MIT6.824 Lab1 MapReduce
Introduction
本次实验主要是用go语言来实现1个MapReduce库,并且了解分布式系统的容错机制,推荐先看一下MapReduce的论文[MapReduce]
主要机制如下图:
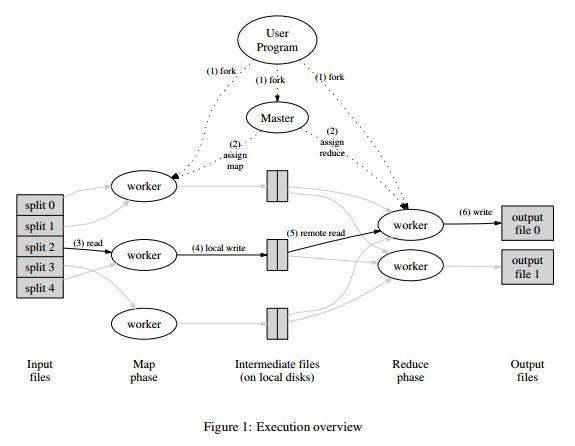
Map worker读入1个文件,处理后生成n(reduce worker数目)个中间文件,然后每个Reduce worker读取其对应的所有中间文件,处理后生成1个结果文件,最后n个结果文件可以merge成1个最终结果文件。
Software
由于实验中的代码是由go语言实现的,所以需要先去看看go的基本语法以及相关教程,链接在这里Go(ps:需要/(ㄒoㄒ)/~~)
使用git来下载实验的代码,repository为git://g.csail.mit.edu/6.824-golabs-2016。然后再去安装golang的编译器即可,这里实验中使用的是1.5版本。
Preamble: Getting familiar with the source
mapreduce包提供了1个简单的Map/Reduce库的串行实现。正常应用应该调用Distributed函数[master.go]来启动1个任务,但是可以通过调用Sequential函数[master.go]来进行debug。
mapreduce实现流程:
1、应用提供一些输入文件,1个map函数,1个recude函数,reduce worker的数目(nReduce)。
2、建立1个master节点,它启动1个RPC server(master_rpc.go),然后等待workers来注册(使用RPC call Register函数[master.go]). 当worker可用时(在第4、5步骤),schedule函数[schedule.go]决定如何分配任务到worker以及如何处理worker的failures。
3、master节点认为每个输入文件对应1个map任务,为每个任务至少调用1次doMap函数[common_map.go]。每次调用doMap函数会读取合适的文件,并调用map函数来处理文件内容,为每个map文件生成nReduce个文件。
4、master节点接下去为每个reduce任务至少调用1次doReduce函数[common_reduce.go]。doReduce函数收集nReduce个reduce文件,然后调用reduce函数处理这些文件,产生nReduce个结果文件。
5、master节点调用mr.merge函数[master_splitmerge.go],来整合nReduce个结果文件成1个最终文件。
6、master节点发送1个Shutdown的RPC调用到每个worker,来关闭它们的RPC server。
Part I: Map/Reduce input and output
首先是实现Map/Reduce的串行执行,在给出的代码中缺少2个关键的片段:将map任务的输出分割成nReduce个文件的 doMap函数[common_map.go],以及将reduce任务的nReduce个输入整合成1个文件的doReduce函数[common_reduce.go]。
为了帮助测试你的代码是否正确,实验中还提供了test文件[test_test.go]来测试。关于go test命令的说明可以看这里go test。
go test -run Sequential mapreduce/... run参数表示测试mapreduce文件夹下test_test.go文件中以Test开头包含Sequential的测试函数,即TestSequentialSingle和TestSequentialMany函数。这里针对TestSequentialSingle来分析一下具体流程,有助于编写doMap和doReduce函数。
func TestSequentialSingle(t *testing.T) {
mr := Sequential("test", makeInputs(1), 1, MapFunc, ReduceFunc)
mr.Wait()
check(t, mr.files)
checkWorker(t, mr.stats)
cleanup(mr)
}func Sequential(jobName string, files []string, nreduce int,
mapF func(string, string) []KeyValue,
reduceF func(string, []string) string,
) (mr *Master) {
mr = newMaster("master")
go mr.run(jobName, files, nreduce, func(phase jobPhase) {
switch phase {
case mapPhase:
for i, f := range mr.files {
doMap(mr.jobName, i, f, mr.nReduce, mapF)
}
case reducePhase:
for i := 0; i < mr.nReduce; i++ {
doReduce(mr.jobName, i, len(mr.files), reduceF)
}
}
}, func() {
mr.stats = []int{len(files) + nreduce}
})
return
}首先通过Sequential函数[master.go]来创建1个master结构体,然后运行1个goroutine来执行mr.run函数。其中master结构体的定义如下:
type Master struct {
sync.Mutex
address string
registerChannel chan string
doneChannel chan bool
workers []string // protected by the mutex
// Per-task information
jobName string // Name of currently executing job
