主成分分析PCA算法:为什么去均值以后的高维矩阵乘以其协方差矩阵的特征向量矩阵就是“投影”?
这是从网上看到的PCA算法的步骤: 第一步,分别求每列的平均值,然后对于所有的样例,都减去对应的均值。 第二步,求特征协方差矩阵。 第三步,求协方差的特征值…显示全部
关注者
1,218
被浏览
78,113
关注问题写回答
添加评论
分享
邀请回答
22 个回答
默认排序

史博
数据科学家 | 自然语言处理Ph.D | 公众号:AI2ML
收录于编辑推荐 · 429 人赞同了该回答
千万不要小看PCA, 很多人隐约知道求解最大特征值,其实并不理解PCA是对什么东西求解特征值和特征向量。 也不理解为什么是求解特征值和特征向量。 要理解到Hinton对PCA的认知,需要跨过4个境界,而上面仅仅是第1个境界的问题。
为什么要理解PCA?
其实深度学习在成为深度学习以前,主要是特征表达学习, 而特征表达学习追溯到始祖象阶段,主要是无监督特征表达PCA和有监督特征表达LDA。 对了这里LDA不是主题模型的LDA,是统计鼻祖Fisher搞的linear discriminant analysis(参考“Lasso简史”)。 而Hinton在这方面的造诣惊人, 这也是为什么他和学生一起能搞出牛牛的 t-Distributed Stochastic Neighbor Embedding (t-SNE) 。

至于t-SNE为啥牛, 这里给两个对比图片, 然后我们再回到PCA,以后有机会再扩展!
t-SNE vs PCA: 可以看到线性特征表达的局限性

t-SNE 优于 已有非线性特征表达 Isomap, LLE 和 Sammon mapping
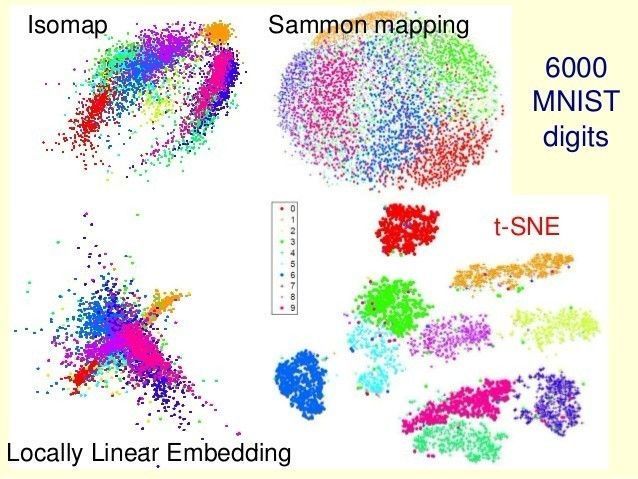
依然还记得2004年左右Isomap横空出世的惊奇, 再看t-SNE的诞生,真是膜拜! 也正是Hinton对PCA能理解到他的境界, 他才能发明t-SNE。
PCA理解第一层境界:最大方差投影
正如PCA的名字一样, 你要找到主成分所在方向, 那么这个主成分所在方向是如何来的呢?

其实是希望你找到一个垂直的新的坐标系, 然后投影过去, 这里有两个问题。 第一问题: 找这个坐标系的标准或者目标是什么? 第二个问题, 为什么要垂直的, 如果不是垂直的呢?
如果你能理解第一个问题, 那么你就知道为什么PCA主成分是特征值和特征向量了。 如果你能理解第二个问题, 那么你就知道PCA和ICA到底有什么区别了。
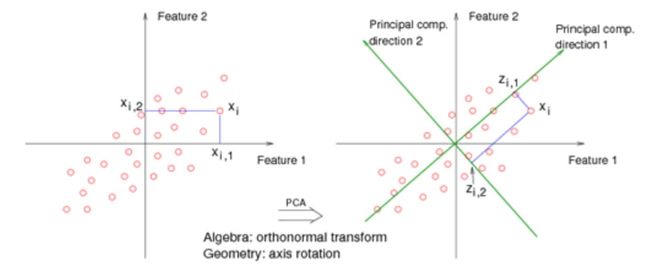
对于第一个问题: 其实是要求解方差最小或者最大。 按照这个目标, 你代入拉格朗日求最值, 你可以解出来, 主成分方向,刚好是S的特征向量和特征值! 是不是很神奇? 伟大的拉格朗日(参考 "一步一步走向锥规划 - QP" "一挑三 FJ vs KKT ")

现在回答了,希望你理解了, PCA是对什么东西求解特征值和特征向量。 也理解为什么是求解的结果就是特征值和特征向量吧!
这仅仅是PCA的本意! 我们也经常看到PCA用在图像处理里面, 希望用最早的主成分重建图像:

这是怎么做到的呢?
PCA理解第二层境界:最小重建误差
什么是重建, 那么就是找个新的基坐标, 然后减少一维或者多维自由度。 然后重建整个数据。 好比你找到一个新的视角去看这个问题, 但是希望自由度小一维或者几维。

那么目标就是要最小重建误差,同样我们可以根据最小重建误差推导出类似的目标形式。

虽然在第二层境界里面, 也可以直观的看成忽略了最小特征值对应的特征向量所在的维度。 但是你能体会到和第一层境界的差别么? 一个是找主成分, 一个是维度缩减。 所以在这个层次上,才是把PCA看成降维工具的最佳视角。
PCA理解第三层境界:高斯先验误差
在第二层的基础上, 如果引入最小二乘法和带高斯先验的最大似然估计的等价性。(参考"一步一步走向锥规划 - LS" “最小二乘法的4种求解” ) 那么就到了理解的第三层境界了。

