Java课设——ArxivHelper
项目地址https://github.com/PKUCSS/arxiv-helper
How to run运行方式:java -jar arxiv-helper.jar
Tips:We use pyinstaller to export the exe application from the jar package, but the test performance is unstable in different environments. Please understand that we will continue to improve and make it easy for all users to click and use.
提示:我们用pyinstaller从jar包导出的exe应用程序,但目前在不同环境下测试表现不稳定,敬请谅解,我们还会继续改善,方便所有用户即点即用。

Authors作者
Sishuo Chen,Chonghao Zhai,Zihan,undergraduate students from Peking University,China
Introduction简介
arXiv.org is an electronic preprinted documentary library funded by the National Science Foundation and the US Department of Energy at the Los Alamos (Los Alamos) National Laboratory. It was founded in August 1991 by Dr. 2001. After the year, it was transferred to Cornell University (Cornell University) for maintenance and management. arXiv is the earliest preprint library. There are currently 17 mirror sites around the world. arXiv.ORG involves mathematics, physics, computers, nonlinear science, Quantitative biology, quantitative finance, and several major categories of statistics. Its most important feature is “open access”, which everyone can get for free. Because of the lack of space, arXiv.org’s articles contain more information. Preprints have long replaced traditional research journals in certain areas of physics.
arXiv.org是由美国国家科学基金会和美国能源部资助,在美国洛斯阿拉莫斯(Los Alamos)国家实验室建立的电子预印本文献库,始建于1991年8月,由Dr. Ginsparg发起,旨在促进科学研究成果的交流与共享。2001年后转由康奈尔大学(Cornell University)进行维护和管理。arXiv是最早的预印本库,目前世界各地有17个镜像站点。arXiv.org涉及数学,物理、计算机、非线性科学、定量生物学、定量财务以及统计学几大分类。其最重要的特点就是“开放式获取”,每个人都可以免费地获取。由于不受篇幅限制,arXiv.org的文章含有更多信息,预印本在物理学的某些领域,它们早已替代传统的研究期刊。
In the process of using arxiv to retrieve and read papers every day, we found that the user experience of arxiv is not very good, lacking personalized functions such as collection, recommendation, download management, etc., and PDF files can only be downloaded through the browser if they are not downloaded. Reading, when the file name is downloaded, the ID number is unknown, and the experience is poor. Therefore, we completed a Java course project called Arxiv Helper, hoping to help researchers better search and read academic resources and promote the exchange and dissemination of knowledge.
在日常使用arxiv检索和阅读论文的过程中,我们发现arxiv的用户体验并没有做到很好,缺乏收藏、推荐、下载管理等个性化功能,同时PDF文件不下载的话也只能通过浏览器在线阅读,下载时文件名是不明含义的ID编号,体验较差。因此,我们完成了名为Arxiv Helper 的Java课设项目,希望能帮助科研工作者更好地检索和阅读学术资源,促进知识的交流和传播。
Functions功能
Arxiv’s latest articles in various fields, based on title/author/domain/summary/full-text search function, online reading and download management, user system based on LeanCloud platform, can realize remote login, access to favorites, reading records, etc. Information, a recommendation system based on text similarity calculations.
Arxiv各领域的最新文章获取,基于标题/作者/领域/摘要/全文的搜索功能,论文在线阅读及下载管理,基于LeanCloud平台的用户系统,可以实现异地登录,访问收藏夹、阅读记录等个性化信息,基于文本相似度计算的推荐系统。
Structure架构
This project uses maven build, Eclipseb encoding, version management using git, project address is https://github.com PKUCSS/arxiv-helper. We specify external dependencies in the pom file, using the crawler package Jsoup, the user system management platform LeanCloud, and the graphical interface package JavaFX third-party tools. The class that implements the project function is in the src/main/java folder, which has User (user), paper (paper), Promoter (recommended system), UIEngine (graphical interface), PDFViewer (pdf reader), Main (main program). Wait
本项目使用maven构建,Eclipseb编码,使用git做版本管理,项目地址为https://github.com PKUCSS/arxiv-helper。我们在pom文件中指定外部依赖,使用了爬虫包Jsoup、用户系统管理平台LeanCloud、图形界面包JavaFX第三方工具。实现项目功能的类在src/main/java文件夹中,有User(用户)、paper(论文)、Recommender(推荐系统)、UIEngine(图形界面)、PDFViewer(pdf阅读器)、Main(主程序)等
Data数据
This project uses Jsoup to obtain paper data from the official Arxiv API. The paper class contains updated (update time), published (release time), authors (author), summary (summary), pdflink (PDF link), categories (domain) and other information. . The search function is implemented in the search class. There are search prefixes (by title/by author/by summary), sort keywords (correlation, release time), and positive sequence reverse order. After building the url, use Jsoup to get the source code of the webpage. Parse out the paper information and return to the paper list.
