下面介绍Hbase的缓存机制:
a.HBase在读取时,会以Block为单位进行cache,用来提升读的性能
b.Block可以分类为DataBlock(默认大小64K,存储KV)、BloomBlock(默认大小128K,存储BloomFilter数据)、IndexBlock(默认大小128K,索引数据,用来加快Rowkey所在DataBlock的定位)
c.对于一次随机读,Block的访问顺序为BloomBlock、IndexBlock、DataBlock,如果Region下面的StoreFile数目为2个,那么一次随机读至少访问2次BloomBlock+1次IndexBlock+1次DataBlock
d.我们通常将BloomBlock和IndexBlock统称为MetaBlock,MetaBlock线上系统中基本命中率都是100%
e.Block的cache命中率对HBase的读性能影响十分大,所以DataBlockEncoding将KV在内存中进行压缩,对于单行多列和Row相似的场景,可以提高内存使用率,增加读性能
f.HBase中管理缓存的Block的类为BlockCache,其实现目前主要是下面三种,下面将着重介绍这三类Cache
1、LruBlockCache
默认的BlockCache实现,也是目前使用的BlockCache,使用一个HashMap维护Block Key到Block的映射,采用严格的LRU算法来淘汰Block,初始化时会指定容量大小,当使用量达到85%的时候开始淘汰block至75%的比例。
优点:直接采用jvm提供的HashMap来管理Cache,简单可依赖;内存用多少占多少,JVM会帮你回收淘汰的BlOCK占用的内存
缺点:
(1)一个Block从被缓存至被淘汰,基本就伴随着Heap中的位置从New区晋升到Old区
(2)晋升在Old区的Block被淘汰后,最终由CMS进行垃圾回收,随之带来的是Heap碎片
(3)因为碎片问题,随之而来的是GC时晋升失败的FullGC,我们的线上系统根据不同的业务特点,因为这个而发生FullGC的频率,有1天的,1周的,1月半年的都有。对于高频率的,在运维上通过在半夜手工触发FullGC来缓解
(4)如果缓存的速度比淘汰的速度快,很不幸,现在的代码有OOM的风险(这个可以修改下代码避免)
2、SlabCache
针对LruBlockCache的碎片问题一种解决方案,使用堆外内存,处于实验性质,真实测试后,我们定位为不可用。说下它的原理:它由多个SingleSizeCache组成(所谓SingleSizeCache,就是只缓存固定大小的block,其内部维护一个ByteBuffer List,每个ByteBuffer的空间都是一样的,比如64K的SingleSizeCache,ByteBuffer的空间都是64K,cache Block时把Block的内容复制到ByteBuffer中,所以block的大小必须小于等于64K才能被这个SingleSizeCache缓存;淘汰block的时候只需要将相应的ByteBuffer标记为空闲,下次cache的时候对其上的内存直接进行覆盖就行了),cache Block的时候,选择一个小于且最接近的SingleSizeCache进行缓存,淘汰block亦此。由于SingleSize的局限性,其使用上和LruBlockCache搭配使用,叫做DoubleBlockCache,cache block的时候LruBlockCache和SlabCache都缓存一份,get block的时候顺序为LruBlockCache、SlabCache如果只有SlabCache命中,那么再将block缓存到LruBlockCache中(本人觉得它的这个设计很费,你觉得呢)
优点:其思想:申请固定内存空间,Block的读写都在这片区域中进行
缺点:
(1)cache block和 get block的时候,需要内存复制
(2)SingleSizeCache的设计,导致内存使用率很低
(3)与LruBlockCache搭配使用不合理,导致所有的block都会去LruBlockCache中逗留一下,结果是CMS和碎片都不能有所改善
3、 BucketCache
可以看成是对SlabCache思想在实现上的一种改进及功能扩展,其优点是解决LruBlockCache的缺点及支持面向高性能读的大缓存空间,下面将着重介绍它的功效
3.1 何谓大缓存?
