【数据结构与算法】之单链表、双链表、循环链表的基本介绍及其Java代码实现---第三篇
博主秋招提前批已拿百度、字节跳动、拼多多、顺丰等公司的offer,可加微信:pcwl_Java 一起交流秋招面试经验,可获得博主的秋招简历和复习笔记。
一、链表的基本介绍
链表的定义:链表是一种递归的数据结构,它或者为空(null),或者是指向一个结点(node)的引用,该结点含有一个泛型的元素和一个指向另一条链表的引用。----Algorithms Fourth Edition
常见的链表结构有:单链表、双向链表和循环链表,下面我们对其分别介绍:
1、单链表
单链表是链表中最简单的一种数据结构,我们先来看下一张单链表的存储原理图:

从图中可以看出来,每个链表的结点除存储数据之外,还需要记录它下一个结点的地址,我们一般把这个记录下一个结点的指针叫做后继指针,用next表示。但是需要注意的是单链表有两个比较特殊的结点:第一元素结点和尾结点。【往往会为了操作的统一性在第一元素结点前加上一个头结点(下文会讲解)】需要注意的是尾结点的指针域为null。
学习中对头指针和头结点这两个概念一直很迷糊,后来在翻阅《大话数据结构》一书,上面对两者进行了明确的区分:
| 头指针 | 1.头指针是指链表指向第一个结点的指针,若链表有头结点,则指向头结点的指针; 2.头指针具有标识作用,所以常用头指针冠以链表的名字; 3.无论链表是否为空,头指针均不为空。头指针是链表的必要元素。 |
| 头结点 | 1.头结点是为了操作的统一性和方便而设立的,放在第一元素的结点之前,其数据域一般无意义(也可存放链表的长度); 2.有了头结点,对在第一元素结点前插入和删除第一节点,其操作与其他结点的操作就统一了; 3.头结点不一定是链表的必须要素。 |
和数组相比:链表因为有指针的存在,所以不需要连续的存储空间,而数组则需要连续的存储空间。除此之外他们在插入、删除和随机访问结点操作的时间复杂度正好相反。如下表所示,具体的分析很简单,这里就不再解释了。
| 数组 | 链表 | |
|---|---|---|
| 插入删除 | O(n) | O(1) |
| 随机访问 | O(1) | O(n) |
单链表的插入操作:
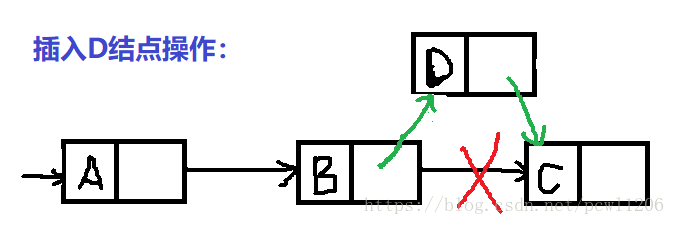
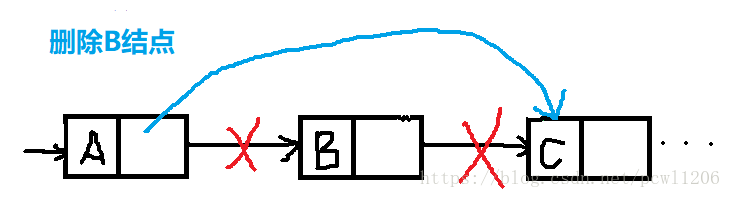
单链表的删除操作:
2、双向链表
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中任意一个结点开始,都可以很方便访问它们的前驱结点和后继结点。
双向链表比单链表在一些特定的插入和删除操作情况下要简单和高效。在单链表中,每个结点只有一个指向后继结点的指针next,但是如果现在要查找当前结点的前驱结点,对于单链表来说,就必须从头指针遍历至当前结点的前驱结点,可见其操作效率很低,因此双链表的出现解决了这个问题,它的一个结点中既包含前驱结点prev又包含继结点next,所以既可以双向查找。
(具体特定情况参考:参考1)

双向链表的插入操作:
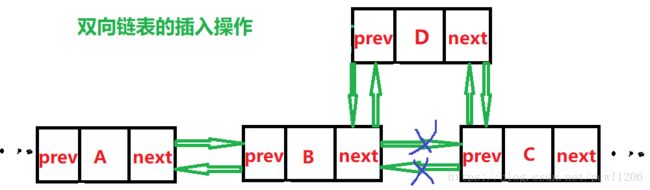
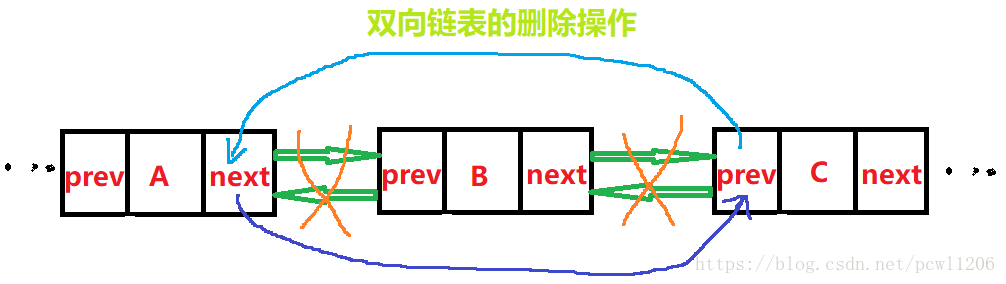
双向链表的删除操作:
3、循环链表
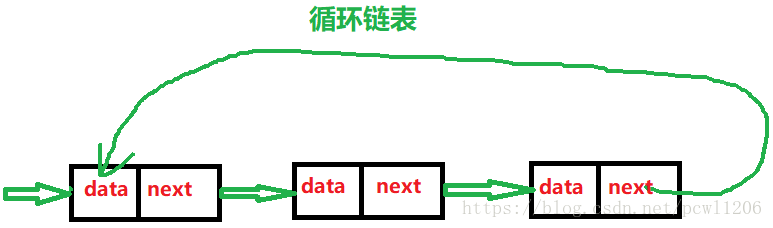
循环链表是一种特殊的单链表,它跟单链表唯一的区别在于尾结点,单链表的尾结点指向空地址,而循环链表的尾结点指针指向链表的头结点,直接上图:
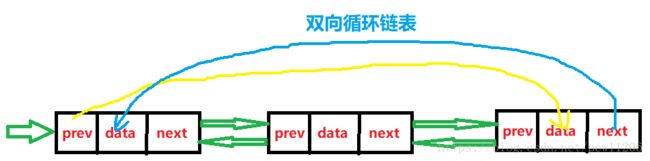
由双向链表和循环链表组合成双向循环列表,如下图所示:
二、链表的实现
1、单链表的Java实现
// 结点类
class Node{
protected Node next; // 指针域,next指向的是当前结点的下一个结点,所以是Node类型
protected int data; // 数据域
public Node(int data){
this.data = data;
}
// 显示结点
public void display(){
System.out.print(data + "、");
}
}
// 创建单链表
public class LinkList {
private Node first; // 定义头结点,需要注意的是,为了方便,这里把第一个存放数据的结点称为头结点,实际上,头结点是不存放数据的
private int pos = 0; // 结点的位置
public LinkList(){
this.first = null; // 初始化的时候头结点为空
}
// 在头节点位置插入一个结点
public void addFirstNode(int data){
Node node = new Node(data); // 创建一个新结点
node.next = first; // 将新结点的指针域指向以前的头结点
first = node; // 将新结点设置为头结点
}
// 删除一个头结点,并且返回该头结点
public Node deleteFirstNode(){
Node tempNode = first; // 先将头结点标记为临时结点
first = tempNode.next; // 将头结点的下一个结点设置为头结点
return tempNode;
}
// 在任意位置插入结点,插入到index的位置,等于说找到current的位置,用新插入的结点替换
