微服务架构下的数据一致性:可靠事件模式
原文转自:EAII企业架构创新研究院《微服务架构下的数据一致性保证(二)》,行文结构和内容有修改。
在《微服务架构下的数据一致性:概念及相关模式》中介绍了在微服务中实现数据一致性的三种方式,包括可靠事件模式、业务补偿模式、TCC模式。本文重点说一下可靠事件投递。
1. 可靠事件模式
可靠事件模式属于事件驱动架构,微服务完成操作后向消息代理发布事件,关联的微服务从消息代理订阅到该事件从而完成相应的业务操作,关键在于可靠事件投递和避免事件重复消费。
可靠事件投递有两个特性:1)每个服务原子性的完成业务操作和发布事件;2)消息代理确保事件投递至少一次(at least once)。
避免重复消费要求消费事件的服务实现幂等性。
现下流行的消息队列都已经实现了事件的持久化和at least once的投递模式,所以可靠事件投递的第二条特性已经满足,这里就不展开。需要着重说的就是可靠时间投递的第一条特性和避免事件重复消费,即服务的原子性和消费者的幂等性。
2. 可靠事件投递
2.1 潜在风险
先来看一段简单的代码:
public void trans() {
try {
// 1. 操作数据库
bool result = dao.update(mode1);// 操作数据库失败,会抛出异常
// 2. 如果第一步成功,则操作消息队列(投递消息)
if(result){
mq.append(mode1);// 如果mq.append方法执行失败,会抛出异常
}
} catch (Exception e) {
roolback();// 如果发生异常,就回滚
}
}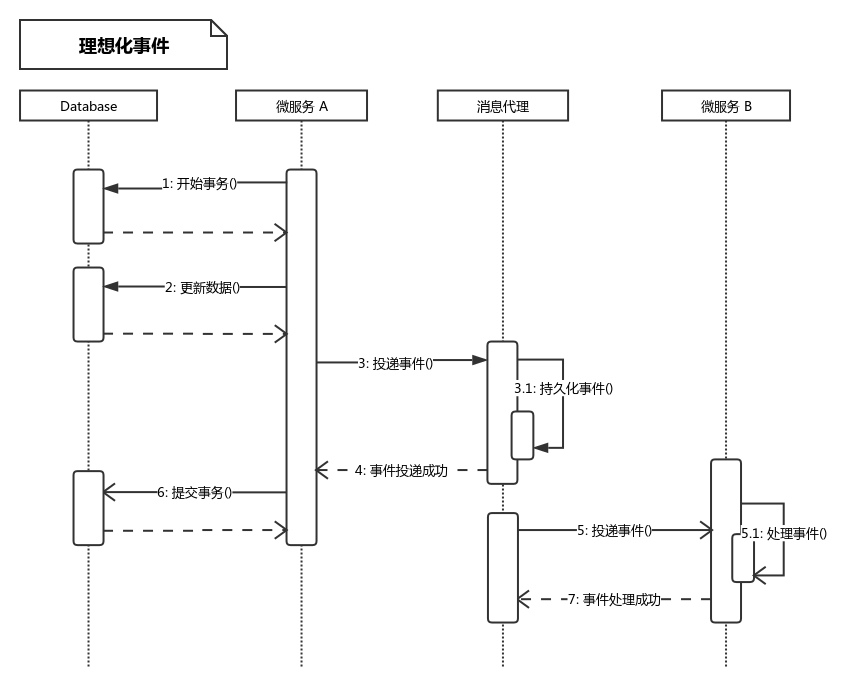
根据上面代码和时序图,理想化的情况会出现3中情况:
- 操作数据库成功,向消息代理投递事件也成功
- 操作数据库失败,不会向消息代理中投递事件了
- 操作数据库成功,但是向消息代理中投递事件时失败,向外抛出了异常,刚刚执行的更新数据库的操作将被回滚
之所以说是理想化,是因为上面的思路还是传统的本地事务,但是在微服务架构中,可能出错的情况更为复杂,其中最容易出现的错误就是网络IO和服务器宕机:
- 微服务A投递事件时,消息代理已经接收到消息,并进行持久化成功,即消息发送至消息代理,需要向微服务A返回响应的时候,网络发生异常,即4出现错误,代码中的
mq.append()方法抛出异常,最终结果是事件投递成功,但是数据库被回滚。

- 微服务A在投递成功后,向数据库提交commit请求之前发生宕机,数据库因为连接异常关闭而回滚。最终结果还是事件被投递,数据库却被回滚。
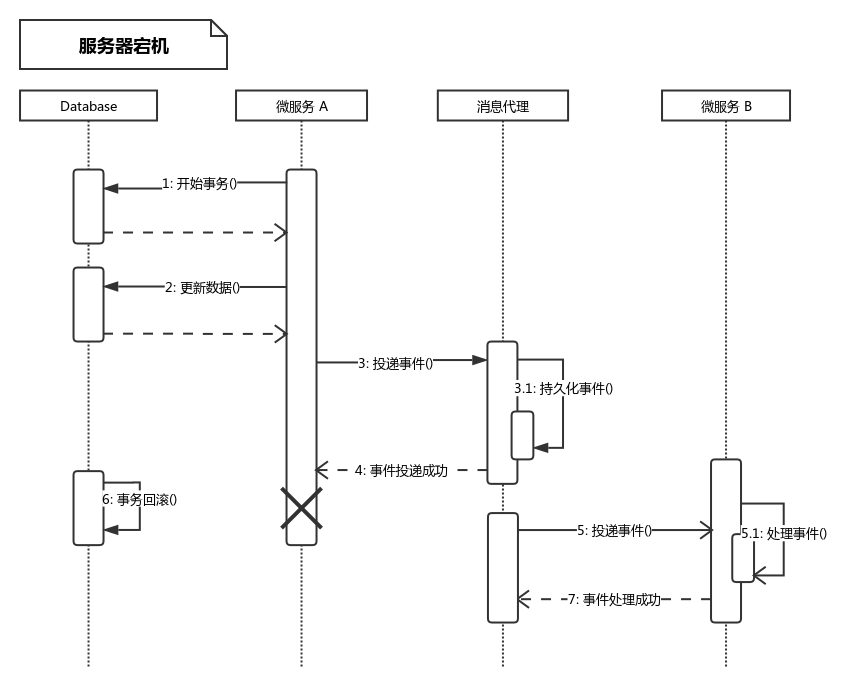
在单服务器情况下,上面提到的两种异常发生概览不大,但是在当前多服务器、网络情况复杂的环境中,发生的概率被大大放大,由于是异步处理,一旦问题发生,拍错将变得更加困难。
2.2. 可靠事件投递的两种实现
2.2.1 本地事件表
本地事件表方法将事件和业务数据保存在同一个数据库中,使用一个额外的“事件恢复”服务来恢复事件,由本地事务保证更新业务和发布事件的原子性。考虑到事件恢复可能会有一定的延时,服务在完成本地事务后可立即向消息代理发布一个事件。