所以, 重最小重建误差, 我们知道求解最小二乘法, 从最小二乘法, 我们可以得到高斯先验误差。

有了高斯先验误差的认识,我们对PCA的理解, 进入了概率分布的层次了。 而正是基于这个概率分布层次的理解, 才能走到Hinton的理解境界。
PCA理解第四层境界(Hinton境界):线性流形对齐
如果我们把高斯先验的认识, 到到数据联合分布, 但是如果把数据概率值看成是空间。 那么我们可以直接到达一个新的空间认知。
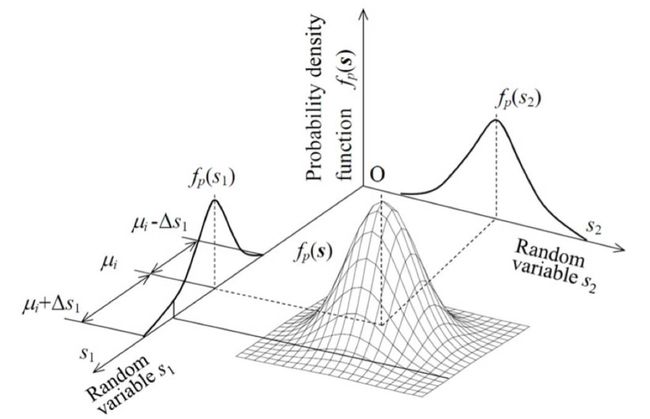
这就是“Deep Learning”书里面写的, 烙饼空间(Pancake), 而在烙饼空间里面找一个线性流行,就是PCA要干的事情。 我们看到目标函数形式和最小重建误差完全一致。 但是认知完全不在一个层次了。
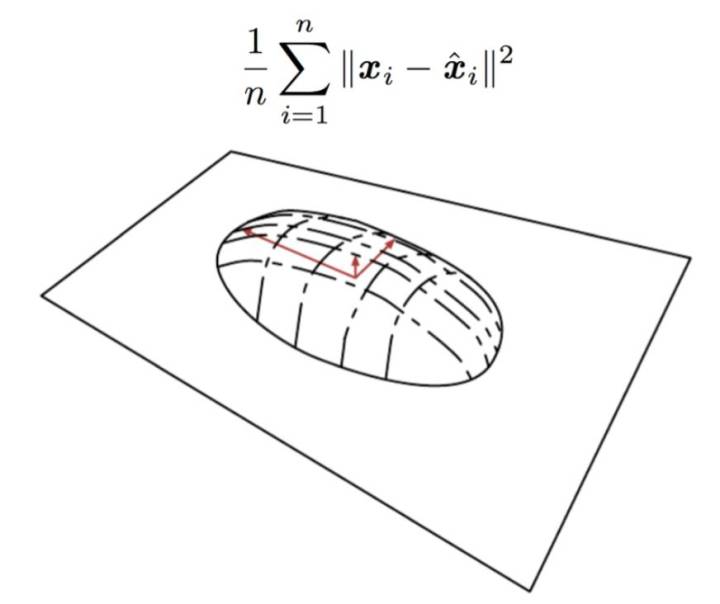
小结
这里罗列理解PCA的4种境界,试图通过解释Hinton如何理解PCA的, 来强调PCA的重要程度。 尤其崇拜Hinton对简单问题的高深认知。不仅仅是PCA,尤其是他对EM算法的再认识, 诞生了VBEM算法, 让VB算法完全从物理界过渡到了机器学习界(参考 “变の贝叶斯”)。 有机会可以看我对EM算法的回答,理解EM算法的8种境界。
编辑于 2017-12-14
赞同 42911 条评论
分享
收藏感谢收起

话说
47 人赞同了该回答
楼主这个问题提得很好,我尝试着答一下,希望可以解答楼主的疑惑。
首先我们来复习一下PCA的基本思想吧。
The central idea of principal component analysis (PCA) is to reduce the dimensionality of a data set consisting of a large number of interrelated variables, while retaining as much as possible of the variation present in the data set. This is achieved by transforming to a new set of variables, the principal components (PCs), which are uncorrelated, and which are ordered so that the first few retain most of the variation present in all of the original variables.
[Jolliffe, Pricipal Component Analysis, 2 nd edition]
有了这个基本思想作为指导,我应该可以更好地回答楼主的两个问题了。
第一个问题:
用PCA算法得到的这个“最合适”的低纬空间到底是什么?
回答这个问题之前,我们先来做几个定义:
- 是一个矩阵, 它有 列,每一列都是一个随机向量
- 是一个含有个常数的向量
- 的协方差矩阵是已知的,我们称之为
根据PCA的基本思想,要定义,或者说找到这个所谓“最合适”的低纬空间,我们只要做以下几步:
- 找到一个的线性方程,使得的方差最大
- 找到另一个的线性方程,,使得与不相关(uncorrelated),并且的方差最大
- 重复以上步骤,找到别的的线性方程
我们接下来来做第1步:
- 的方差:
- 我们发现如果要最大化 的方程,我们只要选一个巨大无比的就好了,这显然不是我们想要的
- 于是我们家一个约束条件,我们让的长度等于1,
我们再来做第1步:
- 最大化,约束条件是。我们可以用Lagrange方法,最大化,w.r.t.
- 对求导,并令其导数等于0。
- 我们发现就是的特征向量,就是其对应的特征值嘛。那么问题来了,我们改选那个特征向量呢?
- 我们再盯着看一会儿,发现这家伙其实就是:
- 所以我们选最大的那个特征值以及其对应的特征向量。
- 就是the first principal component.
然后我们来做第2步:
- 最大化,同时与不相关
- 用Lagrange方法,最大化
- 上式左右同左乘得:
- 所以我们有:
- 这又是一个特征向量特征值,有了上一部的经验,我们知道要选特征值第二大的那个。
以此类推,我们会得到一系列,他们组成的空间是一个跟有相同维度的空间。至于那个“最合适”的低纬空间就是吧最小特征值对应的特征向量扔掉,剩下来的那个空间。
第二个问题:
为什么PCA这么操作:去均值的原矩阵?
从我上面的推导来看,貌似并没有涉及到去均值这一步。我去研究了一下,其实有些时候的确需要去均值,另外一些时候不需要。Pearson在1901年的一篇论文中间提到,如果不去均值的话,最优拟合超平面会通过原点,而不是的几何中心。但是也有一些例外情况中,超平面做的仅仅是把划分到相互垂直的子超平面上,这个时候去均值就不是必要的。具体情况请参见一下链接。
http://www.ulb.ac.be/di/map/yleborgn/pub/NPL_PCA_07.pdf
不知道我的回答是否解决了楼主的疑惑,如果有讲的不清楚或者不对的地方还请大家指出。
编辑于 2016-05-27
赞同 4721 条评论
分享
收藏感谢收起

達聞西
280 人赞同了该回答
看到那么多带公式的,完善的推导,我写个带图的,公式少一些详细一些,但是不严谨的直观理解把,仅供参考。
一、先从旋转和缩放角度,理解一下特征向量和特征值的几何意义
从定义来理解特征向量的话,就是经过一个矩阵变换后,空间沿着特征向量的方向上相当于只发生了缩放,比如我们考虑下面的矩阵:
求这个变换的特征向量和特征值,分别是:
(列向量)
和
1.81,0.69
用一个形象的例子来说明一下几何意义,我们考虑下面笑脸图案:

