聚类分析 Python sklearn库KMeans类(学习笔记)
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import KMeans
from sklearn import metrics
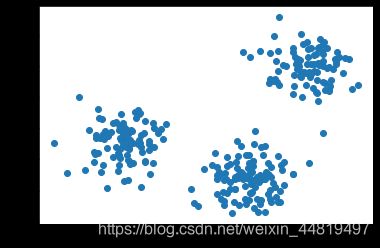
X,y=make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.2,0.2,0.2],random_state=9)
plt.scatter(X[:,0],X[:,1],marker='o')
plt.show()
#选择聚类数K=2
y_pred=KMeans(n_clusters=2,random_state=9).fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=y_pred)
plt.show()
#使用Calinski-Harabasz Index评估
print(metrics.calinski_harabaz_score(X,y_pred))
#选择聚类数K=3
y_pred=KMeans(n_clusters=3,random_state=9).fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=y_pred)
plt.show()
#使用Calinski-Harabasz Index评估
print(metrics.calinski_harabaz_score(X,y_pred))
#选择聚类数K=4
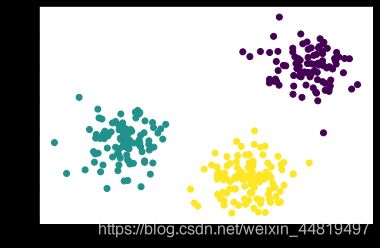
y_pred=KMeans(n_clusters=4,random_state=9).fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=y_pred)
plt.show()
#使用Calinski-Harabasz Index评估
print(metrics.calinski_harabaz_score(X,y_pred))


3116.1706763322227

2931.625030199556

5924.050613480169
K=4时聚类评估分数最高。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
df=pd.read_csv('/point_2D.csv')
X=df.values
plt.scatter(X[:,0],X[:,1],marker='o')
plt.show()
#选择聚类数K=3
y_pred=KMeans(n_clusters=3,random_state=9).fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=y_pred)
plt.show()
print(y_pred)