PyTorch之—可视化(Visdom/TensorboardX)
文章目录
- 一、Visdom
- 安装与使用
- 小案例
- 二、TensorBoardX
- 案例一
- 案例二
- 使用PROJECTOR对高维向量可视化
- 绘制网络结构
一、Visdom
Visdom是Facebook在2017年发布的一款针对PyTorch的可视化工具。visdom由于其功能简单,一般会被定义为服务器端的matplot,也就是说我们可以直接使用python的控制台模式进行开发并在服务器上执行,将一些可视化的数据传送到Visdom服务上,通过Visdom服务进行可视化。
官网:https://github.com/facebookresearch/visdom
安装与使用
执行命令:pip install visdom安装即可。
使用命令:python -m visdom.server 在本地启动服务器,启动后会提示It’s Alive! You can navigate to http://localhost:8097 这就说明服务已经可用。
输入地址:http://localhost:8097 即可看到页面。
此时终端:
(AI_PyTorch_GPU) E:\pytorch_AI>python -m visdom.server
Checking for scripts.
It's Alive!
INFO:root:Application Started
You can navigate to http://localhost:8097
INFO:tornado.access:200 GET / (::1) 14.96ms
INFO:tornado.access:200 GET /static/css/react-resizable-styles.css?v=9f91a8dbf4d8f7ef1399e625660405f4 (::1) 1.00ms
INFO:tornado.access:200 GET /static/css/react-grid-layout-styles.css?v=7dc8934d2f9ac5303b8f0bb1148152a0 (::1) 2.00ms
INFO:tornado.access:200 GET /static/js/bootstrap.min.js?v=5869c96cc8f19086aee625d670d741f9 (::1) 1.00ms
INFO:tornado.access:200 GET /static/js/react-react.min.js?v=bca103da5b5404d93783ccf73e0e9d1e (::1) 0.00ms
INFO:tornado.access:200 GET /static/fonts/layout_bin_packer?v=6c46683ed70fbb1443caf3531243836d (::1) 1.00ms
INFO:tornado.access:200 GET /static/css/bootstrap.min.css?v=ec3bb52a00e176a7181d454dffaea219 (::1) 188.49ms
INFO:tornado.access:200 GET /static/js/react-dom.min.js?v=950495cc51ccb90612cf0fe0bb44f8f3 (::1) 11.97ms
INFO:tornado.access:200 GET /static/js/jquery.min.js?v=e071abda8fe61194711cfc2ab99fe104 (::1) 5.98ms
INFO:tornado.access:200 GET /static/css/style.css?v=f1b2f4d2442b8263f30058d8085c1ab3 (::1) 1.02ms
INFO:tornado.access:200 GET /static/js/mathjax-MathJax.js?v=49565b9ce89c64da075a5a39969b366e (::1) 1.00ms
INFO:tornado.access:200 GET /static/js/main.js?v=4316a77ded15b92b6e884b60b72f6513 (::1) 21.94ms
INFO:tornado.access:200 GET /static/js/plotly-plotly.min.js?v=00dcca8ba45aab5f63dc7fc55a544d3d (::1) 81.78ms
INFO:tornado.access:200 GET /static/fonts/glyphicons-halflings-regular.woff2 (::1) 1.00ms
INFO:tornado.access:101 GET /socket (::1) 1.00ms
INFO:root:Opened new socket from ip: ::1
INFO:tornado.access:200 POST /env/main (::1) 0.99ms
INFO:tornado.access:200 POST /env/main (::1) 0.00ms
INFO:tornado.access:200 GET /favicon.png (::1) 2.99ms