为方便演示笑脸图案在0,0和1,1围起来的单位正方形里,同时也用两个箭头标出来了特征向量的方向。经过的变换,也就是用这个图案中的每个点的坐标和这个矩阵做乘法,得到下面图案:
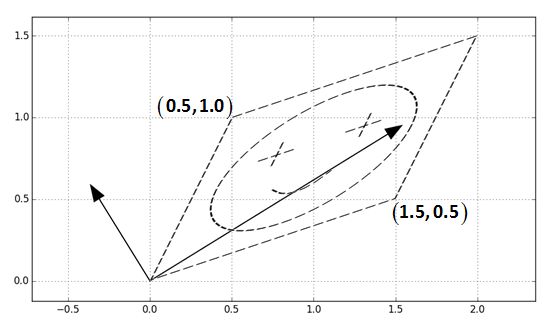
可以看到就是沿着两个正交的,特征向量的方向进行了缩放。这就是特征向量的一般的几何理解,这个理解我们也可以分解一下,从旋转和沿轴缩放的角度理解,分成三步:
第一步,把特征向量所指的方向分别转到横轴和纵轴
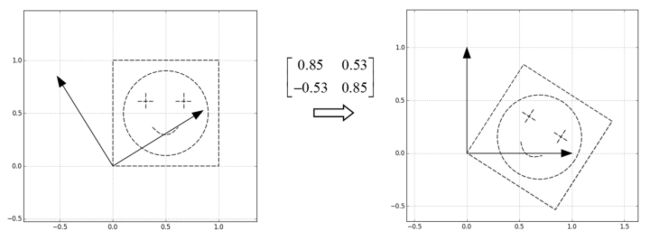
这一步相当于用U的转置,也就是进行了变换
第二步,然后把特征值作为缩放倍数,构造一个缩放矩阵,矩阵分别沿着横轴和纵轴进行缩放:
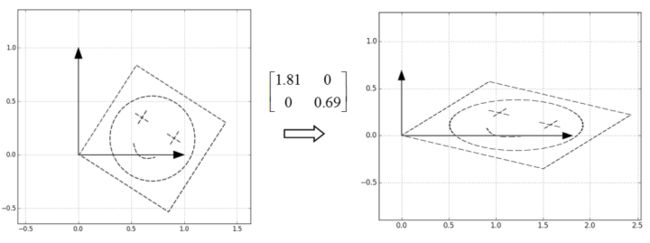
第三步,很自然地,接下来只要把这个图案转回去,也就是直接乘U就可以了

所以,从旋转和缩放的角度,一个矩阵变换就是,旋转-->沿坐标轴缩放-->转回来,的三步操作,表达如下:
多提一句,这里给的是个(半)正定矩阵的例子,对于不镇定的矩阵,也是能分解为,旋转-->沿坐标轴缩放-->旋转,的三步的,只不过最后一步和第一步的两个旋转不是转回去的关系了,表达如下:
这个就是SVD分解,就不详细说了。
另外,这个例子是二维的,高维类似,但是形象理解需要脑补。
二、协方差矩阵的特征向量
PCA的意义其他答主都说得差不多了,一句话概括就是找到方差在该方向上投影最大的那些方向,比如下边这个图是用作为些协方差矩阵产生的高斯分布样本:
:
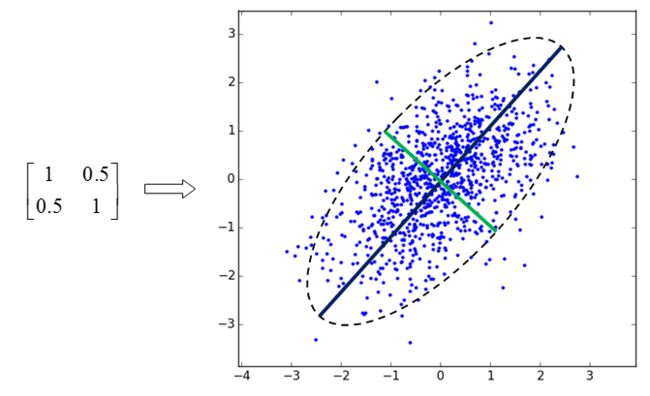
大致用个椭圆圈出来分布,相关性最强的(0.707,0.707)方向就是投影之后方差最大的方向。
接下来我们不尝试严格证明,而是从旋转和缩放的角度形象理解一下,我们可以考虑把这个分布也旋转一下,让长轴在x轴上,短轴在y轴上,变成如下:
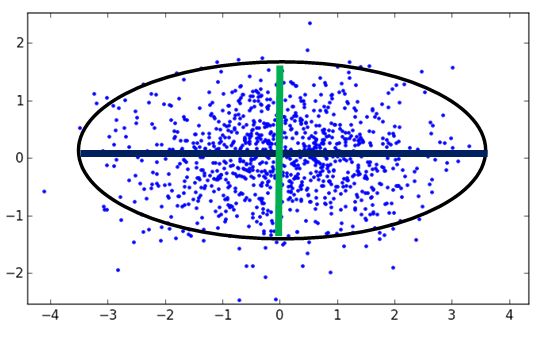
然后再沿着x轴和y轴,除以标准差,缩放成标准差为1的单位分布

注意,在这个除以标准差的过程中,标准差最大的轴,就对应着原空间中,样本投影后方差最大的方向。接下来,假设这个分布中的样本为,则我们可以把一开始的样本表示为:
用这么别扭的表示方式主要是为了接下来推公式方便,所以接下来推个简单的公式:
协方差矩阵,用S表示,则有
因为这个分布里两个维度的均值都是0,所以有
所以
其中N是样本数,根据前面的,进一步展开这个公式:
因为是个单位方差的且无相关性的样本,所以
另外L是个对角矩阵所以有
这个公式上一部分已经说过了。
所以对角线上的元素对应的就是方差的大小,而缩放倍数就是标准差的大小,也就是特征值的开根号,而U就是要沿着缩放的方向,也就是问题中投影的方向,正是特征向量。
编辑于 2016-09-06
赞同 28016 条评论
分享
收藏感谢收起
知乎用户
30 人赞同了该回答
1、一个向量在一个单位向量的投影是。特征向量是一组正交基,矩阵相乘就是把每个样本分别向每个特征向量上去投影。
2、PCA里找到的投影方向是投影后方差最大的前k个方向(简单理解就是区分度最好的方向)。
这种东西还是要找书,tutorial看提高姿势水平,网文多不靠谱。
编辑于 2015-05-04
赞同 304 条评论
分享
收藏感谢

