基于高可用配置的RabbitMQ集群实践
本文将提供一个基于高可用配置的RabbitMQ集群方案。通过介绍RabbitMQ的基本概念、主要作用和使用场景,并搭建RabbitMQ单节点环境、用程序演示消息发送接收过程,以及搭建RabbitMQ高可用集群环境,来生动而完整地介绍整个集群方案。并结合自己的实践,分享一些在集群环境下的客户端开发优化经验。
本文内容主要包括以下几个方面:
1、RabbitMQ基础介绍
2、RabbitMQ单节点环境的实践
3、RabbitMQ高可用集群环境的实践
4、总结
一、 RabbitMQ基础介绍
RabbitMQ是基于AMQP(Advanced Message Queuing Protocol,高级消息队列协议)实现的消息中间件。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息接收者的存在,反之亦然。RabbitMQ有很多优点:
1、支持集群环境和高可用队列,鲁棒性强
2、支持丰富的开发平台,如Java、.NET、Python、Perl、PHP、JavaScript等;
3、可运行在大多数操作系统;
4、开源、有活跃的社区、有丰富的插件。
RabbitMQ作为消息代理(message broker),给我们提供了发送、接收消息的平台,并能在消息被接收之前保持其持久性。通常用于应用程序之间、以及程序内各组件之间的消息传递等场景。比如,用于实现Java程序与Perl程序之间的消息传递;又如在Java Web程序中用于后台功能模块与前台通知模块之间的消息传递,等等。
在使用RabbitMQ进行客户端开发之前,我们需要了解下它的基本组件和概念:
Broker: 消息队列服务器,是接受客户端连接,实现AMQP消息队列和路由功能的进程。
1、Virtual Host: 是一个逻辑概念,一个Virtual Host里面可以有若干个Exchange和Queue,它是权限控制的最小单元。
2、Queue: 消息队列载体,用于存储消息。
3、Exchange: 路由,用于接收消息并根据Binding规则将消息路由给服务器中的队列。
4、Binding: 绑定,用于把Exchange和Queue按照路由规则绑定起来。
5、RoutingKey: 路由关键字,Exchange根据这个关键字进行消息投递。
6、Connection: 连接,一个位于客户端和Broker之间的TCP连接。
7、Channel: 消息通道,在客户端的每个Connection里可建立多个Channel,每个channel代表一个会话。之所以需要Channel,是因为TCP连接的建立和释放都是十分昂贵的。
二、 RabbitMQ单节点环境的实践
上面简单介绍了RabbitMQ的作用和优点,以及基本组件和概念。接下来,我们以Ubuntu 14.04 LTS 64bit的服务器为例,动手搭建一个RabbitMQ Server的单节点环境(当前最新版是rabbitmq-server_3.6.5),并编写java程序来测试RabbitMQ发送、接受消息的具体过程,具体步骤如下:
1. 通过APT方式安装RabbitMQ服务
1.1 添加APT库到本地软件更新的服务器地址列表中:
echo 'deb http://www.rabbitmq.com/debian/ testing main' |sudo tee /etc/apt/sources.list.d/rabbitmq.list
1.2 下载RabbitMQ的公钥并添加到本地trusted数据库中:
wget -O- https://www.rabbitmq.com/rabbitmq-release-signing-key.asc |sudo apt-key add -
1.3 更新APT库软件包列表:
sudo apt-get update
1.4 安装RabbitMQ软件包(安装之后默认启动):
sudo apt-get install rabbitmq-server
2. 启用常用插件,包括管理插件、web-stomp插件等
rabbitmq-plugins enable rabbitmq_management rabbitmq_web_stomp rabbitmq_stomp
3. 添加管理用户并授权
RabbitMQ安装之后,会创建默认的Virtual Host(即“/”),以及默认的管理账户(guest/guest),但该guest账户只能以localhost方式连接到Broker。如果需要远程访问Broker, 我们可以通过配置新的管理员账户来实现。
rabbitmqctl add_user admin admin
rabbitmqctl set_user_tags admin administrator
rabbitmqctl set_permissions -p / admin '.*' '.*' '.*'
4. 重启服务
service rabbitmq-server restart