INFO:tornado.access:200 GET /extensions/MathMenu.js?V=2.7.1 (::1) 2.03ms
INFO:tornado.access:200 GET /extensions/MathZoom.js?V=2.7.1 (::1) 1.96ms
端口8097是默认的端口可以在启动命令后加 -port参数指定端口,常用的参数还有 --hostname,-base_url等
Visdom的服务在启动时会自动下载一些静态文件,可能会有报错问题。这里直接复制到Lib\site-packages\visdom中即可。
C:\Anaconda3\envs\<"虚拟环境名">\Lib\site-packages\visdom
关于文件详情以及安装 详情请点击
Visdom是由Plotly 提供的可视化支持,所以提供一下可视化的接口
- 可视化接口:
-
vis.scatter : 2D 或 3D 散点图
vis.line : 线图
vis.stem : 茎叶图
vis.heatmap : 热力图
vis.bar : 条形图
vis.histogram: 直方图
vis.boxplot : 箱型图
vis.surf : 表面图
vis.contour : 轮廓图
vis.quiver : 绘出二维矢量场
vis.image : 图片
vis.text : 文本
vis.mesh : 网格图
vis.save : 序列化状态
小案例
import math
import numpy as np
from visdom import Visdom
import time
env = Visdom()
assert env.check_connection() #测试一下链接,链接错误的话会报错
Y = np.linspace(0, 2 * math.pi, 70)
X = np.column_stack((np.sin(Y), np.cos(Y)))
env.stem(
X=X,
Y=Y,
opts=dict(legend=['Sine', 'Cosine'])
)
# 通过env参数指定Environments,如果名称包含了下划线,那么visdom会跟根据下划线分割并自动分组
envtest = Visdom(env='test_mesh')
assert envtest.check_connection()
x = [0, 0, 1, 1, 0, 0, 1, 1]
y = [0, 1, 1, 0, 0, 1, 1, 0]
z = [0, 0, 0, 0, 1, 1, 1, 1]
X = np.c_[x, y, z]
i = [7, 0, 0, 0, 4, 4, 6, 6, 4, 0, 3, 2]
j = [3, 4, 1, 2, 5, 6, 5, 2, 0, 1, 6, 3]
k = [0, 7, 2, 3, 6, 7, 1, 1, 5, 5, 7, 6]
Y = np.c_[i, j, k]
envtest.mesh(X=X, Y=Y, opts=dict(opacity=0.5))
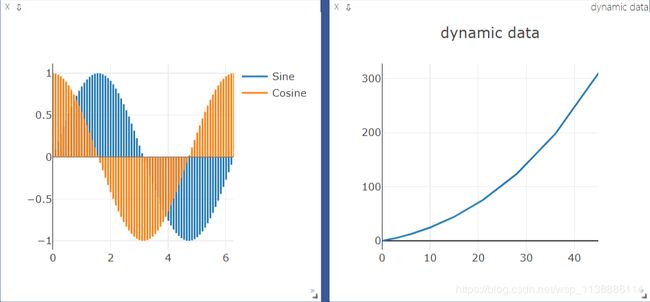
# 更新损失函数
x,y=0,0
env2 = Visdom()
pane1= env2.line(
X=np.array([x]),
Y=np.array([y]),
opts=dict(title='dynamic data'))
for i in range(10):
time.sleep(1) # 每隔一秒钟打印一次数据
x+=i
y=(y+i)*1.5
print(x,y)
env2.line(
X=np.array([x]),
Y=np.array([y]),
win=pane1, # win参数确认使用哪一个pane
update='append') # 我们做的动作是追加,除了追加意外还有其他方式
二、TensorBoardX
安装与使用 (依次执行如下命令)
pip install tensorboard #安装tensorboard
pip install tensorboardx #安装tensorboardx
tensorboard --logdir runs
http://localhost:6006/ #在chrome浏览器中打开
案例一
项目地址:https://github.com/lanpa/tensorboardX
python examples/demo.py
tensorboard --logdir runs
http://localhost:6006/ #在chrome浏览器中打开
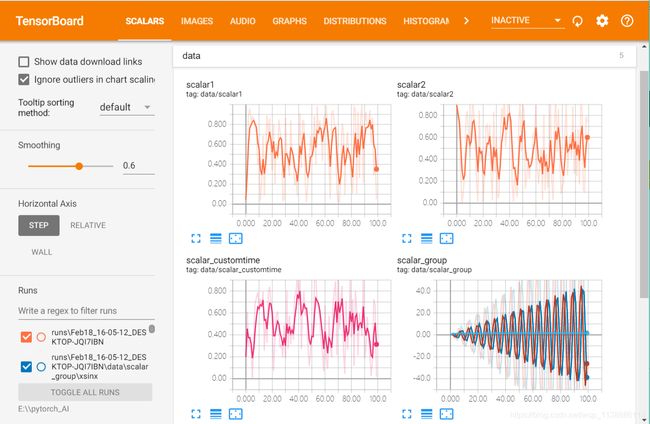
界面说明
-
SCALAR
对标量数据进行汇总和记录,通常用来可视化训练过程中随着迭代次数准确率(val acc)、损失值(train/test loss)、学习率(learning rate)、每一层的权重和偏置的统计量(mean、std、max/min)等的变化曲线 -
IMAGES
可视化当前轮训练使用的训练/测试图片或者 feature maps -
GRAPHS
可视化计算图的结构及计算图上的信息,通常用来展示网络的结构 -
HISTOGRAMS
可视化张量的取值分布,记录变量的直方图(统计张量随着迭代轮数的变化情况) -
PROJECTOR
全称Embedding Projector 高维向量进行可视化 -