files []string // Input files
nReduce int // Number of reduce partitions
shutdown chan struct{}
l net.Listener
stats []int
}主要是生成1个rpc server并记录一些状态信息(注册的worker,任务名,reduce的数量等)。
func (mr *Master) run(jobName string, files []string, nreduce int,
schedule func(phase jobPhase),
finish func(),
) {
mr.jobName = jobName
mr.files = files
mr.nReduce = nreduce
fmt.Printf("%s: Starting Map/Reduce task %s\n", mr.address, mr.jobName)
schedule(mapPhase)
schedule(reducePhase)
finish()
mr.merge()
fmt.Printf("%s: Map/Reduce task completed\n", mr.address)
mr.doneChannel <- true
} mr.run函数来执行具体的运行任务,其中重点是schedule(mapPhase)和schedule(reducePhase),这里schedule函数是调用时的1个匿名函数,主要功能是区分任务类型,对于map任务执行doMap函数,对于reduce任务执行doReduce函数,紧接着是调用mr.merge函数来整合nReduce个结果文件成1个最终文件,最后向doneChannel信道中写入true标识这次任务的结束。
在了解了整个流程后,我们来看一下如何实现doMap函数和doReduce函数。在common_map.go文件中有关于doMap函数功能的描述注释,主要操作是打开文件名为inFile的输入文件,读取文件内容,然后调用mapF函数来处理内容,返回值为KeyVaule结构体[common.go]实例,然后生成nReduce个中间文件,提示使用json格式写入。
// doMap does the job of a map worker: it reads one of the input files
// (inFile), calls the user-defined map function (mapF) for that file's
// contents, and partitions the output into nReduce intermediate files.
func doMap(
jobName string, // the name of the MapReduce job
mapTaskNumber int, // which map task this is
inFile string,
nReduce int, // the number of reduce task that will be run ("R" in the paper)
mapF func(file string, contents string) []KeyValue,
) {
inputFile, err := os.Open(inFile)
if err != nil {
log.Fatal("doMap: open input file ", inFile, " error: ", err)
}
defer inputFile.Close()
fileInfo, err := inputFile.Stat()
if err != nil {
log.Fatal("doMap: getstat input file ", inFile, " error: ", err)
}
data := make([]byte, fileInfo.Size())
_, err = inputFile.Read(data)
if err != nil {
log.Fatal("doMap: read input file ", inFile, " error: ", err)
}
keyValues := mapF(inFile, string(data))
for i := 0; i < nReduce; i++ {
fileName := reduceName(jobName, mapTaskNumber, i)
reduceFile, err := os.Create(fileName)
if err != nil {
log.Fatal("doMap: create intermediate file ", fileName, " error: ", err)
}
defer reduceFile.Close()
enc := json.NewEncoder(reduceFile)
for _, kv := range keyValues {
if ihash(kv.Key)%uint32(nReduce) == uint32(i) {
err := enc.Encode(&kv)
if err != nil {
log.Fatal("doMap: encode error: ", err)
}
}
}
}
}doReduce函数的实现类似,先从每个map函数的输出文件中获取该reduce任务相应的中间文件,然后根据key值进行排序,最后调用reduce函数来生成最终的结果并写入文件。
// doReduce does the job of a reduce worker: it reads the intermediate
// key/value pairs (produced by the map phase) for this task, sorts the
// intermediate key/value pairs by key, calls the user-defined reduce function
// (reduceF) for each key, and writes the output to disk.
