从0开始学习spark的学习笔记(2)手把手教你Spark第一个程序WorldCount
Spark零基础入门第二课
- 在 IDEA 中编写第一个Spark程序 WordCount
- 修改 Spark 的日志级别

所谓学习是要在快乐中进行的,每天放松一下。
在 IDEA 中编写第一个Spark程序 WordCount
昨天我们学习了spark的本地搭建和一些基本的概念之后,我们今天开始我们的第一个程序的搭建。
(在生产环境中,通常会在 IDEA 中编 制程序,然后打成 jar 包,然后提交到集群,最常用的是创建一个 Maven 项目,利用 Maven 来管理 jar 包的依赖。)
1、创建一个 IDEA 的 maven 项目
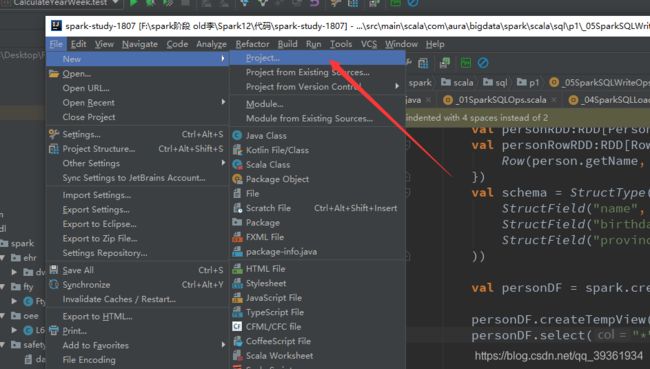 2、选择 Maven 项目,然后点击 next
2、选择 Maven 项目,然后点击 next


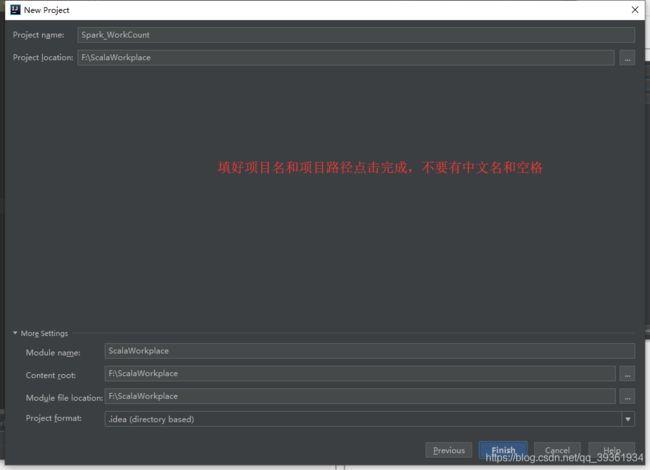
现在我们Maven项目建好了,然后我们建一个scala文件夹如上图:
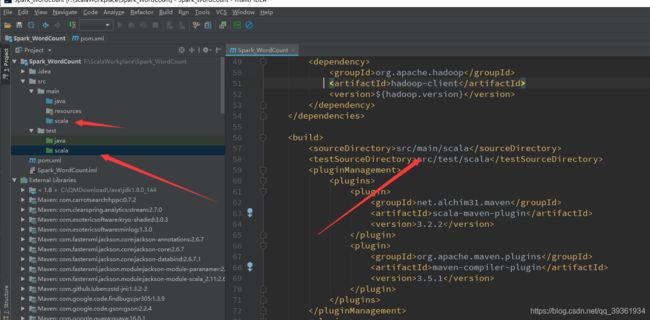
然后开始配置我们的pom.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.mazh.spark</groupId>
<artifactId>Spark_WordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<spark.version>2.3.0</spark.version>
<hadoop.version>2.7.5</hadoop.version>
<scala.compat.version>2.11</scala.compat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
然后我们新建一个 Scala Class 类型为 Object,编写 WordCount 程序
package com.dandan.spark
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// 不打印日志信息 减少控制台输出
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.project-spark").setLevel(Level.WARN)
// 创建一个 SparkConf对象,并设置程序的名称 ,和spark启动方式
val dandanSparkConf = new SparkConf().setAppName("dandan").setMaster("local")
// 创建一个 SparkContext对象
val sparkContext = new SparkContext(dandanSparkConf)
// 读取本地文件返回Rdd对象
val lineRdd = sparkContext.textFile("C:\\Users\\ASUS\\Desktop\\新建文本文档.txt")
// 构建一个单词 RDD
val wordAndOneRDD = lineRdd.flatMap(_.split("==")).map((_, 1))
// 进行单词的聚合
val resultRDD = wordAndOneRDD.reduceByKey(_ + _)
// 对 resultRDD进行单词出现次数的降序排序,然后写出结果到 HDFS
resultRDD.sortBy(_._2, false).foreach(r => println(r))
sparkContext.stop()
}
}
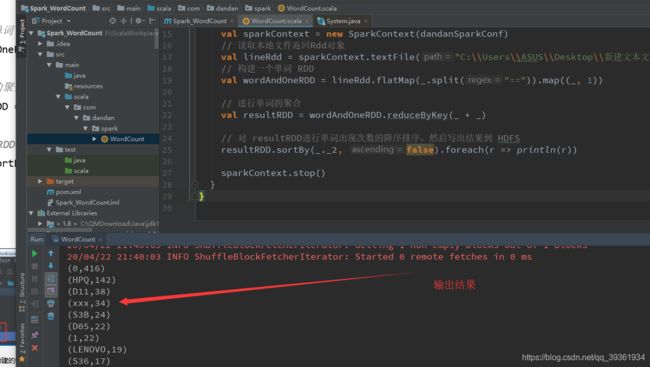