public void add(int index, int data){
Node node = new Node(data); // 创建一个新结点
Node current = first; // 从头结点开始查找index
Node previous = first; // 用来记住当前结点的上一个结点
while(pos != index){
previous = current; //如果当前位置不等于index,那么就让标记为current和previous的结点挨个结点往后查找,直到pos=index
current = current.next;
pos++;
}
// 其实pos记录的就是current的位置,因为在循环里可以看出current每往后挪一个位置的时候,pos就会自增一次
// 因此要在index后面插入新结点,即要在current后面插入
node.next = current;
previous.next = node;
pos = 0;
}
// 删除任意位置的结点
public Node deleteByPos(int index){
Node current = first;
Node previous = first;
while(pos != index && current.next != null){
previous = current;
current = current.next;
pos++;
}
if(current == first){
first = first.next;
}else{
pos = 0;
previous.next = current.next;
}
return current;
}
// 按data值删除结点(如果有多个相同值,只删除第一个)
public Node deleteByData(int data){
Node current = first;
Node previous = first;
while(current.data != data){
if(current.next == null){
return null; // 如果current.next == null,说明current已经是最后一个结点了
}
previous = current; // 这两句是沿着链表中的结查找的过程
current = current.next;
}
if(current == first){
first = first.next; // 如果是头结点,则删除头结点
}else{
previous.next = current.next; // 将current的指针域赋值给它前一个结点previous
}
return current;
}
// 显示出所有结点的信息
public void displayAllNodes(){
Node current = first;
while(current != null){
current.display();
current = current.next;
}
System.out.println();
}
// 根据位置查找结点
public Node findNodeByPos(int index){
Node current = first;
while(pos != index){
current = current.next; // 遍历
pos++;
}
pos = 0; // 这个位置必须将pos重置为0,不然下次操作会从上次的位置开始,这样pos和结点真实的位置就错乱了
return current;
}
// 根据值查找结点
public Node findNodeByData(int data){
Node current = first;
while(current.data != data){
if(current.next == null){
return null; // 没找到,该data不在链表中
}
current = current.next;
}
return current;
}
}
测试代码:
public class TestLinkList {
public static void main(String[] args) {
LinkList linkList = new LinkList();
// 要区分开在头结点和任意节点上插入结点的方法是不同的,在头结点处插入新结点只能使用它自己的方法,因为它比较特殊,没有前继节点
linkList.addFirstNode(6); // 在第一个结点上插入值, 头结点的pos=0;
linkList.addFirstNode(9);
linkList.addFirstNode(8); // 8 9 6
// 根据index插入结点
linkList.add(1, 12); // 8 12 9 6
linkList.add(2, 35); // 8 12 35 9 6
linkList.add(3, 86); // 8 12 35 86 9 6
System.out.println("==============创建结点===============");
// 显示结点
linkList.displayAllNodes();
System.out.println("==============根据位置查找结点===============");
// 根据位置查找结点
Node pos1 = linkList.findNodeByPos(1);
