网络传输过程中的字节序列问题
一、大端存储和小端存储
1、大端存储:多于一个字节的数据,把高字节部分存储在低地址,把低字节部分存储在高地址。
例:0x12345678这个数据,我们一般认为左边是高字节部分,右边是低字节部分,那么在采用大端存储的计算机内部的存储则为下面这样
低地址: 0x12(高字节)
>>>>>: 0x34
>>>>>: 0x56
高地址: 0x78(低字节)
即一个整型数据的首地址=高位部分(首地址=低地址)
目前使用大端存储的厂商主要有:IBM、Motorola和Sun Microsystems公司的大多数微处理器采用大端存储法。
2、小端存储:多于一个字节的数据,把高字节部分存储在高地址,把低字节部分存放在低地址。
例:0x12345678这个数据,我们一般认为左边是高字节部分,右边是低字节部分,那么在采用小端存储的计算机内部的存储则为如何下这样
低地址: 0x78(低字节)
>>>>>: 0x56
>>>>>: 0x34
高地址: 0x12(高字节)
即首地址部分=低位部分(首地址=低地址)
目前使用小端存储的厂商主要有:intel
其他的一些厂商如ARM、 MIPS和Motorola的PowerPC等,可以通过芯片上电启动时确定的 字节存储顺序规则,来选择存储模式。
二、网络字节序
1、目前网络中的体系采用TCP/IP协议,TCP/IP协议规定对于多字节数据,采用大端存储。
另外,TCP/IP协议规定:接收方接收到的第一个字节是高字节,存储到低地址。那么由于网络TCP/IP协议 从低地址部分开始发送字节数据,所以可以知道,网络字节序列 采用的大端存储。
2、同一存储模式之间传送数据
(1)、同为小端存储的双方通信
小端存储,发送方从低地址开始传送(低地址实际上是低字节部分,按照网络字节序来说,这个取的高字节),然后接收方把接收到的数据存储在低地址部分(接 收到的直接是数据的低字节部分,并存储在低地址上,符合小端存储。但是网络字节序来说,作为高字节),通信双方并没有把本机字节序转为网络字节序,但是 依然完成了数据的正确发收。大端存储也一样。可见同一存储模式的双方并不需要进行字节序列的转换。
(2)、小端和大端模式之间的通信
小端存储作为发送方,若直接发送,则把数据的低地址发送出去(实际发送的是数据的低字节),大端存储接收,把这个数据存储在低地址,(接收到的是低字 节,但是由于是大端存储模式,所以平台认为是高字节),这样就导致了数据的错误收发。那么在不同存储模式之间进行通信,我们就需要进行字节序列的转换, 通常,只需要一次转换即可,一般都是将小端转换为大端,因为网络字节序采用大端模式。
(3)、通信双方是否应该转换
由于我们不清楚收发双方是什么存储模式,所以在发送时,都应该将本机字节序转为网络字节序,然后,作为接收方,都应该将网络字节序转为本机字节序列然后 在进行存储。
三、如何判断机器的大端和小端?
主要原理:我们知道大端存储和小端存储主要是针对超过一个字节的数据而言的,那么对于字节型数据在各平台的存储都是一样的,都是按照地址进行顺序排列存储的,一般都是从低地址往高地址进行排列。同时,我们说通过指针获取一个数据类型的地址,通常也都是获取的该数据的起始地址,即低地址。
以下实验在我的x86机器上进行实验,所以应该是
方法一、采用不同指针类型unsigned int和char指针类型指向同一整数类型
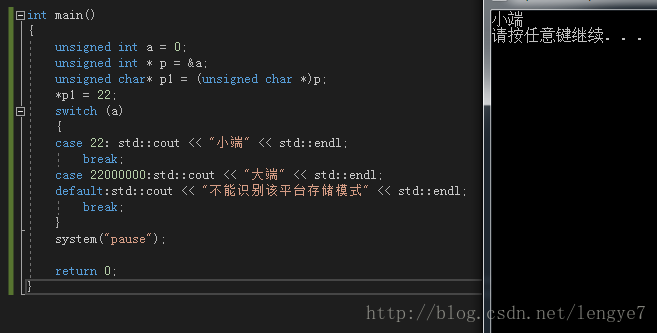
//写法一:往一整型数据0的起始地址写入一字节的数据,如果为小端,则该字节数据应该等于该整型数据。如果为大端,则该字节的数据应该刚好为该整型数据的高位部分。如写入22,如果为小端,则该整型数据应该等于22。如果为大端,则该整型数据应该等于22000000。 #include "stdafx.h"
#include
int main()
{
unsigned int a=0;
unsigned int * p = &a;
unsigned char* p1 = (unsigned char *)p;
*p1 = 22;
switch (a)
{
case 22: std::cout << "小端" << std::endl;