缓存Block的存储介质不再仅仅依赖在内存上,而是可以选择为Fusion-io、SSD等高速磁盘,我们称之为二级缓存
3.2 何谓Bucket?
我们将缓存空间划分为一个个的Bucket,每个Bucket都贴上一个size标签,将Block缓存在最接近且小于size的bucket中(和SingleSizeCache很相似)
3.3 怎么解决CMS 碎片问题?
Block存储在Bucket中,而每个Bucket的物理存储是不变的,也就是说系统刚启动的时候,我们就申请了一堆Bucket内存空间,而这些内存空间是一直在Old区,block的Get/Cache动作只是对这片空间的访问/覆写,CMS/碎片自然大大减少
3.4 怎么使用?BucketCache可以有两种用法
3.4.1 与LruBlockCache搭配,作为主要的内存cache方案使用

在hbase-site.xml中设置以下参数:
– “hbase.bucketcache.ioengine” “heap”
– “hbase.bucketcache.size” 0.4(bucket cache的大小, 0.4是最大对内存的比例)
– 可选配置
• “hbase.bucketcache.combinedcache.percentage” 默认是0.9f (在CombinedCache中的比例)
3.4.2 作为二级缓存使用,将Block缓存在我们的高速盘(Fusion-IO)中
在hbase-site.xml中设置以下参数:
– “hbase.bucketcache.ioengine” “file:/disk1/hbase/cache.data”(存储block数据的路径)
– “hbase.bucketcache.size” 10*1024 (bucket cache的大小, 单位是MB, 10*1024 是10GB)
– “hbase.bucketcache.combinedcache “ false
– 可选配置
• “hbase.bucketcache.persistent.path” “file:/disk1/hbase/cache.meta”(存储bucket cache的元数据的路径, 用于启动的时候恢复cache)
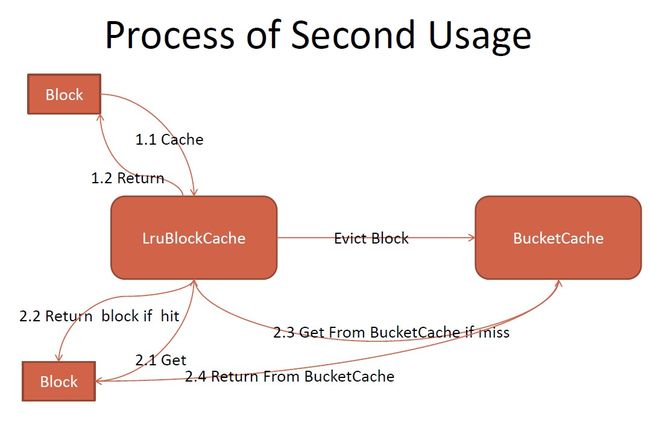
3.5.BucketCache中的Cache/Get Block逻辑?
