分类问题常用的损失函数及pytorch实现
前言:
分类问题和回归问题是监督学习的两大种类,关于回归使用的损失函数: 点击链接.
而分类问题一般分为二分类和多分类,下面我们看看在分类问题中使用的损失函数。
目录
- 1、二分类问题
- (1)交叉熵损失函数
- (2)pytorch实现
- 2、多分类问题
- (1)交叉熵损失函数
- (2)pytorch实现
- 3、sigmoid与softmax
- (1)sigmoid
- (2) softmax
- 4、结论
1、二分类问题
(1)交叉熵损失函数
在二分类问题中,损失函数一般为交叉熵损失函数。如下面公式,是对于单个样本的损失函数。

下面是多个样本例子,即mini-batch的损失函数。

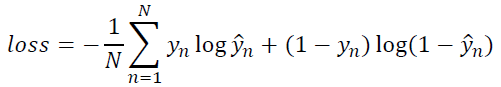
(2)pytorch实现
CLASS torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
上面这个就是二分类交叉熵pytorch封装的类。
参数:
weight (Tensor, optional) -对每个批次元件的损失进行手动重标定。如果给定,必须是一个大小为n*batch的张量。
size_average (bool, optional) – 默认情况下,损失是对批处理中的每个损失元素进行平均。注意,对于一些损失,每个样本有多个元素。如果字段size_average被设置为False,则对每个小批处理的损失进行累加。当reduce为False时被忽略。默认值:True
reduce (bool, optional) –默认情况下为True,损失根据size_average对每个小批的观察值进行平均或求和。当reduce为False时,返回每个批处理元素的损失并忽略size_average。
reduction (string, optional) -指定要应用于输出的减少数,值可以为’none’ 或 ‘mean’ 或’sum’。“none”:不进行降价;“mean”:输出的总和除以输出元素的数量;‘sum’:对输出进行求和。注意:这是在size_average和reduce没有使用的时候,同时,指定这两个参数中的任何一个都将覆盖reduction。默认值:“mean”。
例子:
>>> import torch
>>> import torch.nn as nn
>>> m = nn.Sigmoid()
>>> loss = nn.BCELoss() # 没有参数,用的是默认值
>>> input = torch.randn(3, requires_grad=True)
>>> input
tensor([-1.4220, 1.7056, -1.3578], requires_grad=True)
>>> target=torch.empty(3).random_(2) #random_(from=0,to=None,*,generator=None)将tensor用从在[from, to-1]上的正态分布或离散正态分布取样值进行填充。如果没有明确说明,则填充值仅由本tensor的数据类型限定。
>>> target
tensor([1., 1., 1.])
>>> output = loss(m(input), target)
>>> output
tensor(1.1306, grad_fn=<BinaryCrossEntropyBackward>)
>>> output.backward()
2、多分类问题
(1)交叉熵损失函数

其中 Y Y Y 为标签矩阵, Y ^ \hat Y Y^为模型的输出值。
(2)pytorch实现
CLASS torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
参数:
size_average (bool, optional) - 默认情况下,损失是对批处理中的每个损失元素进行平均。注意,对于一些损失,每个样本有多个元素。如果字段size_average被设置为False,则对每个小批处理的损失进行累加。当reduce为False时被忽略。默认值:True
例子:
>>> import torch
>>> y = torch.LongTensor([0])
>>> z = torch.Tensor([[0.2, 0.1, -0.1]])
>>> criterion = torch.nn.CrossEntropyLoss() # 实例化对象
>>> loss = criterion(z, y) # z为输入,y为标签
>>> print(loss)
tensor(0.9729)
3、sigmoid与softmax
(1)sigmoid
这些都是sigmoid函数,但是用的最多的是Logistic Function,所以一般把下面的这个函数叫做sigmoid函数。

例子:
>>> import torch.nn as nn
>>> m = nn.Sigmoid()
>>> input = torch.randn(2)
>>> output = m(input)
>>> output
tensor([0.3963, 0.4833])
(2) softmax

CLASS torch.nn.Softmax(dim=None)
参数:
dim (int) –计算Softmax的维度(因此dim上的每一个切片加起来都是1)。
例子:
>>> import torch.nn as nn
>>> m = nn.Softmax(dim=1) # 就是列加起来为1
>>> input = torch.randn(2, 3)
>>> output = m(input)
>>> output
tensor([[0.0450, 0.3761, 0.5789],
[0.0572, 0.3111, 0.6317]])
4、结论
-
(1)分类任务损失函数用交叉熵
-
(2)分类又分为2分类+多分类:2分类最后一层输出接一个sigmod保证输出在(0,1)范围内,多分类最后一层输出N(分类个数)个值,这N个值过一下Softmax,相当于是归一化一下到( 0, 1) 区间内。