使用
在使用前请先去确认执行tensorboard --logdir logs 并保证 http://localhost:6006/ 页面能够正常打开。tensorboard 使用详情请点击
案例二
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
from PIL import Image
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import models,datasets
from tensorboardX import SummaryWriter
cat_img = Image.open('./Felis_silvestris_catus_lying_on_rice_straw.jpg')
transform_224 = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
])
cat_img_224=transform_224(cat_img)
# 将图片展示在tebsorboard中:
writer = SummaryWriter(log_dir='./logs', comment='cat image') # 这里的logs要与--logdir的参数一样
writer.add_image("cat",cat_img_224)
writer.close()# 执行close立即刷新,否则将每120秒自动刷新
# 更新损失函数
# 更新损失函数和训练批次我们与visdom一样使用模拟展示,这里用到的是tensorboard的SCALAR页面
x = torch.FloatTensor([100])
y = torch.FloatTensor([500])
for epoch in range(100):
x /= 1.5
y /= 1.5
loss = y - x
with SummaryWriter(log_dir='./logs', comment='train') as writer: #with语法:自动调用close方法
writer.add_histogram('his/x', x, epoch)
writer.add_histogram('his/y', y, epoch)
writer.add_scalar('data/x', x, epoch)
writer.add_scalar('data/y', y, epoch)
writer.add_scalar('data/loss', loss, epoch)
writer.add_scalars('data/data_group', {'x': x,
'y': y,
'loss': loss}, epoch)
查看图像:
-
方法一:
激活环境 --> 进入logs目录 -->执行命令 --> chrome下打开http://localhost:8080/(AI_PyTorch_GPU) E:\pytorch_AI\logs>tensorboard --logdir=E:\\pytorch_AI\\logs --port=8080 TensorBoard 1.12.2 at http://DESKTOP-JQI7IBN:8080 (Press CTRL+C to quit)如图:
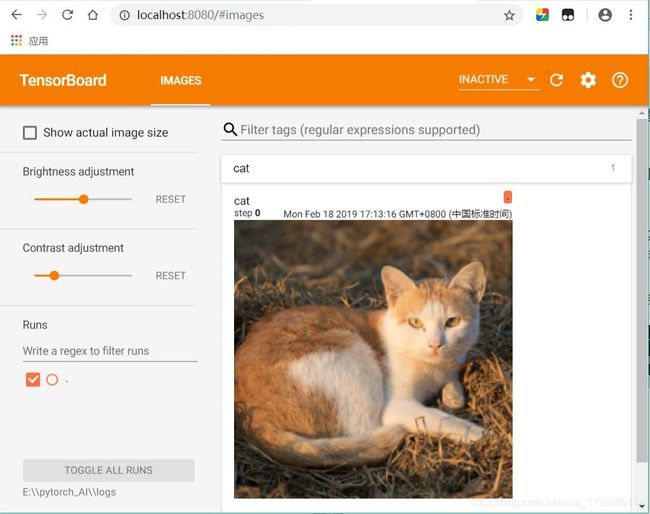
-
方法二:
激活环境 --> 进入logs父目录 -->执行命令 --> chrome下打开http://localhost:6006/(AI_PyTorch_GPU) E:\pytorch_AI>tensorboard --logdir logs TensorBoard 1.12.2 at http://DESKTOP-JQI7IBN:6006 (Press CTRL+C to quit)如图:
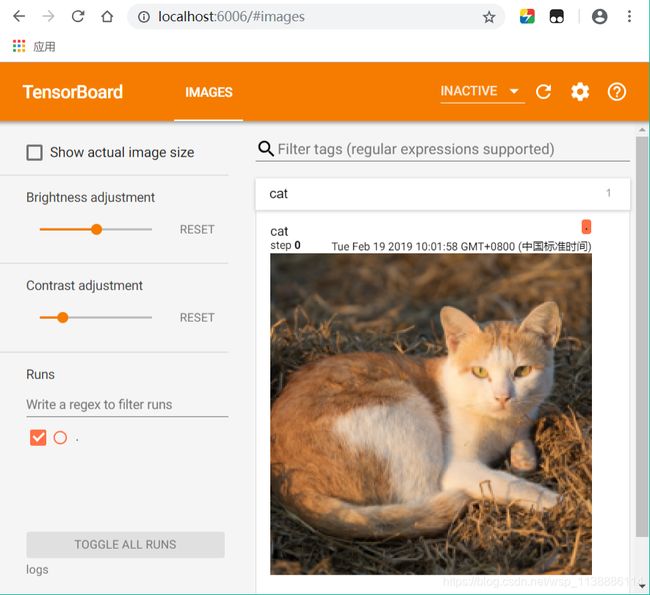
使用PROJECTOR对高维向量可视化
PROJECTOR的的原理是通过PCA,T-SNE等方法将高维向量投影到三维坐标系(降维度)。Embedding Projector从模型运行过程中保存的checkpoint文件中读取数据,默认使用主成分分析法(PCA)将高维数据投影到3D空间中,也可以通过设置设置选择T-SNE投影方法,这里做一个简单的展示。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
from tensorboardX import SummaryWriter
""" ==================使用PROJECTOR对高维向量可视化====================
PROJECTOR的的原理是通过PCA,T-SNE等方法将高维向量投影到三维坐标系(降维度)。
Embedding Projector从模型运行过程中保存的checkpoint文件中读取数据,
默认使用主成分分析法(PCA)将高维数据投影到3D空间中,也可以通过设置设置选择T-SNE投影方法,
这里做一个简单的展示。
"""
BATCH_SIZE=256
EPOCHS=20