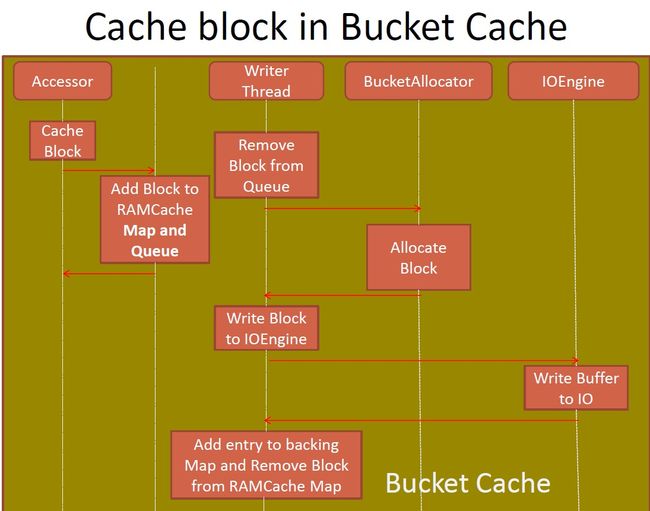
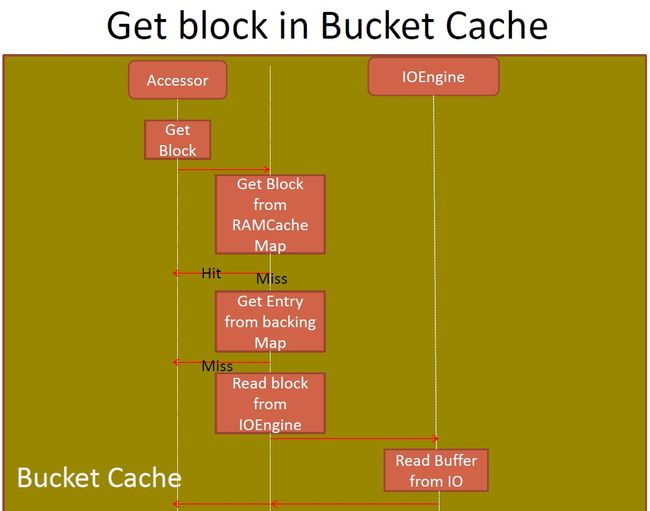
简单地描述下: CacheBlock的时候,将Block放在一个RAMMap和一个Queue中,然后WriterThread异步从Queue中remove Block写入到IOEngine(内存或高速盘)中,并将BlockKey及其位置、长度等信息记录在backingMap GetBlock的时候,先访问RAMMap,然后访问backingMap获取block的位置及长度,从IOEngine读取数据
3.6.Block在IOEngine中的位置是怎么分配的?

我们将物理空间划分为一堆等大的Bucket,每一个Bucket有一个序号及一个size标签,于是Block所在bucket的序号及其在bucket中的offset与block在物理空间的offset就形成了一一对应。我们通过BucketAllocator为指定大小的Block寻找一个Bucket进行存放,于是就得到了其在物理空间上的位置。
上图描述了BucketAllocator对于Bucket的组织管理:
(1) 每个Bucket都有一个size标签,目前对于size的分类,是在启动时候就确定了,如默认的有(8+1)K、(16+1)K、(32+1)K、(40+1)K、(48+1)K、(56+1)K、(64+1)K、(96+1)K ... (512+1)K
(2) 相同size标签的Bucket由同一个BucketSizeInfo管理
(3) Bucket的size标签可以动态调整,比如64K的block数目比较多,65K的bucket被用完了以后,其他size标签的完全空闲的bucket可以转换成为65K的bucket,但是至少保留一个该size的bucket
(4)如果最大size的bucket为513K,那么超过这个大小的block无法存储,直接拒绝
(5)如果某个size的bucket用完了,那么会依照LRU算法触发block淘汰
问题:
如果系统一开始都是某个size的block,突然变成另外个size的block(不能存在同个size的bucket中)会发生什么,是否还会不停地进行淘汰算法?
