", loss)
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 1.
loss = max(0, margin - inputs.numpy()[0, 2])
print(loss)
1.17 CosineEmbeddingLoss

# ---------------------------------------------- 17 Cosine Embedding Loss -----------------------------------------
# flag = 0
flag = 1
if flag:
x1 = torch.tensor([[0.3, 0.5, 0.7], [0.3, 0.5, 0.7]])
x2 = torch.tensor([[0.1, 0.3, 0.5], [0.1, 0.3, 0.5]])
target = torch.tensor([[1, -1]], dtype=torch.float)
loss_f = nn.CosineEmbeddingLoss(margin=0., reduction='none')
loss = loss_f(x1, x2, target)
print("Cosine Embedding Loss", loss)
# --------------------------------- compute by hand
# flag = 0
flag = 1
if flag:
margin = 0.
def cosine(a, b):
numerator = torch.dot(a, b)
denominator = torch.norm(a, 2) * torch.norm(b, 2)
return float(numerator/denominator)
l_1 = 1 - (cosine(x1[0], x2[0]))
l_2 = max(0, cosine(x1[0], x2[0]))
print(l_1, l_2)
1.18 CTCLoss

# ---------------------------------------------- 18 CTC Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
T = 50 # Input sequence length
C = 20 # Number of classes (including blank)
N = 16 # Batch size
S = 30 # Target sequence length of longest target in batch
S_min = 10 # Minimum target length, for demonstration purposes
# Initialize random batch of input vectors, for *size = (T,N,C)
inputs = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
# Initialize random batch of targets (0 = blank, 1:C = classes)
target = torch.randint(low=1, high=C, size=(N, S), dtype=torch.long)
input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long)
target_lengths = torch.randint(low=S_min, high=S, size=(N,), dtype=torch.long)
ctc_loss = nn.CTCLoss()
loss = ctc_loss(inputs, target, input_lengths, target_lengths)
print("CTC loss: ", loss)