曹荣禹
persist......forever
30 人赞同了该回答
PCA的思想是将数据降维,降到哪些维上呢,就是使得数据分布方差最大的那些维上。主成分的意思就是,那些使得数据分布方差最大的那些维就是主成分。这个是PCA模型的思想,后面如何让方差最大,如何选出这些方向下面分步介绍。
- 将数据中心移动到0并正则化这些数据,也就是将所有样本点X减去均值并除以方差,获得X‘是归一化后的数据。
- 设降维后的空间是p维的,现在要将每一个样本点投影到这个p维空间中,因此需要乘以投影矩阵P,设这个p维空间的正交基是U=[u1,u2,...,up]。则投影矩阵就是,具体推导去补一下线性代数中投影方面的知识吧,然后由于U是正交矩阵,因此,这样,我们就把一个样本点xi投影到这个p维空间中就行了,获得的在p维空间中的坐标为,同样这部分知识来自于线性代数中投影方面。
- 这样我们获得了每个样本点在降维后的空间中的坐标,那么现在,我们需要计算方差了,很明显,降维后的数据分布的方差是,把步骤2中的y带入进来,推导一下可以获得数据分布的方差可以表示为,其中是x的协方差矩阵。这个推导过程虽然简单但是需要自己推一边,我推过好几次了,题主可以去试着推一推,因为其他算法也会用到类似的推导。
- 现在整个模型就转化成了最优化问题,,这个最优化问题是瑞利熵问题的一种最简单的形式,瑞利熵问题的解是协方差矩阵的前p大的特征值对应的特征根组成的矩阵U。现在题主应该知道为什么要求这个矩阵的前k个特征根了吧。瑞利熵问题的推导感觉挺烦的,本科生的我完全看不懂,但是记住结论会用就知道了,关键是能看出来某一个优化问题就是瑞利熵问题。
至此,我们已经学习出了降维后的空间,这个空间的p个正交基组成的矩阵就是U,这个U就代表了这个空间,对于一个新的样本点x,我们只需要将x投影到U代表的这个p维空间上就达到了降维的目的了。因此,最后的降维后的向量。
整个算法的大致思路就是这样。记住PCA的思想,就是找到这样一个空间,使得原始数据投影到这个空间后的分布的方差最大化!希望对有所帮助,如有错误,还请指出!
编辑于 2017-04-06
赞同 306 条评论
分享
收藏感谢

靠靠靠谱
Pessimist / Machine quitting engineer / data fakist
18 人赞同了该回答
题主的问题是:
1. 什么是『最合适』的低维空间
2. 为什么这么操作就能得到『最合适』的低维空间
数学推导通通可跳过版:
一般来说原始数据维度太高消耗存储空间,我们就想压缩一下维度。于是我们想在低维空间得到一个原始数据的近似表达,代价是损失了一些精度。至于如何衡量精读的损失,一般是通过『距离』来衡量,也就是Norm。这应该是题主最想知道的部分,其余的结果(包括使用特征值分解)都是从这里推导出来的。
先定义一下几个Notation,不要着急推导还没有开始:
高维原始数据 有维度
低维近似数据 设定维度
PCA,其实是由高低维度之间切换的函数定义的,而这个函数又是『人们』选择的。
- 高to低(降维):
- 低to高(重建):
因为人们real懒,总想简单一点,所以选择了矩阵乘法来在高低维度自由转换。不如先记一个重建矩阵,保证size合适。
- 低to高(重建):
- 因为real懒,我们简化的列都是两两正交的
- 为了唯一解,还要的列是单位长度的(等比例地伸缩自如的解是没有意义的)
我们现在仍然不知道为何物,也不知道怎么降维,但我们马上就可以知道了:
# # # # # # # # # # # 推导 B E G I N # # # # # # # # # # #
# 1. 求得最优降维公式
# 利用L2 norm定义最优的低维近似
# 展开L2 norm
# 其中
# 因为我们设定有正交的且单位长度的列
# 求导取零得到最优解
# 哇也就是说重构矩阵转置就是可以实现降维真的好简单!
# 但是重构矩阵是什么?
# 2. 求得最优
# 我们之前说到用L2 norm衡量距离,这是对一个向量而言的。拓展到矩阵之间的距离就要使用Frobenius norm:
# 因为我们定义的就是最小化精度损失得来的:
subject to
# 为了看得清楚一点,我们先看情况:
subject to
# 用矩阵表达去掉求和的sigma
subject to
# 用迹 (trace) 去掉norm
subject to
# 中间都是用trace相关的化简,如果有需要再补充,因为公式real烦
subject to
# trace中的连乘可以转圈圈
subject to
# 现在阶段的最优解需要用到特征值分解,i.e. 当是最大的特征值对应的特征向量的时候。括号里对应为,最大的特征值的平方
# 特征值分解可以理解为:将矩阵分解为好几个『方向』(特征向量基eigenvector basis(特征向量:你才基!)),每个方向的『权重』通过特征值来衡量。特征值大,
# 因为是实对称的,特征值分解可得(我一直觉得好像QAQ)
# 如果不是降维到一维呢?
# 那就多挑几个特征值大的特征向量嘛。
# 可以证明就是个较大的特征值对应的特征向量的组合
# # # # # # # # # # # 推导 E N D # # # # # # # # # # #
Plus,
这里用到自然是有特征值分解的,实际使用PCA的矩阵不一定是满秩的方阵,所以才会用到奇异值分解 (SVD) 。如果需要再补充SVD的细节=w=
Plus^2,
挑选几个特征向量好呢?可以画variance explained,近似为使用的特征值的比例图,挑选折点。
到此为止,问题应该已经有很清楚的答案了。
那就是:L2 norm 和 推导出来的啦。
发布于 2016-03-23
赞同 185 条评论
分享
收藏感谢收起

赋布斯
学不动...
19 人赞同了该回答
最近刚刚学了这些 来献丑了
首先你要理解特征向量的含义。
把矩阵理解成一个空间,那么对于一个对称正定的矩阵A,它的特征向量就是对A所构成的空间的一个正交化。特征值大小就代表 空间在 该特征值对应的特征向量上的“影响”能力,即越大在对应特征向量这个基上,包含信息‘最多’。
所谓合适的低维空间,举例说明,以128*128的图像说明,我们选最大的10个特征值对应的特征向量重构图像(如下图)

再将这10个图像叠加,就能得到和原图相差无几的图片,实际上这10个特征向量构成的空间包含了原图95%的能量。
第二问参考机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)
基本思想是
我们找一组基底,按照方差最大为原则,得到目标函数,用拉格朗日法,求该目标函数极值,这样发现该基底为特征向量时取得极值。 如
@姚鹏鹏
所说,参考博客中还提到了按照能量损失最小为原则,也得到了一样的结果。这里有一点要注意

这里的S是原矩阵每一行Xi 自相关得到的矩阵的和,即。那么按照之前的理论分析,我们应该求这个矩阵的特征值而不是协方差矩阵,有关教科书上理论推导也都是求这个矩阵特征值。
但是实际情况 都是求的协方差矩阵的特征值。
而他们之间的特征向量存在转换关系,如下式

右边的是协方差矩阵的特征向量 是上面S矩阵的特征向量,U是原矩阵。
具体证明可参照 边肇祺的模式识别,其实就是svd分解。
这样一个好处就是,还是以128*128图片为例子,就不用去解128*128维的特征值,大矩阵的特征值计算很费时,转而求小规模矩阵的特征值,然后再转化回去。
你所说的
去均值的原矩阵*(去均值的原矩阵的协方差矩阵的特征向量作为列向量形成的矩阵)
实际上之后还要做一步归一化的过程,也就是上面那个公式。
发布于 2015-05-06
赞同 198 条评论
分享
收藏感谢收起
知乎用户
10 人赞同了该回答
题主显然已经懂了PCA怎样实现,问题就是为什么这样实现。
在prml的第12章,有两种解释,
@npbool
说的是第一种解释,最大投影后方差解释,然后就是怎样表示投影后方差的问题,显然就是很显然,这里面的S就是你说的“去均值的原矩阵*(去均值的原矩阵的协方差矩阵的特征向量作为列向量形成的矩阵)”。然后的问题就是怎样最小化E的问题,因为是带约束条件的,所以这边的优化要加上一个朗格朗日的乘子,也就是,所以呢,通过对求导,这样就能够得到,这也就是为什么求特征向量的原因了
发布于 2015-05-04
赞同 107 条评论
分享
收藏感谢

