一、Waitgroup介绍
1.1 背景
package main import ( "fmt" "time" ) func main() { ch := make(chan string) go sendData(ch) go getData(ch) time.Sleep(100 * time.Second) } func sendData(ch chan string) { ch <- "Washington" ch <- "Tripoli" ch <- "London" ch <- "Beijing" ch <- "Tokio" } func getData(ch chan string) { var input string for { input = <-ch fmt.Println(input) } }
会有一个问题,如果sleep时间都结束了,但是sendData和getdata所在的函数还没执行完,那么也会被中断执行,如何解决呢:
解决办法:
1、死循环:( 缺点:有时生产者和消费者已经执行完,却依然还在死循环,退不出。)
2、标识位,也就是全局变量和加锁(缺点:比较麻烦,如果有100个goroutine,也要写100个标识位)
上述2个办法都太麻烦不可取,可以pass掉了,下面我们有更好办法:
如何等待一组goroutine结束?
有下面2中方法,GO语言提供了2种方法Channel和WaitGroup来解决goroutine同步和通讯,我们还是比较推荐第二种WaitGroup
补充:
https://studygolang.com/articles/9173
1.2 方法一,使用不带缓冲区的channel实现
带缓冲区也是可以的
实例如下:
package main import ( "fmt" "time" ) func process(i int, ch chan bool) { fmt.Println("started Goroutine ", i) time.Sleep(2 * time.Second) fmt.Printf("Goroutine %d ended\n", i) ch <- true } func main() { no := 3 exitChan := make(chan bool, no) for i := 0; i < no; i++ { go process(i, exitChan) } for i := 0; i < no; i++ { <-exitChan } fmt.Println("All go routines finished executing") }
执行结果如下:

1.3 方法二,使用sync.WaitGroup实现
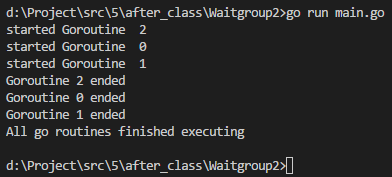
package main import ( "fmt" "sync" "time" ) func process(i int, wg *sync.WaitGroup) { fmt.Println("started Goroutine ", i) time.Sleep(2 * time.Second) fmt.Printf("Goroutine %d ended\n", i) wg.Done() } func main() { no := 3 var wg sync.WaitGroup for i := 0; i < no; i++ { wg.Add(1) go process(i, &wg) } wg.Wait() fmt.Println("All go routines finished executing") }
执行结果如下:
1.4 补充实例
1.4.1 方法1:channel
代码实例:
package main import ( "fmt" // "time" ) func main() { ch := make(chan string) exitChan := make(chan bool, 3) //此例我们有3个goroutine,所以我们定义一个长度为3的channel,当我的channel中可以读取到3个元素时,即表示3个goroutine都执行完毕了。 go sendData(ch, exitChan) //每一个goroutine执行结束时,往channel中插入一个数据 go getData(ch, exitChan) go getData2(ch, exitChan) //等待其他goroutine退出,当goroutine都执行完毕退出之后,channel中有3个元素,我们可以做一个取3次的操作,当3次都取完了,表示所有goroutine都退出了 <-exitChan //从channel中取出来元素并未赋值给任何变量,就相当于丢弃了 <-exitChan <-exitChan fmt.Printf("main goroutine exited\n") } func sendData(ch chan string, exitCh chan bool) { ch <- "aaa" ch <- "bbb" ch <- "ccc" ch <- "ddd" ch <- "eee" close(ch) //插入数据结束后,关闭管道channnel fmt.Printf("send data exited") exitCh <- true //此时已经往goroutine中插入数据结束,goroutine退出之前,往我们定义的channel中插入一个数据true,相当于告知我已经执行完成 } func getData(ch chan string, exitCh chan bool) { //var input string for { //input = <- ch input, ok := <-ch //检查管道是否被关闭 if !ok { //如果被关闭了,ok=false,我们就break退出 break } // 此处 打印出来的顺序 和写入的顺序 是一致的 // 遵循队列的原则: 先入先出 fmt.Printf("getData中的input值:%s\n", input) } fmt.Printf("get data exited\n") exitCh <- true } func getData2(ch chan string, exitCh chan bool) { //var input2 string for { //input2 = <- ch input2, ok := <-ch if !ok { break } // 此处 打印出来的顺序 和写入的顺序 是一致的 // 遵循队列的原则: 先入先出 fmt.Printf("getData2中的input值:%s\n", input2) } fmt.Printf("get data2 exited\n") exitCh <- true }
执行结果如下:

注意:当我们为channel中放入10个元素,然后把channel关闭,这些元素还是在channel中的,不会消失的,之后想取还是可以取出来的。
1.4.2 方法2:Waitgroup(推荐)
针对大批量goroutine,用sync包中的waitGroup方法,其本身是一个结构体,该方法的本质在底层就是一个计数。
代码实例如下:
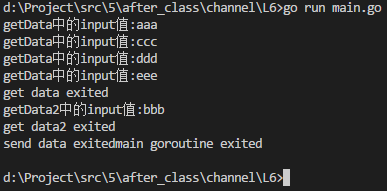
package main import ( "fmt" "sync" // "time" ) func main() { var wg sync.WaitGroup //定义一个waitgroup(结构体)类型的变量,针对大批量goroutine时比较方便。 ch := make(chan string) wg.Add(3) //3个goroutine,就传入3,Add方法相当于计数 go sendData(ch, &wg) //,相当于goroutine执行完,Add计数就减1,所以我们将wg传入,但注意结构体必须要传入一个地址进去 go getData(ch, &wg) go getData2(ch, &wg) wg.Wait() //只要Add中计数依然存在,就一直Wait,除非为0 fmt.Printf("main goroutine exited\n") } func sendData(ch chan string, waitGroup *sync.WaitGroup) { ch <- "aaa" ch <- "bbb" ch <- "ccc" ch <- "ddd" ch <- "eee" close(ch) fmt.Printf("send data exited") waitGroup.Done() //goroutine退出时,计数减1,所以这里用Done方法来通知Add方法 } func getData(ch chan string, waitGroup *sync.WaitGroup) { //var input string for { //input = <- ch input, ok := <-ch if !ok { break } // 此处 打印出来的顺序 和写入的顺序 是一致的 // 遵循队列的原则: 先入先出 fmt.Printf("getData中的input值:%s\n", input) } fmt.Printf("get data exited\n") waitGroup.Done() } func getData2(ch chan string, waitGroup *sync.WaitGroup) { //var input2 string for { //input2 = <- ch input2, ok := <-ch if !ok { break } // 此处 打印出来的顺序 和写入的顺序 是一致的 // 遵循队列的原则: 先入先出 fmt.Printf("getData2中的input值:%s\n", input2) } fmt.Printf("get data2 exited\n") waitGroup.Done() }
执行结果如下:
二、原子操作
主要还是为了解决线程安全的问题。
2.1 介绍
A. 加锁代价比较耗时,需要上下文切换
B. 针对基本数据类型,可以使用原子操作保证线程安全
C. 原子操作在用户态就可以完成,因此性能比互斥锁要高
D.针对特定需求,原子操作一步就可以操作完成,而加锁就需要好几步(加锁-操作-解锁)
2.2 适用范围
原子操作适用于一些简单操作的数据类型,对于复杂数据类型还是需要借助锁。

2.3 实例
有计数的需求,可以采用原子操作;
package main import ( "fmt" "sync/atomic" //原子操作需要借助aync中的atomic包 "time" ) var count int32 //var mutex sync.Mutex func test1() { for i := 0; i < 1000000; i++ { /* 注释掉的这部分是如果采用加锁操作写法 mutex.Lock() count++ mutex.Unlock() */ atomic.AddInt32(&count, 1) //AddInt32函数的第一个参数是传入要修改的变量的地址,第二个参数是要加多少,这样我们就可以借助原子进行操作,而不是加锁了。 } } func test2() { for i := 0; i < 1000000; i++ { /* 注释掉的这部分是如果采用加锁操作写法 mutex.Lock() count++ mutex.Unlock() */ atomic.AddInt32(&count, 1) } } func main() { go test1() go test2() time.Sleep(time.Second) fmt.Printf("count=%d\n", count) }
执行结果:

解释:
我们可以发现最终结果是2000000,证明在不加锁状态下,依靠原子操作也实现了线程安全。