是的,但是由于淘汰是异步的,影响不大,而且随着淘汰进行,bucket的大小会逐渐向那个block size大小bucket转移,最终稳定
3.7 BucketAllocator中allocate block的流程?
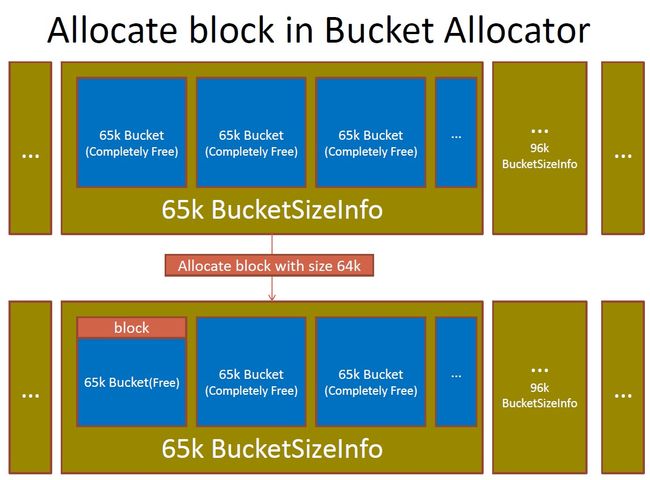

3.8 BucketAllocator中free block的流程?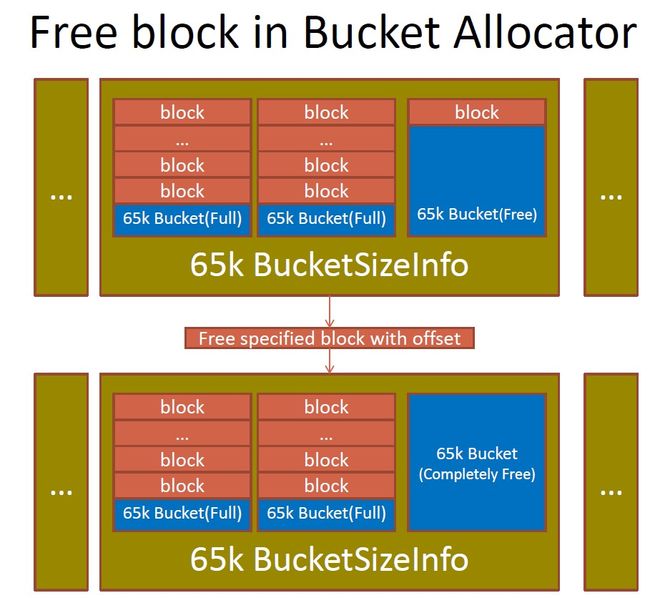
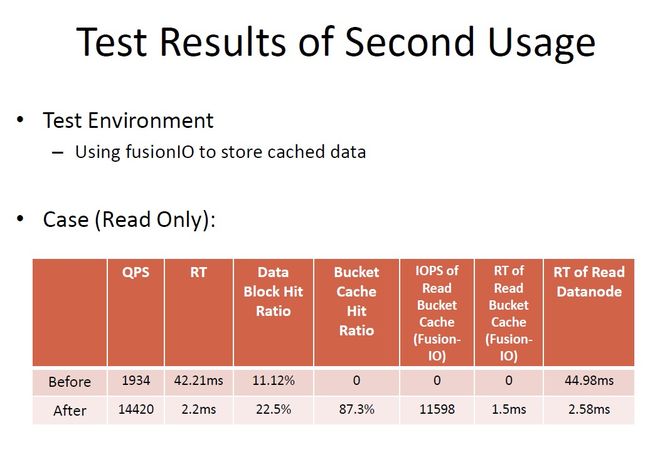
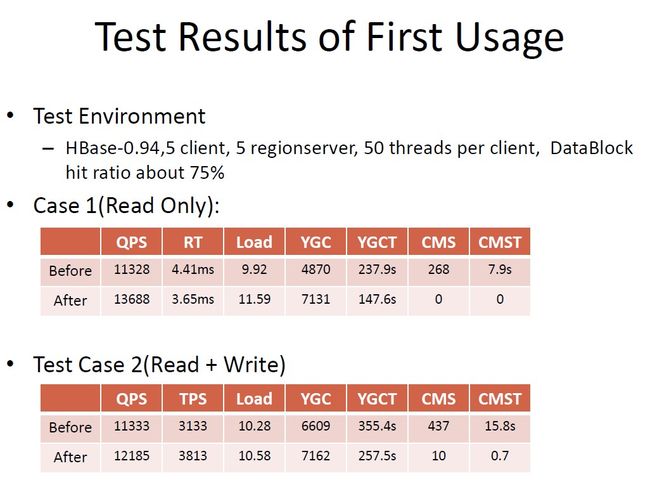
3.9 第一种使用的测试结果
3.10 第二种使用的测试结果