我这里把数据给你们,我们一起学习进步,希望还在学校或者刚刚工作准备学spark的可以和我一起学习动手:
D01A==P1XY1==0P1XY1==0==10==0
D06A==DXJD9==D10-CARNAGE==0==5==33.83
S3A==10036Y100-600-H==HPQ==0==8==0
S31==T-PANGUL-H==HPQ==0==1==0
D02==7WP95==D9.5-SFF3==0==2107==13.17
D02==7WP95==D9.5-SFF3==0==2199==13.17
D02==7WP95==D9.5-SFF3==0==4019==13.17
S3A==L61705-001==HPQ==0==100==24.93
D11==KYJ8C==D9-MFF7==0==15==0
S3B==L76447-001-B==HPQ==0==9==0
D07==CWR57==D9-SFF-XE3==0==3==13.86
D03==5YDCW==D9.5-MFF3==0==3315==15.83
D03==5YDCW==D9.5-MFF3==0==10653==15.83
D03==5YDCW==D9.5-MFF3==0==3026==15.83
S3B==754109-001==HPQ==0==372==0
S31==SB20T22662==LENOVO==0==9==0
S35==SB20N60191==LENOVO==1453==1481==0
S35==SB20N60191==LENOVO==0==3197==0
xxx==844781-001==HPQ==0==492==0
xxx==844781-001==HPQ==0==15==0
xxx==844781-001==HPQ==0==692==0
S3F==902760-002==HPQ==0==70==1.80
这就完成我们的第一个spark编程wordcount程序,然后我在说一下怎么打包到集群上去运行,首先我们把我们刚刚写好的程序进行maven打包如下:
上传打好的 jar 包到 spark 集群中的用来提交任务的节点
put c:/Spark_WordCount-1.0-SNAPSHOT.jar
执行命令:
$SPARK_HOME/bin/spark-submit \
--class com.mazh.spark.WordCount \
--master spark://hadoop02:7077 \ 这个是节点ip地址映射和端口 按照自己的配置
--executor-memory 512m \
--total-executor-cores 4 \
/home/hadoop/Spark_WordCount-1.0-SNAPSHOT.jar \
hdfs://myha01/spark/wc/input \ 输入文件路径
hdfs://myha01/spark/wc/output_11 输出文件路径
最后两个路径如何是main函数传入的参数如下改动代码:

记得打包之前先改代码哟,我是忘记了,你们不要忘了!
结果类似如下: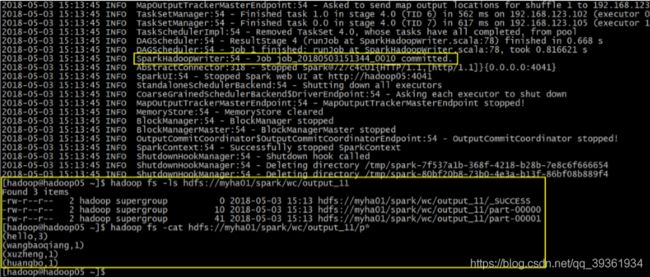
修改 Spark 的日志级别
这个顺带一提:从我们运行的 spark 程序运行的情况来看,可以看到大量的 INFO 级别的日志信息。淹没了 我们需要运行输出结果。可以通过修改 Spark 配置文件来 Spark 日志级别
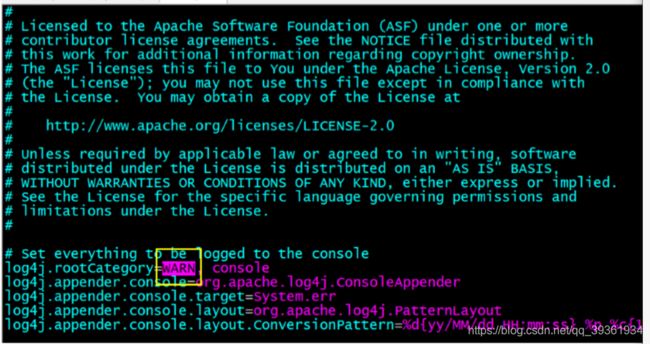
第一步:先进入 conf 目录 [hadoop@hadoop05 conf]$ cd $SPARK_HOME/conf
第二步:准备 log4j.properties [hadoop@hadoop05 conf]$ cp log4j.properties.template log4j.properties
第三步:配置日志级别: 把 INFO 改成你想要的级别:主要有 ERROR, WARN, INFO, DEBUG 几种
这一节 我们的spark wordcount 程序算完成了,然后我们之后再来说Spark作业提交的一些理论知识,和一下job提交的几种方法!

下次我们还要来学习哟!!!
记得点赞加关注!!! 不迷路 !!!
人活着真累:上车得排队,爱你又受罪,吃饭没香味,喝酒容易醉,挣钱得交税!