实战X86寄存器
原文: http://blog.chinaunix.net/uid-23069658-id-3756930.html
作为一个程序员,当白天和黑夜没有了界限,按照相对论的观点,这时候他就变成了一个“程序猿”。
---------------佚名今天下班早,但了无睡意,发篇之前欠下的博文。今天我们简单回顾一下当年学校里“微机原理”和“汇编语言程序设计”这门课,年代有些久远,可能好多人都记不得了,当然我也是,提前步入老龄化了呀。闲话不表。
讲x86寄存器本身就是比较枯燥的一件事儿,所以我打算在讲解的过程中,有必要的通过一些例子来向大家展示一下寄存器的作用。这中间会用到NASM汇编语法,不过都比较好懂,对示例代码中的指令不会做过多解释,有需要的童鞋可以去参阅NASM手册。
在博文“ 动态库和静态库那点事儿 ”里,我们了解到,汇编器(Assembler)是将汇编语言源代码翻译为机器语言的程序。一般而言,汇编生成的目标代码段,需要经链接器(Linker)处理才可生成最终的可执行代码。
汇编语言问世之前,程序员都是用二进制的“0”和“1”的序列进行编程,也就是我们所说的机器语言,其痛苦程度可想而知。为了减轻使用机器语言编程的痛苦,20世纪50年代初,出现了汇编语言。汇编语言用比较容易识别、记忆的助记符替代特定的二进制串。关于汇编语言的发展可以参考“ 汇编语言发展树 ”,算是了解一下课外知识。
那么什么又是汇编语言?汇编语言是为特定CPU设计的一种面向机器的语言﹐和CPU的架构密切相关,由汇编执行指令和汇编伪指令组成。使用汇编语言编写的程序,机器不能直接识别。汇编器会将汇编语言翻译成机器语言,而汇编器把汇编语言翻译成机器语言的过程称为汇编。 所以,这个汇编器的功能可大着呢,它充当了汇编语言源程序和机器语言之间的翻译。而时下主流的汇编器,有以下几款:
MASM:是微软公司开发的汇编编译器,采用Intel规定的汇编语法,在6.0版本以前单独发布,分masm.exe和link.exe。从6.0版开始MASM就改名ML了,因为它把编译和链接组合在一起了。9.0版的ML跟随VC2008一起发布。以前我们在学校学的就是这个家伙。
TASM:是Borland公司开发的汇编编译器,被广泛用于Turbo C,Quick Basic等编译器,用作中间过渡编译。它也能独立的编译纯汇编或是Win32Asm的代码。具有编译快速,高效的特点。TASM完全兼容MASM。由于头文件和库不完整,在win32下使用TASM有些力不从心,Borland公司目前已放弃了对其的维护和开发。
FASM:Flat Assembler,是一个纯粹用汇编语言写成,并采用自展技术的编译器。优点是不需要链接直接可以生成可执行文件。
NASM:(Netwide Assembler),是Linux 平台上一个经常用到的汇编器,由Netwide公司开发。NASM是以可移植性和模块化为目标,以支持80x86为基础而设计的编译器,它提供了很好的宏指令功能,支持多种目标文件格式,包括Linux和NetBSD、FreeBSD操作系统的a.out、ELF、COFF等文件格式,以及微软公司16位OBJ和32位OBJ文件格式;它也可以输出无格式的二进制文件(如Dos.COM,.sys)。它的语法格式很简单且易于理解,与Intel规定的很相似但却没有那么复杂。NASM 采用的是人工编写的语法分析器,因而执行速度要比 GAS 快很多,更重要的是它使用的是 Intel 汇编语法,可以用来编译用 Intel 语法格式编写的汇编程序。
GAS:(GNU Assembler), 这是Linux 平台的标准汇编器 ,它也是 GCC 所依赖的后台汇编工具,通常包含在 binutils 软件包中。GAS 使用标准的 AT&T 汇编语法(和Intel的标准语法有些区别),可以用来汇编用 AT&T 格式编写的程序。GCC会保证提供给它绝对正确的代码,所以GAS的错误检测功能相当弱。
重申:本文中所有的代码都是Intel风格的NASM,当你弄明白了Intel风格的汇编语法后,再去看AT&T的汇编代码,得其章法后绝对不成问题,我保证,除非.....那啥.....呵呵.......
