C语言一维数组的定义与常见用法
一维数组的定义与初始化
一维数组指的是只有一个下标的数组,它用来表示一组具有相同类型的数据。在C语言中,一维数组的定义方式如下所示
类型说明符 数组名[常量表达式];
在上述语法格式中,类型说明符表示数组中所有元素的类型,常量表达式指的是数组的长度,也就是数组中存放元素的个数。
例
int array[5l;
上述代码定义了一个数组,其中,int是数组的类型,aray是数组的名称,方括号中的5是数组的长度。完成数组的定义后,只是对数组中的元素开辟了一块内存空间。这时,如果想使用数组操作数据,还需要对数组进行初始化。数组初始化的常见的方式有3种,具体如下
(1)直接对数组中的所有元素赋值,示例代码如下:
int i[5]={1,2,3,4,5};
上述代码定义了一个长度为5的数组i,并且数组中元素的值依次为1、2、3、4、5。
(2)只对数组中的一部分元素赋值,示例代码如下
int i[5]={1,2,3};
在上述代码中,定义了一个int类型的数组,但在初始化时,只对数组中的前3个元素进行了赋值,其他元素的值会被默认设置为
(3)对数组全部元素赋值,但不指定长度,示例代码如下:
int i[]={1,2,3,4};
在上述代码中,数组i中的元素有4个,系统会根据给定初始化元素的个数定义数组的长度,因此,数组i的长度为4。
注意
(1)数组的下标是用方括号括起来的,而不是圆括号;
(2)数组名的命名同变量名的命名规则相同;
(3)数组定义中,常量表达式的值可以是符号常量,如下面的定义就是合法的。
int a[N]; //假设预编译命令#define N 4,下标是符号常量
一维数组的引用
在程序中,经常需要访问数组中的一些元素,这时可以通过数组名和下标来引用数组中
的元素。一维数组元素的引用方式如下所示:
数组名 [下标];
在上述方式中,下标指的是数组元素的位置,数组元素的下标是从0开始的。例如,引用数组X的第3个元素的方式为X[2]为了帮助大家更好地理解数组元素的引用榜下业通计一个室例来演示,如下所示:
#include
void main(int argc, char *argv[]){
int x[5] = {2,3,1,4,6};
int i;
for (i = 0; i < 5; i++) {
printf("%d\n", 2 * x[i]);
}
}
运行结果若下图所示:

在上面案例中,首先定义了一个数组x,然后通过下标的形式获取到数组中的元素,最后将元素乘以2后输出。
注意
数组的下标都有一个范围,即“0~[数组长度-1]”,假设数组的长度为6,其下标范围为0~5。当访问数组中的元素时,下标不能超出这个范围,否则程序会报错。
一维数组的常见操作
数组在编写程序时应用非常广泛,如经常需要对数组进行遍历、获取最值、排序等操作灵活地使用数组对实际开发很重要。接下来针对一维数组的常见操作进行详细的讲解,具体如下。
1、一维数组的遍历
在操作数组时,经常需要依次访问数组中的每个元素,这种操作称作数组的遍历。接下来使用for循环依次遍历数组中的元素,如下所示:
#include
void main(int argc, char *argv[]){
int x[5] = {2,3,1,4,6};
int i = 0;