break;
case 22000000:std::cout << "大端" << std::endl;
default:std::cout << "不能识别该平台存储模式" << std::endl;
break;
}
system("pause");
return 0;
}
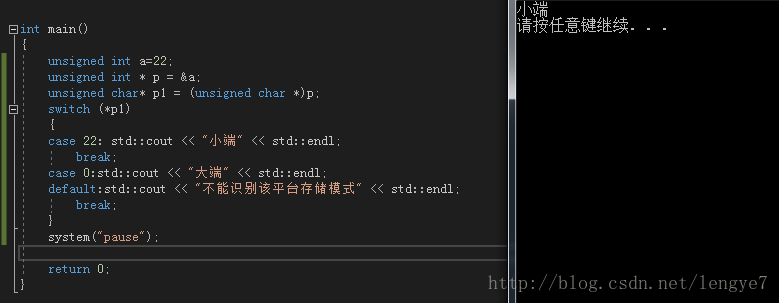
//写法二:读出整数类型的起始地址的一字节数据,如果为小端,则该字节应该等于该整数的低位部分。如果为大端,则该字节应该等于该整数的高位部分。 如22,如果为小端,则该字节应该等于22。 ruguo果为大端,则该字节应该等于0。 #include "stdafx.h"
#include
int main()
{
unsigned int a=22;
unsigned int * p = &a;//获取a的首地址
unsigned char* p1 = (unsigned char *)p;
switch (*p1)
{
case 22: std::cout << "小端" << std::endl;
break;
case 0:std::cout << "大端" << std::endl;
default:std::cout << "不能识别该平台存储模式" << std::endl;
break;
}
system("pause");
return 0;
} 
方法二、利用联合体的共享内存的方式来判定
#include "stdafx.h"
#include
union MyUnion
{
char str;
unsigned int data;
}; //str和data共享内存,其中str与data的低地址的第一个字节相同,即str=data的首地址。
int main()
{
union MyUnion a;
a.data = 0x12345678;
switch (a.str) //获取到了data的首地址部分的值
{
case 0x78: std::cout << "小端" << std::endl; //首地址=低位部分,则为小端
break;
case 0x12:std::cout << "大端" << std::endl; //首地址=高位部分,则为大端
default:std::cout << "不能识别该平台存储模式" << std::endl;
break;
}
system("pause");
return 0;
} 
方法三、LINUX内核开发者的代码,原理也是利用union的共享内存机制
1 static union { char c[4]; unsigned long mylong; } endian_test = {{ 'l', '?', '?', 'b' } };
2 #define ENDIANNESS ((char)endian_test.mylong) //强制转换,截断,取mylong的低位部分。如果是小端,则低位部分应该为‘l’。如果为大端,则低位为‘b’。
3 cout<>>>>>>> ?
>>>>>>> ?
低地址 >>>>>>> l 低位部分
内存分布(大端): 高地址 >>>>>>> b 低位部分
>>>>>>> ?
>>>>>>> ?
低地址 >>>>>>> l 高位部分
最后总结一下需要进行大小端转换的一些数据类型:
我们知道大小端存储问题只会出现在超过一个字节的数据类型之中,那么针对常用数据类型
以下数据类型需要进行转换:
整数类型、浮点型
注意:字符和字符串类型不需要进行转换,因为他们是单字节编码的数据类型,在计算机中都是一个字节为单位进行存放的。
另外unicode的字符如果使用utf-8编码则不需要转换,因为UTF-8编码也是单字节编码。如果是utf-16编码则根据big和Little的来确定是否需要转换,如果是Big则不需要转换,如果是little则需要转换。在网络传输中,我们最好采用utf-8编码,这样可以完全保证传输的正确性。
大小端转换只在跨大小端平台进行传输的时候,我们才需要进行转换,如果不跨平台,则不需要转换,目前来说,Client端基本都是x86体系,如果服务器也是x86体系的,不用转换也不会出现问题。