本项目使用Jsoup从Arxiv官方API获取论文数据,paper类包含updated(更新时间)、published(发布时间)、authors(作者)、summary(摘要)、pdflink(PDF链接)、categories(所属领域)等信息。搜索功能在search类中实现,有搜索前缀(按标题/按作者/按摘要)、排序关键字(相关度、发布时间)、正序逆序等参数,构建出url后用Jsoup获取网页源代码,解析出paper的信息并返回paper列表。
UIDesign图形界面
Graphical interface part: This project uses the javafx programming language to develop a graphical interface and uses SceneBuilder to assist in design. Although the time hastily, there is not much energy spent on the art, but this graphical interface strives to cooperate with all the achievable functions of the background data acquisition and user management system, basically the functions are comprehensive, the interface is simple, the paper is readable, and the structure is complete. Better to meet the characteristics of the paper search needs and other characteristics. In addition, this interface also gives tips for use in places where necessary, making it easier for users to get started and solving many problems with current paper search software.
图形界面部分:本项目使用javafx编程语言开发图形界面,并用SceneBuilder辅助设计。虽因时间仓促,在美工上没有花费太多精力,但本图形界面力求配合后台数据获取与用户管理系统所有可实现功能,基本做到功能全面、界面简洁、论文可读性强、结构完整、较好满足论文搜索需求等多个特性。除此之外,本界面还在必要的地方给出了使用提示,使用户更易上手操作,解决了很多目前论文搜索软件的问题。

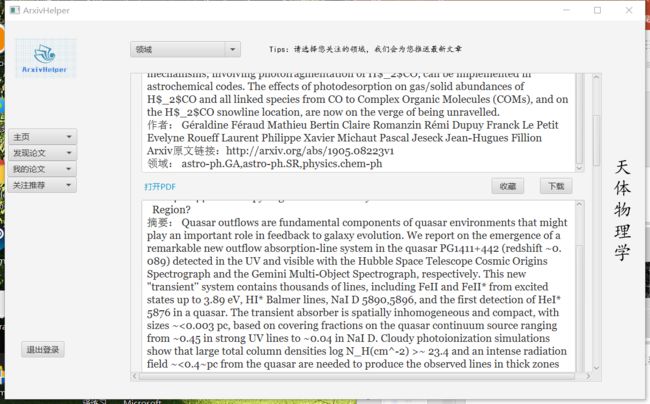
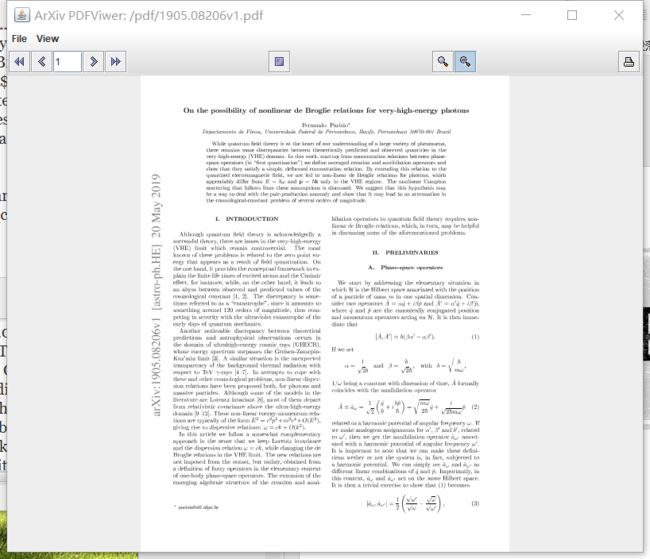
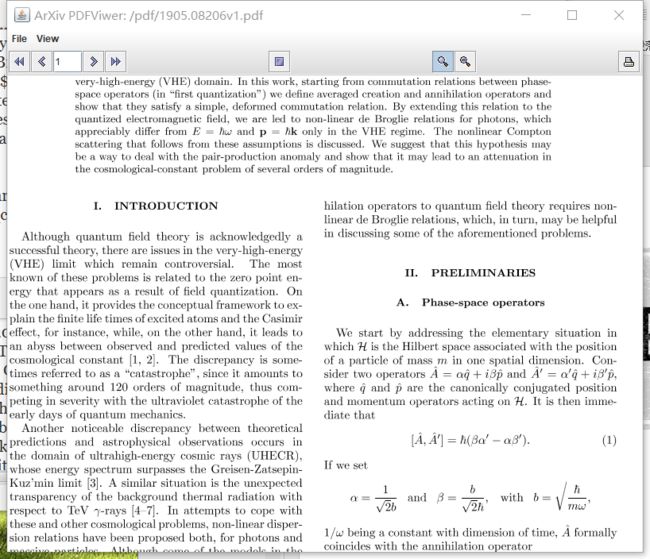
PDFViewer阅读器
In order to solve the problem that JavaFX’s WebEngine component can’t load pdf files, a simple pdf reader is built using Swing graphical interface and AWT component to realize the online opening of PDF and opening local pdf function of given URL through PDFViewer class. A variety of different responses are made based on user actions, which basically meets all possible needs of the user. And the simple interface brought by the characteristics of the Swing component also reduces the difficulty of the user. The function of setting the reading interface is to satisfy the different preferences of the user when reading the thesis in the easiest way. In order to deal with the problem of slow loading, we also added a caching module to load the number of pages to be read in advance to get a more enjoyable reading experience.