func doReduce(
jobName string, // the name of the whole MapReduce job
reduceTaskNumber int, // which reduce task this is
nMap int, // the number of map tasks that were run ("M" in the paper)
reduceF func(key string, values []string) string,
) {
keyValues := make(map[string][]string, 0)
for i := 0; i < nMap; i++ {
fileName := reduceName(jobName, i, reduceTaskNumber)
file, err := os.Open(fileName)
if err != nil {
log.Fatal("doReduce: open intermediate file ", fileName, " error: ", err)
}
defer file.Close()
dec := json.NewDecoder(file)
for {
var kv KeyValue
err := dec.Decode(&kv)
if err != nil {
break
}
_, ok := keyValues[kv.Key]
if !ok {
keyValues[kv.Key] = make([]string, 0)
}
keyValues[kv.Key] = append(keyValues[kv.Key], kv.Value)
}
}
var keys []string
for k, _ := range keyValues {
keys = append(keys, k)
}
sort.Strings(keys)
mergeFileName := mergeName(jobName, reduceTaskNumber)
mergeFile, err := os.Create(mergeFileName)
if err != nil {
log.Fatal("doReduce: create merge file ", mergeFileName, " error: ", err)
}
defer mergeFile.Close()
enc := json.NewEncoder(mergeFile)
for _, k := range keys {
res := reduceF(k, keyValues[k])
err := enc.Encode(&KeyValue{k, res})
if err != nil {
log.Fatal("doReduce: encode error: ", err)
}
}
}Part II: Single-worker word count
这部分就是实现串行的word count,主要任务就是实现mapF函数和reduce函数。在论文中关于word count的伪代码如下:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));mapF函数的参数key为输入文件的文件名,value为文件内容,需要实现生成[word, “1”]这样的中间结果。在main/wc.go中有关于mapF函数实现的注释。其中涉及到字符串的处理(string和rune),可以读一下hint中的go string。
// The mapping function is called once for each piece of the input.
// In this framework, the key is the name of the file that is being processed,
// and the value is the file's contents. The return value should be a slice of
// key/value pairs, each represented by a mapreduce.KeyValue.
func mapF(document string, value string) (res []mapreduce.KeyValue) {
// TODO: you have to write this function
values := strings.FieldsFunc(value, func(c rune) bool {
return !unicode.IsLetter(c)
})
for _, v := range values {
res = append(res, mapreduce.KeyValue{v, "1"})
}
return res
} 先对于文件内容value进行分割,用strings.FieldsFunc函数来分割成单词。然后对于每个单词,将[word,”1”]加入到中间结果中。
对于reduceF函数,参数key为word,参数values就是[“1”,”1”, …]形式的字符串切片,主要操作就是统计该单词的出现次数,即累加values中的元素即可,使用strconv库提供的函数将字符串转换为数值,最后将统计和结果转换为字符串返回。
func reduceF(key string, values []string) string {
// TODO: you also have to write this function
var sum int
for _, v := range values {
count, err := strconv.Atoi(v)
if err != nil {
log.Fatal("reduceF: strconv string to int error: ", err)
}
sum += count
}
return strconv.Itoa(sum)
}Part III: Distributing MapReduce tasks
这里就要实现分布式的Map/Reduce。我们先前的实现是串行的,即一个个地执行map和reduce任务,比较简单但是性能不高。这部分我们要利用多核,将任务分发给多个worker线程。虽然这不是真实环境中的多机分布式,但是我们将使用RPC和channel来模拟分布式计算。
为了协同任务的并行执行,我们将使用1个特殊的master线程,来分发任务到worker线程并等待它们完成。实验中提供了worker的实现代码和启动代码(mapreduce/worker.go)以及RPC消息处理的代码(mapreduce/common_rpc.go)。
我们的任务实现mapreduce包中的schedule.go文件,尤其是其中的schedule函数来分发map和reduce任务到worker,并当它们完成后才返回。
先前我们分析过mr.run函数[master.go],里面会调用schedule函数来运行map和reduce任务,然后调用merge函数来将每个reduce任务的结果文件整合成1个最终文件。schedule函数只需要告诉worker输入文件的文件名(mr.files[task])和任务号。master节点通过RPC调用Worker.DoTask,传递1个DoTaskArgs对象作为RPC的参数来告诉worker新的任务。
当1个worker启动时,它会发送1个注册RPC给master,传递新worker的信息到mr.registerChannel。我们的schedule函数通过读取mr.registerChannel来获得可用的worker。
这里可以读一下hint中go的RPC文档RPC和并发文档concurrency,来了解一下RPC的实现和如何保护并发处理。
schedue函数的实现如下:
// schedule starts and waits for all tasks in the given phase (Map or Reduce).