80x86CPU,其内部的寄存器可以分为以下几类: 通用寄存器 、 专用寄存器 、 段寄存器
x86的CPU其特性都是前向兼容,所以32位的寄存器可以兼容16位和8位,16位的寄存器可以兼容8位。也就是说,32位CPU可以只使用其低16位,将它作为16位CPU来对待;16位CPU可以将其高8位和低8位分开,当作两个8位CPU来使用。当要注意,有些寄存器是不能这样分开使用的,后面我们会提到。
1 、通用寄存器,一共有 8 个,其分类和关系如下:
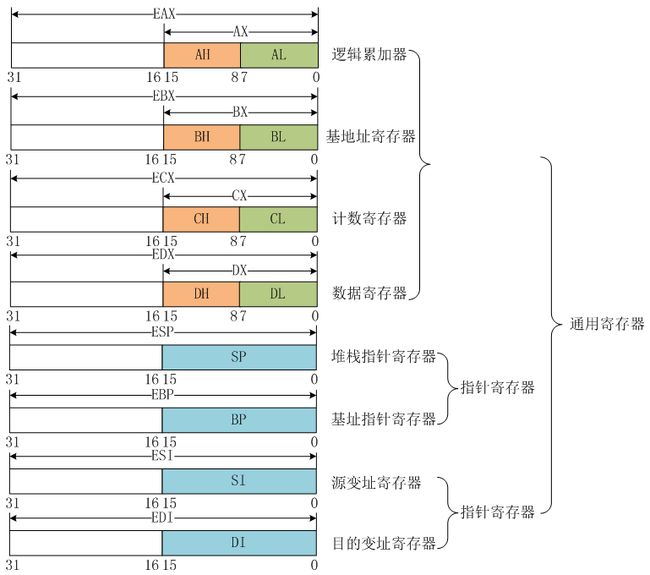
这里有些童鞋可能心里还在纠结,为啥要叫“通用寄存器”呢?这八个寄存器,除了它们自己本职的工作以外,还可以用来暂存和传送数据。也就是说当我们自己写底层汇编代码时可以用着几个寄存器来临时保存数据,然后实现我们特定的功能。以我们最熟悉的系统调用为例。在汇编层面,系统调用的实现机制和处理逻辑如下:
第一步,将系统调用号(不懂什么系统调用号请猛击这里)num暂存到eax寄存器:mov eax, num
第二步,将传递给系统调用的参数依次按顺序放到ebx,ecx,edx,esi,edi这些寄存器里;
第三步,触发0x80软中断,陷入内核执行系统调用:int 80h
第四步,函数的返回值保存在eax中。
亘古不变的例子“hello world”。我们用write系统调用向标准输出设备打印该字串:点击(此处)折叠或打开
- ;hello.asm
- section .data ;数据段开始
- msg db “hello,world!”,0xA; 定义要显示的字符串
- len equ $-msg; 定义字串长度,此操作后len的值就不能更改了
- section .text ;代码段开始
- global _start ;指定函数入口
- _start: ; write的系统调用号是4,其格式为write(fd,buf,buf_len)
- mov eax,4 ; 填充系统调用号到EAX寄存器
- mov ebx,1 ; 第一个参数,标准输出,其文件句柄为1。顺便普及一下,标准输入为0,标准错误为2。
- mov ecx,msg ; 第二个参数,缓冲区首地址。由我们的消息变量msg来传递。
- mov edx,len ;第三个参数,消息长度,由len变量传入。计算字符串msg长度时采用了一个小技巧”$-msg”。
- int 80h ;触发系统调用软件,接下来的任务都交给内核吧。
- ;程序退出,执行exit(0),它的代码就很容易写出了,其系统调用号是1。
- mov eax, 1 ; 填充系统调用号。
- mov ebx, 0 ; 返回码是0。
- int 80h ; 陷入内核
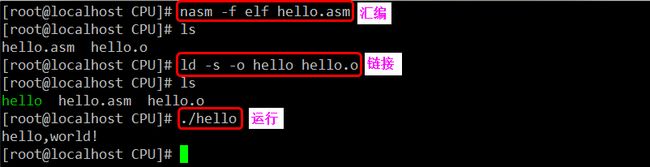
编译时我们用“-f elf”选项告诉NASM汇编器,我们要生成的elf格式的目标文件。这个例子应该可以确切解释了这些寄存器通用性的缘由了吧。
点击(此处)折叠或打开
- ; mul.asm
- extern printf,exit ; 我们在汇编中调用C库的printf和exit函数,所以要用extern关键字对printf和exit进行声明。
- SECTION .data ; 数据段
- var1: dd 40
- var2: dd 20
- fmt: db "result=%d", 10, 0 ; The printf format, "\n",'0'
- SECTION .text ; 代码段.