为了解决JavaFX的WebEngine组件不能加载pdf文件的问题,使用Swing图形界面和AWT组件搭建了一个简易的pdf阅读器来通过PDFViewer类实现了在线打开给定URL对应的PDF和打开本地pdf功能,并可以根据用户动作做出多种不同响应,基本可以满足用户的所有可能的需求。且Swing组件本身特性带来的简洁界面也降低了用户的使用难度,可以设置阅读界面的功能更是以最简便的方式满足了用户读论文时的不同自身偏好。为了应对加载缓慢的问题,我们还增加了缓存模块,提前加载好将要阅读的页数,获得更畅快的阅读体验。
User System用户系统
The user system is built based on the LeanCloud platform, and functions such as user registration, mailbox verification, and password recovery are implemented. The user’s password and reading records, collection papers and other personalized information are encrypted and stored in the cloud, which has strong security and practicality.
基于LeanCloud平台搭建了用户系统,实现了用户注册、邮箱验证、找回密码等功能。用户的密码和阅读记录、收藏论文等个性化信息都经过加密存储在云端,具有很强的安全性和实用性。


Recommending Strategy 推荐策略
The text similarity calculation is based on the Jaro-Winkler Distance, and the 25 most similar recommendations to the most recently read papers are selected from the latest papers in the user’s field of interest.
基于Jaro-Winkler Distance进行文本相似度计算,从用户关注领域的最新论文中选取与最近阅读论文最相似的25篇推荐给用户。
Future Works未来的工作
Improve PDF readers, improve recommendation strategies, beautify graphical interfaces, and extend to other data sources (BioArxiv, HowNet, etc.) and operating platforms (WeChat, Android, etc.).
改进PDF阅读器、改进推荐策略、美化图形界面、拓展到其他数据来源((BioArxiv、知网等)和操作平台(微信、安卓等)等。
Summary and Thanks总结与致谢
We must first thank the teachers of Huang Jun and Liu Tian and Shen Cheng for their teaching. Their meticulous guidance has enabled us to make progress in Java programming. The skills learned in the Java class will be of great help to the completion of this project. In addition, we would like to thank our friend Xu Dejia for his valuable suggestions for the creativity of the project and the use of the LeanCloud platform. Thanks to the development of Jsoup, JavaFX, and LeanCloud, the tools they developed provide great convenience for our projects.
我们首先要感谢Huang Jun老师和Liu Tian 、Shen Cheng两位助教的教学工作,他们细致耐心的指导使我们在Java编程方面取得了进步,课堂上学到的技能对完成本项目有着巨大的帮助。另外,我们要特别感谢Xu DeJia同学为本项目的创意和LeanCloud平台的使用提供了宝贵的建议。感谢Jsoup、JavaFX、LeanCloud的开发,他们开发的工具为我们的项目提供了极大的便利。
As a docking application for Arxiv’s scientific papers, our original intention is to make “brick workers” easier to access and organize materials, and to promote the exchange and dissemination of knowledge, so we have experience in recommending systems and graphical interfaces. Efforts have been made to make great optimizations. Of course, we hope that this project will not only be handed over as a homework. In the future, we hope to continue to optimize it, expand the functions of the user system, and extend the data source to BioXiv, HowNet and other platforms to accumulate data optimization recommendations. Continue to improve the experience of the graphical interface, and try the development of Android, IOS, WeChat applet and other platforms, to facilitate the daily access to information and knowledge exchanges for college students and researchers.
作为一个对接Arxiv的科技论文阅读应用,我们的初衷就是想让“砖工”们在查阅和整理资料时轻松一些,同时促进知识的交流和传播,因此我们在推荐系统和图形界面的体验方面都努力做出了很大优化。当然,我们希望本项目不仅仅是作为一个作业上交,在未来我们希望能将它继续优化,扩展用户系统的功能,并将数据来源扩展到BioXiv、知网等平台,积累数据优化推荐策略,继续改进图形界面的体验,并尝试安卓、IOS、微信小程序等平台的开发,方便高校学生和科研人员日常查阅资料和知识交流。