for (i = 0; i < 5; i++) {
printf("x[%d]:%d\n", i, x[i]);
}
}
运行结果如下:
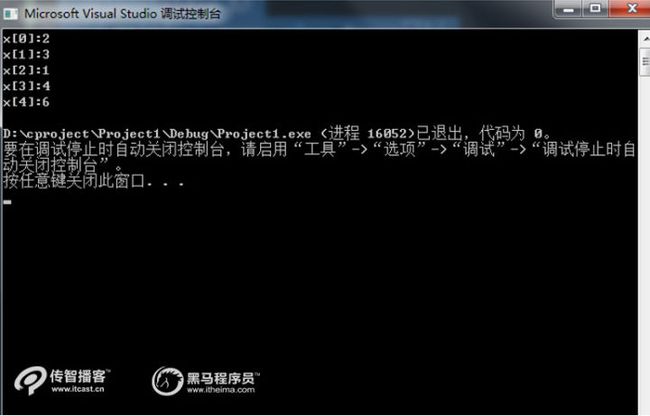
在上面案例中,首先定义了一个长度为5的数组X,然后定义了一个变量,由于数组的下标范围为0-4,因此可以将i的值作为下标,依次去访问数组中的元素,并将元素的值输出。
2、一维数组的最值
在操作数组时,经常需要获取数组中元素的最值。接下来通过案例演示如何获得数组中最大的数值。
#include
int main(int argc, char *argv[]){
int x[5] = {2,3,1,4,6};
int nMax = x[0];
int i = 0;
for (i = 0; i < 5; i++) {
if (x[i] > nMax) {
nMax = x[i];
}
}
printf("max:%d\n", nMax);
return 0;
}
运行结果如下
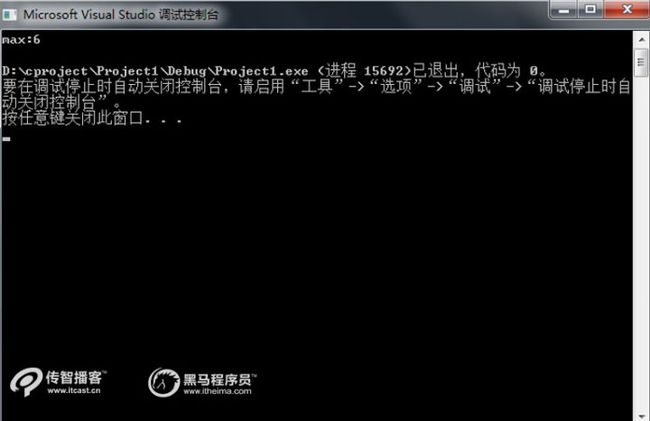
在上面案例找那个实现了获取数组X最大值的功能。在第5行代码中假定数组中的第1个元素为最大值,并将其赋值给nMax,在第7~13行代码对数组中的其他元素进行遍历,如果发现比mMax值大的元素,就将最大值nMx设置为这个元素的值,这样,当数组遍历完成后,nMax中存储的就是数组中的最大值。
3、一维数组的排序
在操作数组时,经常需要对数组中的元素进行排序。接下来为大家介绍一种比较常见的排序算法一冒泡排序。在冒泡排序的过程中,不断地比较数组中相邻的两个元素,较小者向上浮、较大者往下沉,整个过程和水中气泡上升的原理相似,接下来,分步骤讲解冒泡排序的整个过程,具体如下。
第1步,从第1个元素开始,将相邻的两个元素依次进行比较,直到最后两个元素完成比较。如果前1个元素比后1个元素大,则交换它们的位置。整个过程完成后,数组中最后1个元素自然就是最大值,这样也就完成了第1轮的比较。
第2步,除了最后1个元素,将剩余的元素继续进行两两比较,过程与第1步相似,这样就可以将数组中第二大的数放在倒数第2个位置。
第3步,依次类推,持续对越来越少的元素重复上面的步骤,直到没有任何一对元素需要比较为止。
了解了冒泡排序的原理之后,接下来通过一个案例来实现冒泡排序。

在上面的案例中,通过嵌套for循环实现了冒泡排序。其中,外层循环用来控制进行多少轮比较,每一轮比较都可以确定1个元素的位置,由于最后1个元素不需要进行比较,因此,外层循环的次数为数组的长度-1,内层循环的循环变量用于控制每轮比较的次数,在每次比较时,如果前者小于后者,就交换两个元素的位置。下面通过一张动图来演示冒泡排血的运算过程。
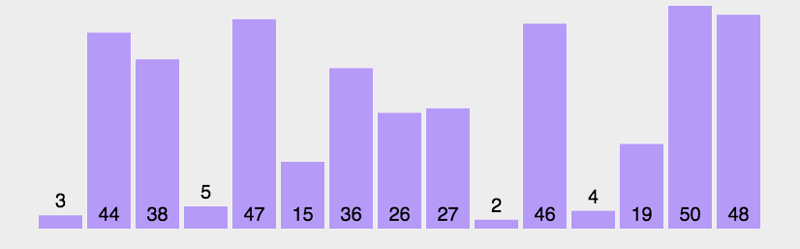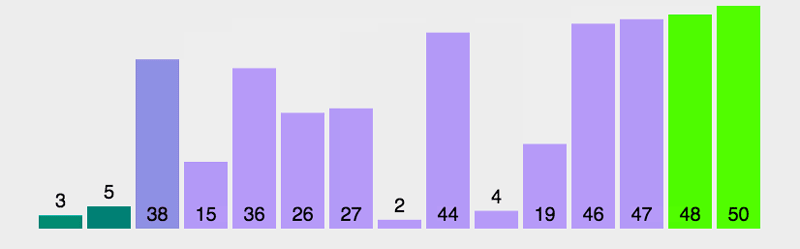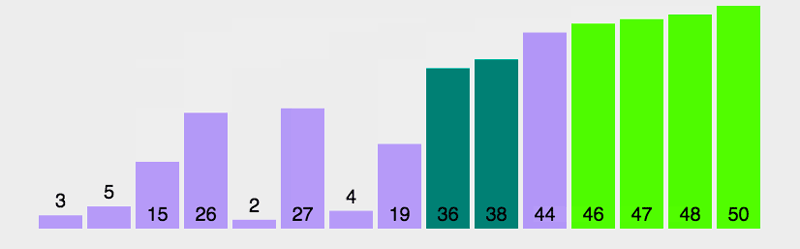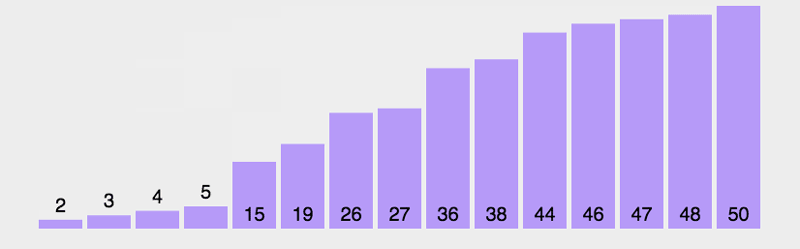
学C++推荐http://yun.itheima.com/map/25.html?2020zylyk