谢润
28 人赞同了该回答
铺垫:

很容易看出,图中红线向量坐标为(3,2)。我们之所以有这个结论,是在一个前提条件下,那就是默认基为(1,0)和(0,1)。通常情况下,为了能够简洁的表示,我们将基选为单位长度并且正交的一组向量。

但是假如我们将基选为(1,1)和(-1,1),那么红色向量的坐标变成什么呢?(1,1)*(3,2)=5,(-1,1)*((3,2)=-1,即变成(5,-1)。
本质上讲,PCA就是将高维的数据通过线性变换投影到低维空间上去,但这个投影可不是随便投投,要遵循一个指导思想,那就是:找出最能够代表原始数据的投影方法。首先的首先,我们得需要知道各维度间的相关性以及个维度上的方差啊!那有什么数据结构能同时表现不同维度间的相关性以及各个维度上的方差呢?自然是非协方差矩阵莫属。
协方差矩阵的主对角线上的元素是各个维度上的方差(即能量),其他元素是两两维度间的协方差(即相关性)。我们要的东西协方差矩阵都有了,先来 看“降噪”,让保留下的不同维度间的相关性尽可能小,也就是说让协方差矩阵中非对角线元素都基本为零。达到这个目的的方式自然不用说,线代中讲的很明确——矩阵对角化。而对角化后得到的矩阵,其对角线上是协方差矩阵的特征值,它还有两个身份:首先,它还是各个维度上的新方差;其次,它是各个维度本身应该拥有的能量(能量的概念伴随特征值而来)。
对角化后的协方差矩阵,对角线上较小的新方差对应的就是那些该去掉的维度。 所以我们只取那些含有较大能量(特征值)的维度,其余的就舍掉即可。PCA的本质其实就是对角化协方差矩阵。
前面的回答理论讲得很多,不过看着也累。这里就举个例子,应该更容易理解。
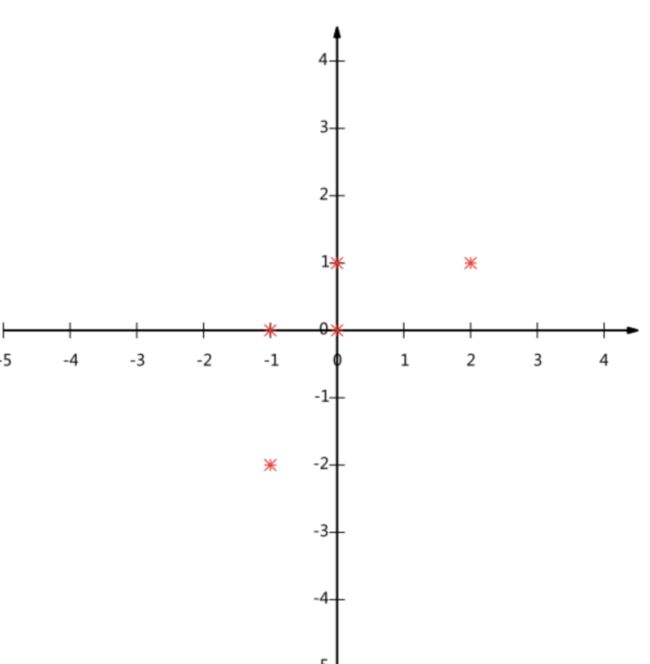
这个例子是将二维转化为一维。五个点(-1,-2)(-1,0)(0,0)(0,1)(2,1),确定一个基坐标,将其投影过去,要求保存最大的信息量。首先,很直观的知道,不能投影去x轴或者y轴。如果投影去x轴,有两点在x轴方向投影一致,会造成信息损失。y轴也同理。
那么我们就用主成分分析方法来推导

那么降维之后的图像便是这样

之前(-1,-2)这点现在的坐标变为了

那么我们就成功地将二维向量降为一维,并且尽可能多地保留了信息。
那么回到题主问题“为什么去均值以后的高维矩阵乘以其协方差矩阵的特征向量矩阵就是“投影”?”就我举的这个例子来说,其实这个特征向量就是我们在一维空间内选择的基,乘以原向量,其结果刚好为新基的坐标,即相当于其投影。当然推广到多维肯定更加复杂,但其原理不变。题主可以结合这个例子好好理解一下。
答主本科学习过PCA,但一直没弄清其本质,现在想来重新温习一下,有不对之处请指出。本文内容大量参考PCA的数学原理(非常值得阅读)!!!!想要更加深入了解请点击链接。
编辑于 2016-10-10
赞同 284 条评论
分享
收藏感谢收起

JX Consp
朱门酒肉臭,路有克苏鲁
7 人赞同了该回答
首先,这些东西如果没有老师的话,最好是看各种靠谱教科书,然后是查 wikipedia
简单来说,PCA就是做了SVD分解,SVD分解的前n项就是只选择n个基线性拟合出来的最小误差值
Singular value decomposition
但是很多时候,有些人不知道SVD分解的存在于是手动求 SVD 分解。
对 F(s,t)做SVD分解之后 而且
于是
所以这就是为什么要求一个特征值的原因
编辑于 2015-05-04
赞同 7添加评论
分享
收藏感谢

Fisher
What is an intuitive explanation for how PCA turns from a geometric problem (with distances) to a linear algebra problem (with eigenvectors)?stats.stackexchange.com
发布于 2018-09-09
赞同添加评论
分享
收藏感谢
知乎用户
10 人赞同了该回答
PCA 可以用来做降维,但通俗一点说,其本质应该是线性空间坐标系的转换,从原始的空间坐标系,转换到一个“合适的”的坐标系来表达,在这个坐标系中,主要信息都集中在了某几个坐标轴上,所以只保留这个“关键”的坐标系上的表达,就能很大程度approximate原信号。
算法怎么计算很重要,但是更重要的是要了然做每一步的motivation,这样才不至于被太多计算细节所困住,见树木不见森林。推荐一个arXiv 上的一个Tutorial:A Tutorial on Principal Component Analysis. Google的一个researcher写的,通熟易懂,后面附有matlab代码。
发布于 2015-05-05
赞同 101 条评论
分享
收藏感谢

sudit
3 人赞同了该回答
我觉得可以先从简单点的数据来看要直观一点,比如下面这个二维的数据集,如果要降维成一个维度的数据,可以向横轴或者纵轴作投影(当然其他轴也可以)。