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = DataLoader(datasets.MNIST('./mnist', train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./mnist', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1,28x28
self.conv1=nn.Conv2d(1,10,5) # 10, 24x24
self.conv2=nn.Conv2d(10,20,3) # 128, 10x10
self.fc1 = nn.Linear(20*10*10,500)
self.fc2 = nn.Linear(500,10)
def forward(self,x):
in_size = x.size(0)
out = self.conv1(x) #24
out = F.relu(out)
out = F.max_pool2d(out, 2, 2) #12
out = self.conv2(out) #10
out = F.relu(out)
out = out.view(in_size,-1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out,dim=1)
return out
model = ConvNet().to(DEVICE)
optimizer = torch.optim.Adam(model.parameters())
def train(model, DEVICE,train_loader, optimizer, epoch):
n_iter=0
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data,target = data.to(DEVICE),target.to(DEVICE)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if(batch_idx+1)%30 == 0:
n_iter=n_iter+1
print('Train Epoch: {} [{}/{} ({:.0f}%)]\t Loss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
#主要增加了一下内容
out = torch.cat((output.data.cpu(), torch.ones(len(output), 1)), 1) # 因为是投影到3D的空间,所以我们只需要3个维度
with SummaryWriter(log_dir='./pytorch_tensorboardX_03_logs', comment='mnist') as writer:
#使用add_embedding方法进行可视化展示
writer.add_embedding(
out,
metadata=target.data,
label_img=data.data,
global_step=n_iter)
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # 损失相加
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\n Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'
.format(test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader)
# 保存模型
torch.save(model.state_dict(), './pytorch_tensorboardX_03.pth')
# Test set: Average loss: 0.0400, Accuracy: 9913/10000 (99%)
如上代码直接点击运行。
可视化展示:
(AI_PyTorch_GPU) E:\pytorch_AI>tensorboard --logdir pytorch_tensorboardX_03_logs
TensorBoard 1.12.2 at http://DESKTOP-JQI7IBN:6006 (Press CTRL+C to quit)
复制http://localhost:6006/到chrome打开:
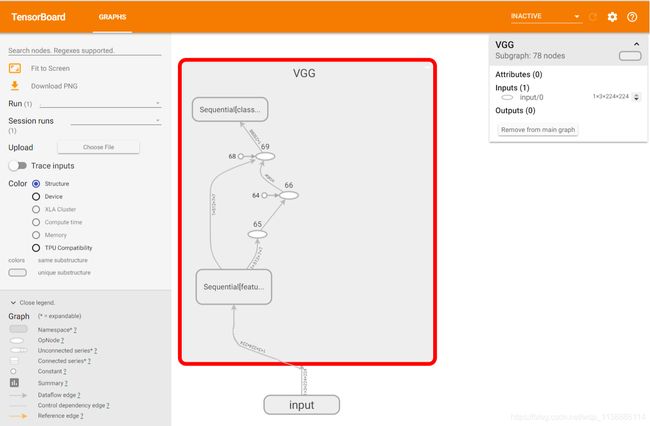
绘制网络结构
import torch
import numpy as np
from torchvision import models,transforms
from PIL import Image
from tensorboardX import SummaryWriter
vgg16 = models.vgg16() # 这里下载预训练好的模型
print(vgg16) # 打印一下这个模型
transform_2 = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
# convert RGB to BGR
# from (AI_PyTorch_GPU) E:\pytorch_AI>tensorboard --logdir vgg16_logs
TensorBoard 1.12.2 at http://DESKTOP-JQI7IBN:6006 (Press CTRL+C to quit)