func (mr *Master) schedule(phase jobPhase) {
var ntasks int
var nios int // number of inputs (for reduce) or outputs (for map)
switch phase {
case mapPhase:
ntasks = len(mr.files)
nios = mr.nReduce
case reducePhase:
ntasks = mr.nReduce
nios = len(mr.files)
}
fmt.Printf("Schedule: %v %v tasks (%d I/Os)\n", ntasks, phase, nios)
var wg sync.WaitGroup
for i := 0; i < ntasks; i++ {
wg.Add(1)
go func(taskNum int, nios int, phase jobPhase) {
defer wg.Done()
for {
var args DoTaskArgs
worker := <-mr.registerChannel
args.JobName = mr.jobName
args.File = mr.files[taskNum]
args.Phase = phase
args.TaskNumber = taskNum
args.NumOtherPhase = nios
ok := call(worker, "Worker.DoTask", &args, new(struct{}))
if ok {
go func() {
mr.registerChannel <- worker
}()
break
}
}
}(i, nios, phase)
}
wg.Wait()
fmt.Printf("Schedule: %v phase done\n", phase)
}主要过程是先区分一下这是map任务还是reduce任务,对于map任务,任务数ntask为输入文件的个数,io数nios为reduce worker的数目nReduce,对于reduce任务,任务数ntask为reduce worker的数目nReduce,io数nios为map worker的数目即输入文件的个数。然后创建1个同步包sync中的等待组WaitGroup,对于每个任务,将其加入到等待组中,并运行1个goroutine来运行进行分发任务。首先从mr.registerChannel中获得1个可用的worker,构建DoTaskArgs对象,作为参数调用worker的Worker.DoTask来执行任务,当其完成任务后将其重新加入到mr.registerChannel表示可用。最后使用WaitGroup的wait函数等待所有任务完成。因为只有当map任务都完成后才能执行reduce任务。
Part IV: Handling worker failures
这部分主要是使master节点能处理worker的宕机。当1个worker宕机时,master发送的RPC都会失败,那么久需要重新安排任务,将宕机worker的任务分配给其它worker。
RPC的失败并不是表示worker的宕机,worker可能只是网络不可达,仍然在工作计算。所以如果重新分配任务可能造成2个worker接受相同的任务并计算。但是这没关系,因为相同的任务生成相同的结果。我们只要实现重新分配任务即可。
这1点体现在上面schedule函数的第2个无限for循环中,当RPC的call失败时,仅仅就是重新选取1个worker,只有当成功时,才会break。
Part V: Inverted index generation (optional)
word count实现的是统计一些文档中单词出现的总次数,而这里需要实现统计有单词出现的文档数,即同1个文档中出现多次,只算1次。伪代码如下:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, key);
reduce(String key, Iterator values):
// key: a word
// values: a list of documents
values = set(vaules) //function set remove redundancy
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));在mapF函数中操作与原先的word count类似,只是生成的中间结果形式变为[word, document]。
func mapF(document string, value string) (res []mapreduce.KeyValue) {
// TODO: you should complete this to do the inverted index challenge
values := strings.FieldsFunc(value, func(c rune) bool {
return !unicode.IsLetter(c)
})
for _, v := range values {
res = append(res, mapreduce.KeyValue{v, document})
}
return res
}在reduceF函数中,此时values为document的字符串切片,需要先去冗余,即实现set,由于go语言不提供set,可以用map来模拟实现,然后根据输出构造结果字符串。
func reduceF(key string, values []string) string {
// TODO: you should complete this to do the inverted index challenge
var res []string
set := make(map[string]int)
for _, str := range values {
_, ok := set[str]
if !ok {
set[str] = 1
res = append(res, str)
}
}
sort.Strings(res)
num := len(res)
line := strconv.Itoa(num)
line += " "
for i, value := range res {
if i != num-1 {
line += value + ","
} else {
line += value
}
}
return line
}Running all tests
至此Lab1就结束了,可以通过运行src/main/test-mr.sh来测试所有部分的结果。