Node pos4 = linkList.findNodeByPos(4);
System.out.println("pos1的值为" + pos1.data); // 12
System.out.println("pos4的值为" + pos4.data); // 9
System.out.println("================根据值查找结点===============");
// 根据值查找结点
Node node8 = linkList.findNodeByData(8);
Node node86 = linkList.findNodeByData(86);
// 验证一下,获取的结点值是否正确
System.out.println(node8.data); // 8
System.out.println(node86.data); // 86
System.out.println("===============根据位置删除结点==============");
// 按位置删除结点
Node node3 = linkList.deleteByPos(3);
Node node5 = linkList.deleteByPos(5);
linkList.displayAllNodes(); // 8 12 35 9
System.out.println("===============根据值删除结点==============");
// 按照值删除结点
linkList.deleteByData(8);
linkList.deleteByData(9);
linkList.displayAllNodes(); // 12 35
}
}
2、双链表的Java实现
双链表的主要优点是对于任意给定的结点,都可以很容易的获得其前驱结点和后继结点,而主要缺点是每个结点需要添加额外的prev域,因此需要更多的空间开销(空间换时间),同时结点的插入与删除操作也变得更加复杂与耗时,因为需要更多的指针指向操作。下面引用数据结构之双向链表的实现中的部分代码,对其中的代码做了调整。为了操作方便,将头结点与尾结点建立了指针关系,所以实际上实现的是双向循环链表,具体代码如下:
public class DoubleLinkList {
// Node也可以作为内部类
private static class Node{
Object value; // 结点里存入的信息
Node prev = this; // 前驱结点
Node next = this; // 后继结点
Node(Object obj){
value = obj;
}
@Override
public String toString(){
return value.toString();
}
}
private Node head = new Node(null); // 头结点
private int size; // 链表大小
// 在第一个元素结点位置插入新结点
public boolean addFirst(Object obj){
addAfter(new Node(obj), head);
return true;
}
// 将元素添加到链表表尾,注意头结点的前驱指针指向尾结点,尾结点的后继指针指向头结点
public boolean addLast(Object obj){
addBefore(new Node(obj), head);
return true;
}
// 插入结点,默认都是插到尾结点的位置
public boolean add(Object obj){
return addLast(obj);
}
// 在某元素之后插入节点
private void addAfter(Node newNode, Node node) {
newNode.prev = node; // 将newNode的前驱指针指向node结点
newNode.next = node.next; // 将newNode的后继指针指向node的后继指针指向的结点
newNode.next.prev = newNode; // 新结点插入后,将其后面的结点的前驱指针指向newNode
newNode.prev.next = newNode; // 将node的结点的后继指针指向newNode,此时node是newNode的前驱结点
size++;
}
// 在某元素之前添加元素
private void addBefore(Node newNode, Node node){
newNode.next = node; // 将newNode的后继指针指向node
newNode.prev = node.prev; // 将newNode的前驱指针指向node的前驱指针指向的结点
newNode.next.prev = newNode; // 将newNode后面的结点(node)的前驱指针指向newNode
newNode.prev.next = newNode; // 将newNode前面的结点的后继指针指向newNode
size++;
}
// 将元素添加到指定位置
public boolean addNodeByIndex(int index, Object obj){
addBefore(new Node(obj), getNodeByIndex(index));
return true;
}
// 查找指定元素
public Node getNodeByIndex(int index){
if(index < 0 || index >= size){