- 微服务在同一个本地事务中记录业务数据和事件数据
- 微服务实时发布一个事件关联业务服务中,如果事件发布成功立即删除记录的事件,这样能够保证事件投递的实时性。
- 事件恢复服务定时从事件表中恢复未发布成功的事件,重新发布,重新发布成功后删除记录的事件,这样能够保证事件一定能够被投递。
这样能够很好的解决上面提到的网络IO异常和服务器宕机的问题,但是业务系统和事件耦合在一起,额外的事件数据操作给数据库带来压力,也成为异步事件机制的一个瓶颈。
2.2.2 外部事件表
针对本地事件表出现的问题,提出外部事件表方法,将事件持久化到外部的事件系统,事件系统需提供实时事件服务以接收微服务发布的事件,同时事件系统还需要提供事件恢复服务来确认和恢复事件。

- 业务服务在事务提交前,通过实时事件服务向事件系统请求发送事件,事件系统只记录事件并不真正发送
- 业务服务在提交后,通过实时事件服务向事件系统确认发送,事件得到确认后事件系统才真正发布事件到消息代理
- 业务服务在业务回滚时,通过实时事件向事件系统取消事件
- 事件系统的事件恢复服务会定期找到未确认发送的事件向业务服务查询状态,根据业务服务返回的状态决定事件是要发布还是取消
该方式将业务系统和事件系统独立解耦,都可以独立伸缩。但是这种方式需要一次额外的发送操作,并且需要发布者提供额外的查询接口,这样就增加了系统实现的复杂性。
3. 幂等性
3.1 事件本身具备幂等性
本身具备幂等性的事件,需要考虑执行顺序。如果事件本身描述的是某个时间点的状态,而不是变化,那么就说这个事件具备幂等性。比如,某个时间点账户余额为100,这个事件就具备幂等性;某个时间点账户余额增加10,这个事件就不具备幂等性。
那么,这种具备幂等性的事件需要考虑执行顺序,比如,事件1是2016-07-16 15:07:31账户余额是100,事件2是2016-07-16 25:07:31账户余额是120。
- 如果事件1执行完成后执行事件2,将获得我们期望的结果。
- 如果事件2先执行,然后又执行了事件1,那结果就不是我们期望的了。
- 如果事件1执行完成后执行事件2,此时结果是我们需要的,但由于事件重复发送,又执行了一遍事件1,此时结果也不是我们期望的了。
简单的说,我们需要保证事件2一旦处理,事件1就不能再处理。
为了保证事件的顺序,最简单的做法就是在事件中添加时间戳。微服务记录每个事件最后处理的时间戳,如果收到的事件的时间戳早于我们记录的,丢弃该事件。当然,在高并发的情况下,同一时间内可能出现多个事件;事件由不同服务器发出,时间可能不同步。这两种情况下,可以选择使用全局递增序列号替换时间戳。
3.2 事件本身不具备幂等性
对于本身不具有幂等性的事件,主要思想是存储每条事件执行结果。当收到一个事件时,我们需要根据事件的标识ID查询该事件是否已经执行过,如果执行过直接返回上一次的执行结果,否则调度执行事件。
这里唯一需要考虑的就是资源开销:重复执行一次的开销,查询执行结果的开销。
- 如果重复执行一次的开销非常小,或者只有很少的事件会被重复接收,可以选择重复执行一次事件,在将事件持久化到的过程中,由于唯一键(标识ID)重复,持久化过程失败。
- 如果重复执行开销较大,则直接使用一个过滤服务,过滤重复事件。即使用标识ID过滤事件是否重复。如果是,直接返回上一次执行结果。
对于重复执行开销比较大的情况,可能服务执行时间较长。就会出现这么一种情况:接收到一个新的事件,服务开始执行,执行过程中,又接收到重复事件,这个时候上个事件还没有执行完成,即过滤服务还没有收到上次执行的结果,但是重复执行开销又大。解决办法就是对处理过程分段:接收、开始处理、处理完毕等,可以根据不同业务进行不同的分段。这样过滤服务就能够及时发现重复事件,并能够根据事件处理状态做出不同处理。
另一个需要注意的地方就是,微服务实现数据一致性最好的方式是最终一致性。有些需要考虑的极端情况下,是需要人工接入的,这里就不展开了。
主页:http://www.howardliu.cn/
博客:微服务架构下的数据一致性:可靠事件模式