▲RabbitMQ安装过程
另外,通过service rabbitmq-server status 命令可以查看该服务是否正常运行
5. 访问管理页面
重启服务之后,在浏览器中输入http://{server_ip}:15672,并用上面新建的admin/admin账户来登录,即可监控RabbitMQ的运行情况。
通过管理页面,我们可以管理Connection、Channel、Exchange、Queue等组件,并能够通过Admin模块来管理User、Virtual Host及Policy。
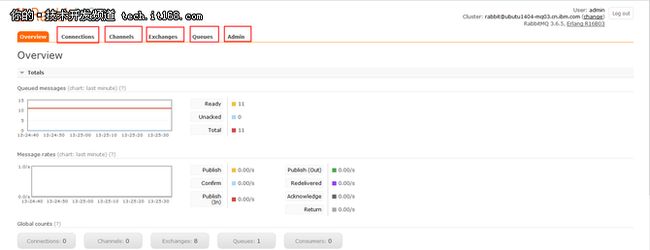
▲RabbitMQ管理页面(需启用管理插件)
6. 使用Java程序发送、接收消息
现在我们来通过java程序来实现一个简单的生产者-消费者模型。生产者(P)发送消息到Broker的Queue中,消费者(C)从Broker的Queue中获取消息。如下图:

▲基于消息队列的生产者消费者模型
6.1 编写生产者java类:Send.java

▲Send.java
6.2 编写消费者java类:Recv.java
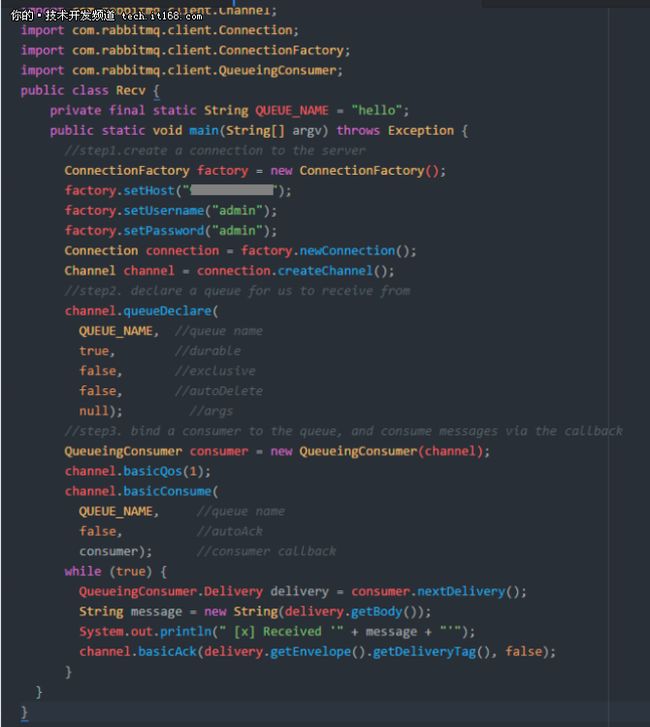
▲Recv.java
6.3 运行程序Send.java及Recv.java,查看消息发送、接收情况。

▲Send.java与Recv.java执行结果
三、 RabbitMQ高可用集群环境的实践
集群是保证服务可靠性的一种方式,同时可以通过水平扩展以提升消息吞吐能力。RabbitMQ是用分布式程序设计语言erlang开发的,所以天生就支持集群。接下来,将介绍RabbitMQ分布式消息处理方式、集群模式、节点类型,并动手搭建一个高可用集群环境,最后通过java程序来验证集群的高可用性。
1. 三种分布式消息处理方式
RabbitMQ分布式的消息处理方式有以下三种:
1、Clustering:不支持跨网段,各节点需运行同版本的Erlang和RabbitMQ, 应用于同网段局域网。
2、Federation:允许单台服务器上的Exchange或Queue接收发布到另一台服务器上Exchange或Queue的消息, 应用于广域网,。
3、Shovel:与Federation类似,但工作在更低层次。
RabbitMQ对网络延迟很敏感,在LAN环境建议使用clustering方式;在WAN环境中,则使用Federation或Shovel。我们平时说的RabbitMQ集群,说的就是clustering方式,它是RabbitMQ内嵌的一种消息处理方式,而Federation或Shovel则是以plugin形式存在。
2. 两种集群模式