但是从投影效果来看的话,横轴投影的数据点要分散得更开一些,相对的纵轴投影基本上都聚到一堆了。这就说明不同方向的投影存在效果上的差异,至于怎样的投影才是好的投影呢?可以假想两个极端点的情况,一种是投影后的数据都等于一个值,另一种是投影后的所有数值都不一样,显然后一种才是我们想要的。所以为了衡量投影效果,我们可以引入方差这个概念作用在投影后的数据上,因为方差本身就度量的数据的离散程度。
确定了基本目标之后,现在我们来考虑获取投影后数据的问题,如果是像刚才的散点图,那么直接用横坐标值就可以了。但是往往问题没那么简单,比如下面这堆数据点就不能这样办。

但是这也不复杂,直接把点投影到斜线上,然后再计算投影点到原点的带符号距离就可以了。但这就需要先计算投影点的坐标,为了偷懒,我们可以定义一条与原投影直线相垂直的直线,然后假设这条直线的方程为
并且还规定 。于是对于任何一个数据点 , 刚才我们提到的带符号距离就可以表示成
用这个带符号距离作为降维后的数据,就完成了投影这一步。接下来的任务就是找到这样的 (其实这条直线并不是投影直线,而是投影直线的垂线,不知不觉就偷换了概念。。)。定义数据集 ,那么我们的任务就变成了寻找 使得 具有最大值。
有了这一基本概念之后,现在可以把问题提到高维空间中去了,其实本质没变,但是通用性要高一点。假设原始数据维度为 d,原始数据矩阵为
按列分组后写成
它的协方差矩阵为
好了,现在的带符号距离值就可以写成
向量形式为
用矩阵符号表示的话
下面我们将证明 的最大值为 的最大特征值。根据方差的性质
容易知道协方差矩阵 为实对称矩阵,于是它拥有一组可以作为单位正交基的特征向量
满足
以及相对应的特征值
并不失一般性的假设
利用这组基向量,我们可以将 分解成
那么
其中 是最大的特征值,上述公式取等号的条件是,与 相对应的系数 为 1,其他的系数为 0,这时有 。再考虑到约束
于是可以得出结论
并且当 时,等号成立,对应的 就为
从这里你就看到了一丝端倪,所谓的 “原来的高维矩阵(去均值以后)乘以这个“k个特征向量分别作为列向量组成特征向量矩阵””已初具雏形。这里得到的 其实是第一主成分。下面我们再计算第二主成分,同样是要找到一条直线或者超平面来计算带符号距离,但是它必须要和计算第一主成分时的基线正交,否则得到的第二主成分将有一部分含有第一主成分的信息。于是计算第二主成分的超平面系数向量 必须满足条件
以及当然
接下来我们将证明,满足上述条件的 必然使 的最大值为 第二大的特征值 ,并且 。首先对 进行分解
考虑到 与 正交,所以
也就是说,第一个方向上的分量为 0。然后根据方差的性质
同样,根据 ,可得
于是有
其中取等号的条件是,不等式中 , 其余系数为 0。于是我们就证明了,当 时, 取得最大值 。
基于同样的方法,我们还能寻找第三主成分,第四主成分等等。将这些主成分 按列合并,形成新的数据矩阵
也就是说
如果你把 理解成代表低维空间的矩阵的话,那么确实 “把高维空间里的向量投影到低维空间,就是用这个高维向量乘以代表这个低维空间的矩阵就行了”。按照史博的说法,上面的推导算是理解主成分分析的第一和第二层境界吧。
至于为何要有去均值这个操作?我认为是由于需要对数据进行归一化的关系,因为原始数据每个维度上的数值量级很可能不一样,如果不归一化,它们的方差就没有可比性了。而为了归一化,首先去均值,应该要方便一点。
编辑于 2018-03-11
赞同 3添加评论
分享
收藏感谢收起

KevinSun
这个是推导出来的结论:找到一个投影空间,让在上面投影后的数据的方差最大化,对应优化结果就是这个
发布于 2017-07-06
赞同添加评论
分享
收藏感谢
知乎用户
5 人赞同了该回答
更新, 是协方差矩阵
==============================原回答==============================
题主应该主要有两个问题:
- “最合适”是如何评价的
- 为什么就“正好”是特征向量来降维
第一个问题,

图片来源:Principal component analysis
上面图片中,一个样本点有两个特征,现在要去掉一维,不进行坐标变换就是直接将样本投影到轴或者轴(直接去掉一个特征)。那么有没有更好的方向进行投影,并保留最多的信息呢(降维的目的)?这里正确的方向就是:将样本投影到图中较长箭头的方向,记做方向(没有找到向量符号)。为什么?这样投影后样本方差最大。(信噪比也用方差比来衡量Signal-to-noise ratio)
那么为什么这个方向方差最大?设上图中发出两个箭头的点是(投影中心),它投影到轴的点就叫。那么对于图中一个样本,那么多数情况下样本投影到方向与投影中心的距离要大于投影到轴的,这样方差也就大!这里短箭头则是最坏的方向,原因样本投影到这两个箭头的值满足勾股定理,和是样本到的距离。
下面是解决第二个问题,
首先,接着第一个问题的最佳方向,如果我们将坐标轴旋转一下方向与箭头方向重合,那么也可以直接去掉一个特征不是?
所以,解决第二个问题就是将标准基旋转到一个正确的位置,然后选择最好的几个轴即可!有一个正交矩阵,及数据矩阵,那么是?是对原始数据进行旋转,山不转水转,是不是相当于旋转了标准基。正交变换保证了两个向量变换前后模长和内积没有变化,所以变换等同旋转。
是特征*样本表示的话,那么中心化之后就是协方差矩阵了,可以表示特征间的线性关系。我们想要的是进行变换后,我们的协方差矩阵是一个对角阵!两个特征协方差不为,说明存在冗余。
好,到此为止,说一下要办的事:找到一个正交阵(单位正交阵),对原始数据进行变换后的协方差矩阵为一个对角阵。正交阵也是投影的方向互相垂直。
也就是:,即做个正交对角化并按照特征值降序改变,的每个行是新坐标的基向量,选择合适的维度直接去掉下面几行进行降维,PCA就做完了。
这里,题主问题二来了,为什么刚好是特征向量?
- 当且仅当矩阵是对称阵,可以正交对角化
- 矩阵可以被它的正交特征向量对角化
上面两条却还差一点:,即的每一列都是的特征向量!也就是一个对称阵能被正交对角化的都是它的特征向量组成的矩阵。
那么,这样对角矩阵元素,就确定了,最大方差也只能从这里面出,降序挑选即可。
hu~~~
[1404.1100] A Tutorial on Principal Component Analysis 这篇Tutorial给了很大指引,读下来之后可能就补充的一条需要想到。
PS. 第一次看到PCA对正好是特征向量矩阵也感到不可理解,所以也关注了这个问题(拉格朗日证明很对,但是觉得应该有其他理由),这里把能说服自己的理由贴出来,不对的望指正。
编辑于 2017-06-11
赞同 53 条评论
分享
收藏感谢收起
小杨
模式识别小白
3 人赞同了该回答
今年做毕业设计时用到KPCA(核主成分分析)和主成分分析(PCA),当时思考了一下,收获了不少。现看到这个题目,试着回答一下,算是提供一种思路吧。
以下正文:
首先PCA的目的是数据维数压缩,尽可能降低原数据的维数,但要不损失信息或者损失少量信息。为此,它在后面处理时选择了特征值最大(目前我的理解是绝对值最大)的特征值对应的特征向量组成变换矩阵。
可以说PCA基于一点假设,即认为数据在各维上是随机的(或者说每个数据看成一个随机向量),然后构建协方差矩阵。这个协方差矩阵是对称矩阵,主对角元素是各维数据的方差,而其他的则是各维数据之间的协方差,反映了各维数据之间的「线性」相关性,并且不为零时说明存在着相关性,那么也就存在着「冗余信息」(可以联想解线性方程组时的多余/无效方程组)。
维数压缩,那么就要去掉/舍弃多余的维(或者说不太重要、影响小的维)!那么先去掉各维之间的相关性,那么最好是全部去掉相关性,即使得压缩后的数据的协方差矩阵能是一个对角阵那该多好啊(^_^)!
这就是PCA的思想。
那我们就试着把目标数据(变换后的数据)的协方差矩阵变成一个对角阵!于是可以描述为:给定数据集X,求线性变换使得变换后的数据集的协方差矩阵是一个对角阵。
下面就是矩阵对角化的问题了。简单推导一下以更加理解:
数据集X为N个M维的特征数据构成的M*N的矩阵,记是一个M维随机向量,表示变换后的数据向量,CX和CY分别表示原数据(随机向量)和变换后数据(随机向量)的协方差矩阵。有:

将CX对角化,即
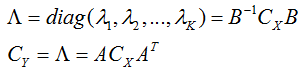
矩阵B为Cx的特征列向量构成的可逆矩阵。可见,当B为正交阵(先相似求特征向量再正交化)时,若取即为变换矩阵,它可使协方差矩阵
![]()
即达到了要求。此时没有进行压缩。
取,那么A也是正交阵,或者至少是正交向量组构成的矩阵。然后选择特征值最大(目前我的理解是绝对值最大)的K个特征值对应的特征向量(注此时的特征向量已经不再是原来的特征向量了,是正交化后的向量,正交化后的向量是原来特征向量的线性组合,仍然是和与原特征值对应的特征向量)进行投影得到新数据,也就是PCA处理后的数据。
首先说明:这里的投影,实质上是做内积运算,即数据向量(组)和特征向量(组)之间点积运算(用向量组的话通过矩阵乘法可以一次性变换所有的数据!)。
下面进行映射/投影。
一般我们计算得到的特征值和特征向量,然后正交化、单位化后得到矩阵B,我们假设已经对B按特征值绝对值大小排好顺序,从正交矩阵B中取K个特征向量,组成矩阵,它是一个M*K(K≤M)的矩阵,矩阵中的K个单位正交列向量组就是投影所选择的方向。
投影:
这里是一个K维列向量。即映射/投影时,是用矩阵的转置去乘以原数据,这样仍然得到一个列向量,或者用原数据去乘以矩阵,这样得到的是一个行向量即。
【说明】:直接用矩阵的转置去乘数据,将同时得到变换后数据的K个维的值,如果只取其中一个向量,则只能得到新数据的一个维的值。可以参考直角坐标系,取向量(2,3),目标向量组取x、y轴的单位向量,列向量的两维分别表示x和y值,即有

【如果把原数据以列(行)向量形式组成一个矩阵X,那么将一次性得到所有变换后的数据,并且也是列(行)向量形式。】
回到问题。
1——“映射后的低维空间”:
我们先假设没有进行正交化,直接用Cx的特征向量进行投影,那么根据向量空间的知识,“低维空间下”就是所选的Cx的特征向量构成的空间。
于是现在正交化了,那么就是由所选的特征向量正交化后的向量构成的空间,此时向量间是正交且是单位的,而原特征向量则不一定正交(对于实对称矩阵,取决于其特征值的特点,互不相同则必正交,存在重根则必不完全互相正交)。
所以“映射后的低维空间”是一个以B的列向量为基(是单位正交向量组)的线性空间,基的列向量之间相互正交。
2——“…相乘就是投影”:
如上面解释的那样,那样运算,才是投影运算;并且按题主所说"数据乘以向量组",那么在原数据是列向量时得到的新数据是行向量形式。
最后,扯一点其他的,MATLAB中有求特征值和特征向量组的函数(是eig),那个其实已经做好了正交化工作。
(首答)
发布于 2016-10-11
赞同 3添加评论
分享
收藏感谢收起