throw new IndexOutOfBoundsException();
}
Node node = head.next; // 从表头开始遍历查找
for(int i = 0; i < index; i++){
node = node.next; //当i=node-1的时候,node.next就是index处的结点
}
return node;
}
// 删除指定位置的元素
public boolean deleteNodeByIndex(int index){
deleteNode(getNodeByIndex(index));
return true;
}
// 移除特定元素
private void deleteNode(Node node){
node.next.prev = node.prev; // 将node的后一个结点的前驱指针指向node的前一个结点
node.prev.next = node.next; // 将node的前一个结点的后继指针指向node的后一个结点
node.prev = null; // 将node的前驱指针设为空
node.next = null; // 将node的后继指针设为空
size--;
}
// 移除第一个元素结点
public boolean deleteFirstElementNode(){
deleteNode(head.next); // 只有第一个元素结点才可以直接用head.next移除,其他都要先遍历找到,才能删除
return true;
}
// 移除链表表尾元素
public boolean deleteLastNode(){
deleteNode(head.prev);
return true;
}
// 获取指定位置元素
public Object get(int index){
return getNodeByIndex(index).value;
}
// 返回链表的大小
public int size(){
return size;
}
public String toString(){
StringBuffer sb = new StringBuffer("【");
Node node = head;
for(int i = 0; i < size; i++){
node = node.next;
if(i > 0){
sb.append(", ");
}
sb.append(node.value);
}
sb.append("】");
return sb.toString();
}
}
测试代码:
public class TestDoubleLinkList {
public static void main(String[] args) {
DoubleLinkList dll = new DoubleLinkList();
// 插入结点
dll.add("A");
dll.add("B");
dll.add("C");
String dllString = dll.toString();
System.out.println(dllString); // A B C
// 在第一个元素位置添加结点
dll.addFirst("D"); // A B C D
System.out.println(dll); // 重写了toString()方法后,直接syso会调用重写的方法
// 在最后一个位置上添加结点
dll.addLast("E");
System.out.println(dll); // A B C D E
// 添加到指定位置
dll.addNodeByIndex(4, "F"); // 需要注意的是第一个元素结点的index为0
System.out.println(dll);
// 删除第一个元素结点
dll.deleteFirstElementNode();
System.out.println(dll);
// 删除最后一个结点
dll.deleteLastNode();
System.out.println(dll);
// 删除指定位置上的元素
dll.deleteNodeByIndex(2);
System.out.println(dll);
// 获取指定位置上的元素
System.out.println(dll.get(1));
}
}
双链表与双向循环双链表的实现区别在于:插入和删除尾结点的不同,双链表中的尾结点的后继指针为null,并且头结点的前驱指针也为null;而双向循环链表的尾指针指向头结点,头结点的前驱指针指向尾结点,形成环路。所以在执行插入和删除操作时在指针操作方面有所不同,需要稍加区分。
感想:1、对于这类数据结构的实现过程,最好画出图进行分析,不然指针指来指去很容易就迷糊了。
2、对于数据结构,刚开始接触会有点难理解,特别是一些边界位置,但是只要坚持看下去,多写代码。哪怕是看不懂,抄别人的代码,看的多了,练习的多了,自然就会领悟其中的精髓了。
3、所以我现在还处于抄+改的阶段,希望勤加练习,能够将数据结构逐个攻破!
参考及推荐:
1、用java简单的实现单链表的基本操作
2、Java单链表、双端链表、有序链表实现
3、链表的原理及java实现【推荐阅读***】
4、java数据结构与算法之顺序表与链表深入分析【推荐阅读***】
5、java数据结构与算法之双链表设计与实现【推荐阅读】
6、JAVA实现双向链表终极解析、数据结构之双向链表
学习不是单打独斗,如果你也是做Java开发,可以加我微信:pcwl_Java,一起分享经验学习!