▲RabbitMQ集群结构
2.1 普通模式(默认)
图7是由3个节点(Node1,Node2,Node3)组成的RabbitMQ普通集群环境,Exchange A的元数据信息在所有节点上是一致的;而Queue的完整信息只有在创建它的节点上,各个节点仅有相同的元数据,即队列结构。
当producer发送消息到Node1节点的Queue1中后,consumer从Node3节点拉取时,RabbitMQ会临时在Node1、Node3间进行消息传输,把Node1中的消息实体取出并经过Node3发送给consumer。
该模式存在一个问题:当Node1节点发生故障后,Node3节点无法取到Node1节点中还未被消费的消息实体。如果消息没做持久化,那么消息将永久性丢失;如果做了持久化,那么只有等Node1节点故障恢复后,消息才能被其他节点消费。
2.2 镜像模式(基于镜像队列)
它是在普通模式的基础上,把需要的队列做成镜像队列,存在于多个节点来实现高可用(HA)。该模式解决了上述问题,Broker会主动地将消息实体在各镜像节点间同步,在consumer取数据时无需临时拉取。
该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被大量消耗。通常地,对可靠性要求较高的场景建议采用镜像模式。
3. 两种集群节点类型
1、RAM Node(内存节点):将所有的Virtual Host、Queue、Exchange、Binding、User等的元数据存储在内存中,因此性能比较出色。
2、DISC Node(磁盘节点): 将元数据存储在磁盘中。
注:RabbitMQ单节点环境只允许是磁盘节点,防止重启RabbitMQ时丢失系统的配置信息。RabbitMQ集群环境至少要有一个磁盘节点,因为当节点加入或者离开集群时,必须要将该变更通知到至少一个磁盘节点。
4. 搭建普通集群环境
现在,将以图7为例来搭建普通集群环境。
4.1 首先根据上文“RabbitMQ单节点环境的搭建”章节相关内容,准备好以下3个节点:

▲各节点配置信息(待设置)
4.2 设置各节点的hostname:
vim /etc/hostname
……
reboot
注:其他Linux发行版可能需要通过“vim /etc/sysconfig/network”来修改hostname
4.3 修改各节点的hosts文件,并添加以下DNS信息:
vim /etc/hosts
192.168.1.10 rabbit01 rabbit01
192.168.1.20 rabbit02 rabbit02
192.168.1.30 rabbit03 rabbit03
4.4 将各节点的erlang.cookie设置为相同值,比如都使用rabbit01节点的值:
#先备份原cookie文件
rabbit02# cp /var/lib/rabbitmq/.erlang.cookie /var/lib/rabbitmq/.erlang.cookie.bak
rabbit03# cp /var/lib/rabbitmq/.erlang.cookie /var/lib/rabbitmq/.erlang.cookie.bak
#修改cookie的值
chmod 777 /var/lib/rabbitmq/.erlang.cookie
vim /var/lib/rabbitmq/.erlang.cookie
……
chmod 400 /var/lib/rabbitmq/.erlang.cookie
4.5 停止所有节点上的RabbitMQ服务,然后以detached方式独立运行:
rabbit01# rabbitmqctl stop
rabbit02# rabbitmqctl stop
rabbit03# rabbitmqctl stop
rabbit01# rabbitmq-server -detached
rabbit02# rabbitmq-server -detached
rabbit03# rabbitmq-server -detached
4.6 查看各节点的集群信息:
rabbit01# rabbitmqctl cluster_status
rabbit02# rabbitmqctl cluster_status
rabbit03# rabbitmqctl cluster_status
可以看到,各节点均以单磁盘节点的集群方式各自运行着。
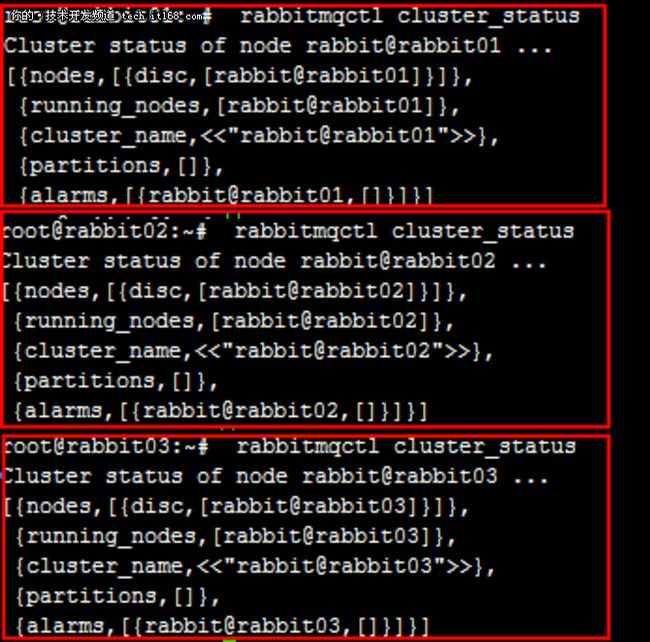
▲各节点集群信息查询(加入集群前)
4.7 将rabbit02、rabbit03 作为内存节点,加入到rabbit01的集群中
rabbit02# rabbitmqctl stop_app
rabbit02# rabbitmqctl join_cluster --ram rabbit@rabbit01
rabbit02# rabbitmqctl start_app
rabbit03# rabbitmqctl stop_app
rabbit03# rabbitmqctl join_cluster --ram rabbit@rabbit01
rabbit03# rabbitmqctl start_app
4.8 再次查看各节点的集群信息:
rabbit01# rabbitmqctl cluster_status
rabbit02# rabbitmqctl cluster_status
rabbit03# rabbitmqctl cluster_status
可以看到,各节点处于一个由rabbit01(disc node)、rabbit02(ram node)、rabbit03(ram node)组成的集群,名为“rabbit@rabbit01”
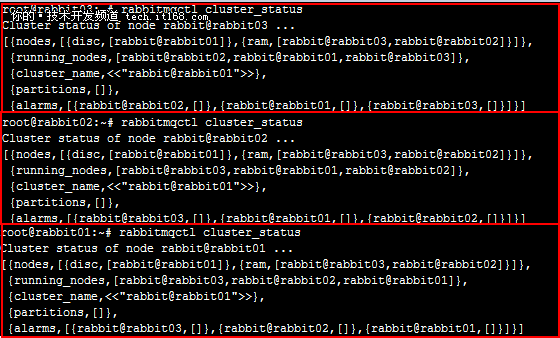
▲各节点集群信息查询(加入集群后)

▲从管理页面看集群信息
注:
如果需要将某个节点从集群中移除,使其变回独立节点,可以使用以下命令:
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
如果需要启停某个节点来进行维护,可以使用以下命令:
rabbitmqctl stop
#FormatImgID_24##FormatImgID_25#rabbitmq-server -detached
当新的节点加入到集群之后,其用户信息也被重置了(之前新增的admin账户不见了),需要重新配置管理员用户,以便访问RabbitMQ管理页面(在任意节点添加用户,会自动同步到各个集群节点):
#添加管理员用户并授权:
rabbit01# rabbitmqctl add_user admin admin
rabbit01# rabbitmqctl set_user_tags admin administrator
rabbit01# rabbitmqctl set_permissions -p / admin '.*' '.*' '.*'

▲重新添加管理员账户
5. 搭建高可用集群环境
通过Policy(策略)设置镜像队列,来实现RabbitMQ的高可用方案。策略主要用来控制和修改集群范围的某个Virtual Host中Exchange和Queue的行为。具体有以下三种策略类型:

▲策略的3种类型
这里,我们采用以下策略(在集群中任意节点启用策略,策略会自动同步到各个集群节点):
#同步以"ha."开头的队列到集群中各节点,应用于所有节点(包括新增节点)
#FormatImgID_27##FormatImgID_28#rabbitmqctl set_policy my-ha-all "^ha\." '{"ha-mode":"all",,"ha-sync-mode":"automatic"}'
rabbitmqctl set_policy my-ha-all "^ha\." '{"ha-mode":"all"}'
6. 验证集群的高可用性
接下来,基于图7的集群环境来验证集群中镜像队列的高可用性。
6.1 修改生产者程序(Send.java),连接到Node1(192.168.1.10)节点,发送消息到镜像队列ha.hello中(修改部分如下图):
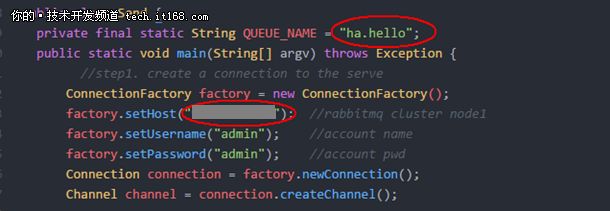
▲从Node1发送消息到镜像队列
6.2 修改消费者程序(Recv.java),连接到Node3(192.168.1.30)节点,接收ha.hello队列中的消息(修改部分如下图):
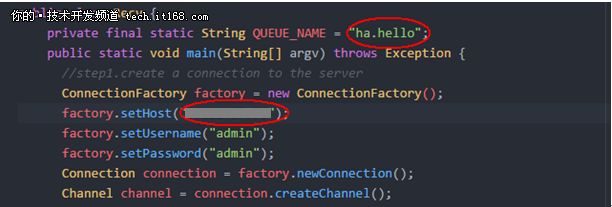
▲从Node3接收镜像队列的消息
6.3 首先执行生产者程序(Send.java)发送100条消息,然后通过命令“rabbitmqctl stop”停止Node1的RabbitMQ服务,再执行消费者程序(Recv.java)接收消息。
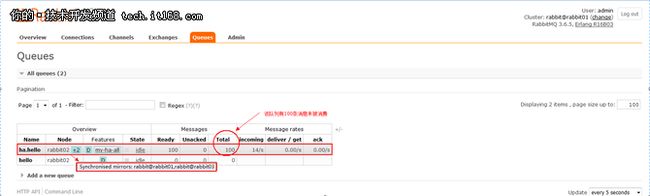
▲发送消息到ha.hello队列

▲停止Node1节点

▲ha.hello队列中消息被成功消费
7. 基于集群环境的客户端开发优化建议
上面介绍的Send.java与Recv.java代码,存在以下两点不足需要改进:
1、生产者、消费者都只连接到了集群中的某个节点。如果该节点故障之后,客户端程序将无法正常发送或接收消息;
2、没有设置自动重连机制,使得客户端程序与Broker之间建立的TCP连接很脆弱。一旦由于网络异常导致Connection关闭,客户端程序将程序将无法正常接收消息。
基于上述两个实际客户端开发的痛点,我们需要对程序进行集群全节点连接、自动重连的改进。改进后的Recv.java完整代码如下图19~图21所示:
首先让Recv类实现Runnable、Consumer接口,让Recv实例以Consomer线程的方式运行。

▲实现Runnable及Consumer接口
然后在重写run方法中进行自动重连、连接到所有节点的设置

▲实现run方法,在其中设置
然后重写handleDelivery方法,来设置接收到消息后的处理逻辑;并空实现Consumer接口中其他handleXXX的方法;最后通过main方法以线程的方式创建Consumer的实例来接收消息。

▲重写handleDelivery方法实现消息处理
四、总结
本文通过介绍RabbitMQ的基本概念、主要作用和使用场景,回答了什么是RabbitMQ,以及用RabbitMQ能做什么的问题;然后通过搭建一个RabbitMQ单节点环境、用程序演示消息发送接收过程,回答了怎么使用RabbitMQ的问题;再通过搭建高可用集群环境,回答了如何实现RabbitMQ服务高可用性的问题。并分享了自己在集群环境的客户端开发实践中的一些经验。
对于上述的RabbitMQ高可用集群方案,还存在一定的缺点:虽然在客户端程序提供完整的集群节点信息能保证连接的可靠性,但是这种向客户端程序暴露集群(所有)节点的做法不太合适。
当集群环境发生变化(比如增加、删除节点)时,客户端程序还得做相应的配置变更,增加了集群环境和客户端程序耦合性。RabbitMQ官方建议通过在RabbitMQ集群环境之上增加一个抽象层,让客户端程序连接到该抽象层,实现集群环境和客户端程序的解耦。这个抽象层,可以是一个包含一段TTL配置的动态DNS服务,也可以是一个TCP LB(基于TCP协议的Load Balancer,如HAProxy)。