付杰
一个人的朝圣路
2 人赞同了该回答
最近在看PRML的PCA那一章,觉得讲得特别清楚也特别自然,简单转述一下书里的推导,也写写自己的看法吧。所引用的公式基本都是书里的。
首先我们要知道推导PCA公式的目的和出发点是什么,我们想要将原始数据(假设是D维),降到一个比较低的维度空间中(假设是M维),如果想要将数据点在某个空间中表示出来,我们就需要知道构成这个空间的基向量(basis vector)是什么。假设这个M维的低维空间的基是:
因此对于一个数据点 ,我们可以将其表示为:
其中小括号内的部分是一个scalar,就是该数据点在某个basis vector上的投影,投影的值再乘上这个方向上的单位向量,就成了数据点这个方向上的分量,将所有方向上的分量加到一起,就重建出了原始向量。
举一个简单的例子,以二维空间为例,在坐标系里我们表示一个点,例如(1,2)时,会用到该二维空间的两个basis vector,也就是(1,0)和(0,1),分别是X轴和Y轴上的单位向量,点(1,2)在X轴的投影为1,在Y轴的投影为2,因此按照上面的写法,我们可以将(1,2)这个点写作:
既然要降维,那一定是要舍弃掉某些维度保留另外的维度,那么如何去寻找这些维度?
还是假设原始数据是D维,我们需要保留M维,按照这样的降维逻辑,对于任意的一个数据点都可以用如下的式子来表示:
即PRML中的式(12.10)。这个式子很重要,也是所有推导的出发点。按照书上给出的解释,我们只将数据在我们关心的这M个维度上进行投影,在其他的维度的投影我们用一个常数去表示(注意不是直接去掉),这个常数就是楼主想要问的平均值的来历。这也是为什么等号右边第一项的投影z有下标n而第二项b没有的原因,因为第一项的投影是随数据点的变化而变化的,而第二项是不随数据点变化的。
到这里为止都没有特征向量出现,特征向量出现在下面的推导。
刚才这个式子只是一个原始的数学模型,我们需要去具体求解这些basis vector究竟是什么。(站在上帝视角也就是证明这些basis vector为什么是协方差矩阵的特征向量)对于变换之后的数据我们当然希望损失的信息越少越好,也就变换后的向量和变换前的向量的差值(采用L2 norm)应该尽可能的小,因此我们很容易找到需要最小化的目标函数(省略了前面的常数项):
将原始数据也写成两项和的形式,然后将前面的式子带入J的表达式我们就能得到:
其中:
这里将其中一个求和吸收到了矩阵运算中,这里的S就是协方差矩阵(省略了前面的常数)。可以看到损失函数完全依赖于basis vector,因此可以求解出最优的投影方向。为此我们需要知道basis vector 所满足的正交归一化条件,即:
利用拉格朗日乘子考虑极小化以下式子:
因为这里不同的basis vector之间并没有耦合在一起,因此这个式子可以拆开来一项一项优化,举其中一项为例:
对basis vector求导并令导数为0可以得到:
这下看得很明白了,这不就是S的特征向量吗!引入的拉格朗日乘子中的常数就是特征值。
我们还可以将这个式子带入到J的表达式中得到:
可以看到损失函数与特征值有关系,因此如果要最小化损失函数的话,我们应该让这个特征值尽可能的小。注意这里的特征值所对应的特征向量是剩下的那(D-M+1)个,因此我们舍弃掉后(D-M+1)个特征向量,取前D个特征向量作为我们的basis vector。
至此,我们就推导出了为什么PCA给出的投影方向是协方差矩阵的前K个特征向量了:因为要最小化重构误差。
对于题主提出的第一个问题,我猜可能是因为混淆了重构原数据和投影原数据这两个概念(不知道理解的对不对)。
当我们用PCA降维时(也就是题主所说的用原始高维矩阵去乘以特征向量所构成的低维矩阵),我们实际得到的数据点是下面这个样子:
这个是我们得到的投影后的数据,也就是我们用PCA希望得到的降维数据,你可以自行选择M的值以得到期望的维度数。因此这个时候的数据点和原始数据的维度是不一样的。但是用这个低维度的空间来重构原始数据的时候却是这个样子(当然这个是丢失了部分信息的):
这个时候不管M的值是多少,重构出来的数据和原始数据的维度都是一样的。
如果希望得到没有损失的数据,也就是原始数据,应该用这个式子来重构:
讲到这里我们发现,其实“降维”这个观念在PRML的PCA 推导过程中体现的并不是很明显,因为我们只是假设数据在某些方向的投影是data-dependent,有些是常数,并没有直接将这些维度去掉(之所以这么做感觉是为了尽可能的减少误差),“降维”这个点出现在之后的投影中,我们有选择性的将原始数据投影到一部分的基底上,因此得到了数据的低维度表示。 我个人更愿意将PCA理解为:用数量更少的,与原始数据维度相同的,相互正交的单位向量的线性组合去尽可能地逼近原始数据。
总得来说,投影在PCA的推导和应用都是很重要的一个知识点,PCA的推导其实是在做一系列坐标与基底之间的变换,在得到了想要的基底之后,直接做投影就行了。至于为什么高维度的原始数据矩阵乘以特征向量的矩阵就是最后的投影,题主将我上面写的那个降维得到的数据点的式子写成矩阵的乘法就知道原因了。
另外补充一点,关于计算的时候去不去平均值的问题,我个人认为是一定要去的,因为从推导中我们能看出来所求的特征向量是基于协方差矩阵的,而协方差矩阵的定义中就去掉了平均值。
发布于 2018-06-22
赞同 21 条评论
分享
收藏感谢收起
云飞
1 人赞同了该回答
两个问题主要与PCA是什么和为什么算法这样做相关。看前面的答案都说了PCA是降维用的,但是都没说什么是PCA,这与“最适合的低维空间”相关,“为什么要去均值”则与协方差矩阵相关。
首先PCA是什么:Principal Components Analysis,主成分分析,是“通过对一部分变量数据线性组合,来对协方差矩阵做出描述”。举例:X作为数据矩阵,n * p大小,n条数据,p个变量,每一条数据就是一个n*1的向量从x1到xp。协方差矩阵S,大小p * p。定义X上的线性组合Y=a‘*X,a是n*1的向量,表示为Y=a1*x1+a2*x2+...+ap*xp。定义完了,下面就是Principal Components 的定义了:
第一个主成分定义为:Y1=a'*X,要求Y1的variance即Var(a'*X)达到最大,且a的长度=1即a'*a=1;
第二个主成分定义为:Y2=b'*X,要求Y2的variance即Var(b'*X)达到最大,且b的长度=1即b'*b=1,多了一个条件 Y1和Y2的协方差为0,即Cov(Y1,Y2)=0,可以理解为a和b的内积为0,即a b互相垂直;(长度为1,互相垂直,刚好对称矩阵的特征向量满足)
下面的依次进行......
从上面可以看出PCA是定义在数据集X上的线性组合,要求使得Var(Y)达到最大,而Var(Y)=Var(a'*X)=a'*S*a,这样就和协方差矩阵相关了。
Var(Y1)取最大值即:


从这里可以看出,求Var(Y1)最大值的过程,就是取Σx最大特征值的过程。

ΣY=P'ΣXP 代入 ΣX=PΛP' 可得:ΣY=Λ,Y的协方差矩阵就是X协方差矩阵的对角化。
剩下的就是对S做分解,取特征值和特征向量,其他人都写了,我就不再多说。
“最适合的低维空间”,在做PCA时,尽可能留下最多的原协方差矩阵的信息,做法:把特征值从高到低排序,λ1 λ2 。。。λp,一个个加起来,直到占特征值总和的80%或者90%的那部分特征值。
乘以这个“k个特征向量分别作为列向量组成特征向量矩阵” 是线性变换做投影的方法,线性变换的集就是k个S的特征向量
”去均值“是为了减低大scale变量的影响。举例:有两个变量 销售额 和 价格,销售额都是几十万的量,价格 1-5元,这样的话销售额的方差会dominate协方差矩阵,其实应该是减去均值再除以标准差,一般都只减去均值做一下标准化。
编辑于 2017-11-01
赞同 1添加评论
分享
收藏感谢收起

刘垣德
数据挖掘
去均值后的原始矩阵乘以k个特征向量组成的矩阵,得到原始矩阵的投影。实际上是将中心化的原始矩阵投影到特征基准上,去除数据相关性。
发布于 2018-01-19
赞同添加评论
分享
收藏感谢

摄影测量与遥感
Photogrammetry
去均值,因为中心矩才能反应数据的离散程度
发布于 2017-12-13
赞同添加评论
分享
收藏感谢
曦日秋离
小白研究生
给个链接,希望能有帮助:PCA线性代数讲解 - gcaxuxi的博客 - CSDN博客
发布于 2017-08-16
赞同添加评论
分享
收藏感谢

石彼格海德
1 人赞同了该回答
svd可以用来降维,但svd不是pca。svd在某些情况下比pca要快。
发布于 2015-05-15