- global _start
- _start:
- mov eax, [var1] ; 乘数1
- mov ebx, [var2] ; 乘数2
- mul ebx ; 执行乘法运算,结果保存在EAX寄存器里。
- push eax ; result is here in EAX
- push dword fmt ; address of ctrl string
- call printf ; Call C function
- push dword 0
- call exit

EBX在寄存器间接寻址和查表时,一般是用来作为偏移地址使用。既然EBX里是偏移地址的值,那么根据80x86实模式的寻址机制“段地址:[BX]”。如果DS=1234H,BX=2H,则指令:
move ax,[ds:bx]
会将物理内存中数据段DS里偏移量是2字节的内存单元里的数据装载到ax寄存器里,这个没啥好说的。需要注意的是:如果指令中没有明确给出段地址的话,缺省情况下BX会使用数据段寄存器DS里的值。也就是说:
move eax,[ds:bx] move ax,[bx]
备注:上述代码在保护模式下运行会出现“段错误”,原因以后解释。
ECX寄存器
当在汇编指令中使用循环 LOOP 指令时,可以通过 ECX 来指定需要循环的次数。也就是说,如果你要在汇编中用LOOP循环指令时,CPU默认情况下会到ECX寄存器里去找循环的终止条件。也就是说 CPU 在每一次执行 LOOP 指令的时候,都会做两件事:一件就是令 ECX = ECX – 1,即令 ECX 计数器自动减去 1;还有一件就是判断 ECX 中的值,如果 ECX 中的值为 0 则会跳出循环,而继续执行循环下面的指令,当然如果 ECX 中的值不为 0 ,则会继续执行循环中所指定的指令 。如下,计算1+2+3+…+10的结果,中我们展示了ECX作为循环计数器的用法:
点击(此处)折叠或打开
- ; usage of ECX testecx.asm
- section .data
- output: db “result is %d”, 0ah
- extern printf,exit
- section .text
- global _start
- _start:
- mov ecx,10 ; 循环10次,每循环一次ECX寄存器的值减1
- mov eax, 0 ; 循环求和的结果保存在EAX里,所以初始化为0
- jcxz done ; 这句代码的作用是防止ecx初始被设置成0,执行循环时,EXC先减1,然后再判断ECX是否为0。如果一开始ECX就为0,那么减1后,就变成了-1,程序就会出问题。感兴趣的童鞋,可以将这句代码注释掉,并将ECX初始值设置为0看一下程序的执行结果。
- sum_label:
- add eax,ecx ; 将ECX寄存器里的值依次累加到EAX里
- loop sum_label; 循环跳转
- push eax ; 以下三行代码完成printf(“%dn”,eax)的调用
- push output
- call printf
- done:
- push 0 ; 以下两行代码完成exit(0)的调用
- call exit

点击(此处)折叠或打开
- ; another.asm
- section .data
- output db “result is %d”, 0ah
- extern printf,exit
- section .text
- global _start
- _start:
- mov ebx,10 ; 循环10次
- mov eax, 0 ; 循环求和的结果保存在EAX里,所以初始化为0
- sum_label:
- add eax,ebx ; 将ECX寄存器里的值依次累加到EAX里
- dec ebx ; 我们自己手动控制,将循环计数减1
- jz done ;如果ebx为0,则循环结束,准备打印输出结果
- jnz sum_label; 否则继续循环
- done:
- push eax ; 以下三行代码完成printf(“%dn”,eax)的调用
- push output
- call printf
- push 0 ; 以下两行代码完成exit(0)的调用
- call exit
这次循环时我们没用LOOP语句,而是自己用jnz和jz控制何时结束循环。结果一模一样,如下所示:

在寄存器间接寻址指令里,和 EBX 类似, EBP 也可以用于存储目标数据的段内地址的偏移量。这里有一点需要注意,那就是在寄存器间接寻址时,如果没有明确给出段基地址时, EBP默认的段地址使用的是堆栈段寄存器SS里的值 。例如:
点击(此处)折叠或打开
- mov ebx,0
- mov eax,[ebp] ;该指令意思是将SS:[EBX]代表的内存单元的值装入EAX寄存器
- move ax,[cs:ebx] ;该指令明确的段地址是代码段CS
这里有一点比较关键,那就是80x86中,在实模式下使用的16位寄存器来存放地址的偏移量,也就是说可以用于寄存器间接寻址的寄存器只有四个,分别是BX,BP,SI和DI。要尽量避免用BP寄存器,因为BP一般用于堆栈寻址,而不是数据寻址。在保护模式下,EAX,EBX,ECX,EDX,ESP,EBP,ESI和EDI都可用于寄存器间接寻址。
注意,前面说的约定“BX、SI和DI的默认段基址寄存器都是DS,BP的默认段基址寄存器是SS”都是针对实模式而言,在保护模式下,Linux对X86的处理是,6个段寄存器CS,DS,SS,ES,FS和GS的值分别是:FS=GS=0,ES=SS=DS,CS=CS,也就是说实模式和保护模式的寻址方式不一样。
2、专用寄存器EIP(IP): 是存放下次将要执行的指令在代码段的偏移量。在具有预取指令功能的系统中,下次要执行的指令通常已被预取到指令队列中,除非发生转移情况。所以,在理解它们的功能时,不考虑存在指令队列的情况。
前面我们知道 实模式下,由于每个段的最大范围为 64K ,所以, EIP 中的高 16 位肯定都为 0 ,此时,相当于只用其低 16 位的 IP 来反映程序中指令的执行次序。
EFLAGS(FLAGS):去google吧,我实在不想解释它了。
3、段寄存器
(留到内存管理部分再讲)
至于剩下的诸如在80386里增加的四个系统表寄存器, 全局描述符表寄存器(GDTR)、中断描述符表寄存器(IDTR)、局部描述符表寄存器(LDTR)、任务状态寄存器(TR) 】、四个控制寄存器CR0~CR3,以及80486和奔腾(新增CR4)架构新增的功能定义这里就不探究了,以后有用到时再说。
PS:最后还是忍不住吐槽一句,CU的编辑器能不能优化一下呢?每次写好博文,粘贴出来,调格式花了我1个多小时啊,1个多小时啊,唉~~~