spider小白-初探Scrapy
Scrapy框架可以帮我们处理一部分事情,从而减轻我们的负担。更重要的是,Scrapy框架使用了异步的模式可以加快下载速度,而自己手动实现异步模式是十分麻烦的事情。
Scrapy框架的安装就不提了,下面演示怎么生产Scrapy项目。
然后使用pycharm打开生成的项目zhilianproject,工程目录如下:
其中myRedisCommand.py mySqlCommand.py zhilianSpider.py entrypoint.py是后面添加的
但这样我们还是再pycharm中无法进行调试,所以我们在添加entrypoint.py文件,该文件中的代码如下:
from scrapy.cmdline import execute
execute(['scrapy','crawl','zhilianSpider'])其中zhilianSpider是真正的爬虫文件名
再开始写代码前,我们需要对Scrapy框架有个基本的了解:
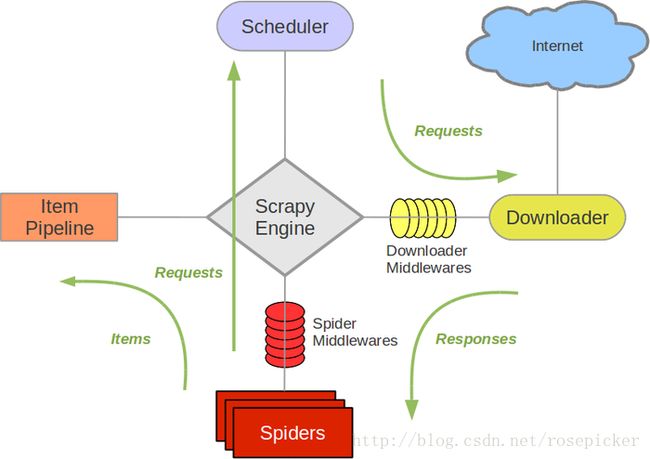
Scrapy Engine: 这是引擎,负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等!(像不像人的身体?)
Scheduler(调度器): 它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spiders来处理,
Spiders:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline:它负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的)
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses;和从Spiders出去的Requests)
接下来需要做三件事:
第一件事:再items.py中定义一些字段,这些字段临时存放你需要存储的数据,方便之后进行持久化存储
第二件事:再spiders文件夹中编写自己的爬虫
第三件事:再pipelines.py中存储自己的数据
第一件事:
根据自己需要的提取的内容来定义,通过以智联招聘的信息为例:
职位名称 职位链接 反馈率 公司名称 职位月薪 工作地点 发布日期
import scrapy
class ZhilianprojectItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位名称
zwmc = scrapy.Field()
# 职位链接
zw_link = scrapy.Field()
# 反馈率
fkl = scrapy.Field()
# 公司名称
gsmc = scrapy.Field()
# 职位月薪
zwyx = scrapy.Field()
# 工作地点
gzdd = scrapy.Field()
# 发布日期
gbsj = scrapy.Field()第二件事:
再spiders文件中新建一个zhilianspider,py文件,来实现自己的爬虫
设置一些基本参数如下:
name = "zhilianSpider"
allowed_domains = ['zhaopin.com']
basic_url = "http://sou.zhaopin.com/jobs/searchresult.ashx?"
TOTAL_PAGE_NUMBER = 90
KEYWORDS = ['金融IT','机器学习','数据分析','大数据','人工智能'] # 需爬取的关键字可以自己添加或修改
# 爬取主要城市的记录
ADDRESS = ['全国', '北京', '上海', '广州', '深圳',
'天津', '武汉', '西安', '成都', '大连',
'长春', '沈阳', '南京', '济南', '青岛',
'杭州', '苏州', '无锡', '宁波', '重庆',
'郑州', '长沙', '福州', '厦门', '哈尔滨',
'石家庄', '合肥', '惠州', '太原', '昆明',
'烟台', '佛山', '南昌', '贵阳', '南宁']根据基本参数动态生产需要爬取的url,使用parse函数接受上面request获取到的response
def start_requests(self):
for keyword in self.KEYWORDS:
for address in self.ADDRESS:
for i in range(1,self.TOTAL_PAGE_NUMBER):
paras = {'jl':address,
'kw':keyword,
'p':i}
url = self.basic_url + urlencode(paras)
print(url)
yield Request(url,self.parse)对获取的response进行解析,提取数据字段,然后组建成item,返回item数据
def parse(self,response):
html = response.text
date = datetime.now().date()
date = datetime.strftime(date, '%Y-%m-%d') # 转变成str
soup = BeautifulSoup(html,'lxml')
body = soup.body
data_main = body.find('div',{'class': 'newlist_list_content'})
if data_main:
tables = data_main.find_all('table')
for i,table_info in enumerate(tables):
item = ZhilianprojectItem()
if i ==0:
continue
tds = table_info.find('tr').find_all('td')
zwmc = tds[0].find('a').get_text() # 职位名称
item['zwmc'] = zwmc
zw_link = tds[0].find('a').get('href') # 职位链接
item['zw_link'] = zw_link
fkl = tds[1].find('span').get_text() # 反馈率
item['fkl'] = fkl
gsmc = tds[2].find('a').get_text() # 公司名称
item['gsmc'] = gsmc
zwyx = tds[3].get_text() # 职位月薪
item['zwyx'] = zwyx
gzdd = tds[4].get_text() # 工作地点
item['gzdd'] = gzdd
gbsj = tds[5].find('span').get_text() # 发布日期
item['gbsj'] = gbsj
tr_brief = table_info.find('tr', {'class': 'newlist_tr_detail'})
# 招聘简介
brief = tr_brief.find('li', {'class': 'newlist_deatil_last'}).get_text()
yield item第三件事:
pipelines组件会获取response解析后的item,因此通常在pipelines.py中进行数据的储存操作。在进行插入前,需要判断一下记录是否已经存在。
def process_item(self, item, spider):
if isinstance(item,ZhilianprojectItem):
zw_link = item['zw_link']
ret = self.sql.selectLink(zw_link)
if ret == 1:
print('该记录已经存在')
pass
else:
zwmc = item['zwmc']
fkl = item['fkl']
gsmc = item['gsmc']
zwyx = item['zwyx']
gzdd = item['gzdd']
gbsj = item['gbsj']
self.sql.insertMysql(zwmc, zw_link, fkl, gsmc, zwyx, gzdd, gbsj)
return item本项目采用的是mysql作为后端存储,相关操作可以自行百度,有很多资源。