爬取京东商品并分析
一、前言
上文,我们爬取了京东商城糖果的两千多条商品信息。今天,我们就来对它进行分析吧!(●’◡’●)
要点:
工具:jupyter notebook
用到的库:pandas、matplotlib、jieba
下面我们开始吧!
二、数据处理
1.数据清洗
1.首先从csv文件中导入数据
import pandas as pd
#读取数据
dataframe = pd.read_csv('./JongDong.csv')
print(dataframe.shape)
查看下有多少条数据:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g9khNi2g-1584540171764)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20200318161229715.png)]](http://img.e-com-net.com/image/info8/9de933eed44540ada29bdf0ce34d7a1b.png)
预览下前几行的数据:
dataframe.head()

2.处理缺失数据
data = dataframe.dropna(how='any')
data.head()
print(data.shape)
![]()
可以看到,没有缺失的数据
3.保存数据
import pymysql
from sqlalchemy import create_engine
#与mysql服务器建立连接
engine = create_engine('mysql+pymysql://root:2324507@localhost:3306/JingDong?charset=utf8')
con = engine.connect()
data.to_sql(name='candy',con=con,if_exists='append',index=False)
打开数据库看下:

2.预处理
根据上面获取的信息,我们需要先对数据进行一些预处理,将评论数中的汉字’‘万’'转换一下,代码如下:
def dealComment_num(comm_colum):
num = comm_colum.split('+')[0]
if '万' in num:
if '.' in num :
num = num.replace('.','').replace('万','000')
else:
num = num.replace('.','').replace('万','0000')
return num
datadf['comm_num'] = datadf['comment_num'].apply(lambda x: dealComment_num(x))
#转换成int类型
datadf['comm_num'] = datadf.comm_num.astype('int')
#去除标题中的空格
# def clean_title(comm_colum):
# return comm_colum.replace(' ','')
# datadf['goods_title'] = datadf['title'].apply(lambda x: clean_title(x))
data = datadf.drop('comment_num',axis = 1)
data.head(10)
看下处理好的数据:
三、分析
由于京东上面没有销量这一信息,我们姑且将评论数当成是销量。本次项目中取用了price、title、comment_num、shop这几个字段的信息。分别是价格、标题、评论数、店铺名
3.1商品标题词云可视化
使用jieba分词器,将title列中的商品标题进行切割,而后,利用了百度的一个停用词表剔除停用词,然后统计每个词的频率,并绘制词云
预处理:
import jieba
#将所有商品标题转换为list
title = data.title.values.tolist()
#对标题进行分词
title_s = []
for line in title:
title_cut = jieba.lcut(line)
title_s.append(title_cut)
#print(title_s)
#调入停用词表
stopword = [line.strip() for line in open('./baidu_stopwords.txt', 'r', encoding='utf-8').readlines()]
#删除停用词
title_clean = []
for line in title_s:
line_clean = []
for word in line:
if word not in stopword:
line_clean.append(word)
title_clean.append(line_clean)
#进行去重
title_clean_dist = []
for line in title_clean:
line_dist = []
for word in line:
if word not in line_dist:
line_dist.append(word)
title_clean_dist.append(line_dist)
#print(title_clean_dist)
#将title_clean_dist中元素转换成一个list
allwords_clean_dist = []
for line in title_clean_dist:
for word in line:
#print(world)
allwords_clean_dist.append(word)
#将列表allwords_clean_dist 转换为Dataframe对象
df_allwords_clean_dist = pd.DataFrame({'allwords':allwords_clean_dist})
# 对过滤_去重的词语 进行分类汇总
word_count = df_allwords_clean_dist.allwords.value_counts().reset_index()
word_count.columns = ['word', 'count']
绘图:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from imageio import imread
plt.figure(figsize=(20,8))
# 读取图片
pic = imread("./background.png")
w_c = WordCloud(font_path="simhei.ttf",
background_color="white",
mask=pic, max_font_size=100,
margin=1)
wc = w_c.fit_words({
x[0]:x[1] for x in word_count.head(100).values
})
#显示图像
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
#plt.show()
plt.savefig('./jingdong/云图.jpg')
结果如下:

从图中可以得出的结论:
1.零食、休闲的词的占比比较大
2.关于糖果的类型,可以清除的看到,巧克力类型的商品最多
3.礼物、喜糖、女友 的词频比较大,说明出售的用于送礼的糖果比较多
3.2价格分布区间
我们再来看下糖果的价格分布区间(说明:大致看了下糖果价格,发现基本属于[0-200]区间内,所以,这里只取200以内的价格进行分析)
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.figure(figsize=(10,8))
price = data[data['price'] < 200]
plt.hist(price['price'], bins=10, color='brown')
plt.xlabel('价格')
plt.ylabel('商品数量')
plt.title('价格商品分布')
#plt.show()
plt.savefig('./jingdong/价格分布.jpg')
结果如下:

可以看到:价格基本在0~40的区间之内,占了总采集数据的2/3左右
3.3销量分布情况
如上说明,由于没有爬取到销量信息,所以将评论数当成销量
sale_num = data[data['comm_num'] > 100]
plt.figure(figsize=(10,8))
#print(len(sale_num)/len(data)) #查看下大致的区间分布
plt.hist(sale_num['comm_num'], bins=20, color='brown')
plt.xlabel('销量')
plt.ylabel('数量')
plt.title('销量情况')
#plt.show()
plt.savefig('./jingdong/销量情况.jpg')
结果如下:
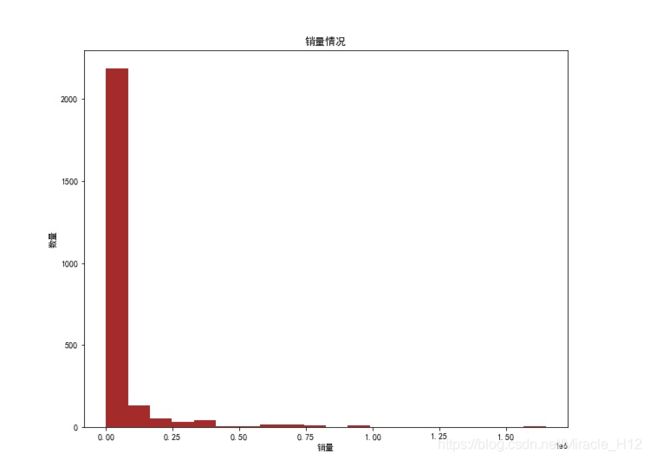
可以看到,销量基本是在10万以上。
这让我有点好奇,我们来看下销量最高的糖果是哪些吧
3.4销量前10的糖果
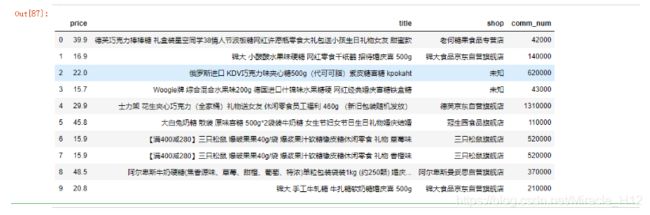
在分析过程中,我发现数据有些诡异,出现了下面的情况

于是,我去excel里瞅瞅了。
图1:46.8元的巧克力
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l9jBhvEy-1584540171789)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20200318165556767.png)]](http://img.e-com-net.com/image/info8/9d3d4b2b94cc4266b80b1594655e7e8a.png)
图1:96元的巧克力
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SmMIKaZH-1584540171793)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20200318165522175.png)]](http://img.e-com-net.com/image/info8/ea150974e15e44439954cf5390145194.jpg)
发现同一款商品的不同规格的销售量是记在一起的。本来呢,这里应该对其处理一下,但图已经画好了,我就懒得改代码了,偷个小懒。嘿嘿(●ˇ∀ˇ●)
为了图更好看点,将标题进行了截取,只取前面那个小标题。代码如下:
#取出每个商品标题的简略信息
def get_title(item):
title = item.split(' ')[0]
return title
data['small_title'] = data['title'].apply(lambda x: get_title(x))
data1 = data.drop('title',axis = 1)
top10_candy = data1.sort_values('comm_num',ascending=False)
top10_candy.head(10)
title = top10_candy['small_title'][:10]
sale_num = top10_candy['comm_num'][:10]
plt.figure(figsize=(10,8),dpi = 80)
plt.bar(range(10),sale_num,width=0.6,color='red')
plt.xticks(range(10),title,rotation=45)
#plt.ylim((9,9.7)) #设置y轴坐标
plt.ylabel('数量')
plt.xlabel('标题')
plt.title('销量前10的糖果')
for x,y in enumerate(list(sale_num)):
plt.text(x,float(y)+0.01,y,ha='center')
plt.savefig('./jingdong/销量前10的糖果.jpg')
结果如下:
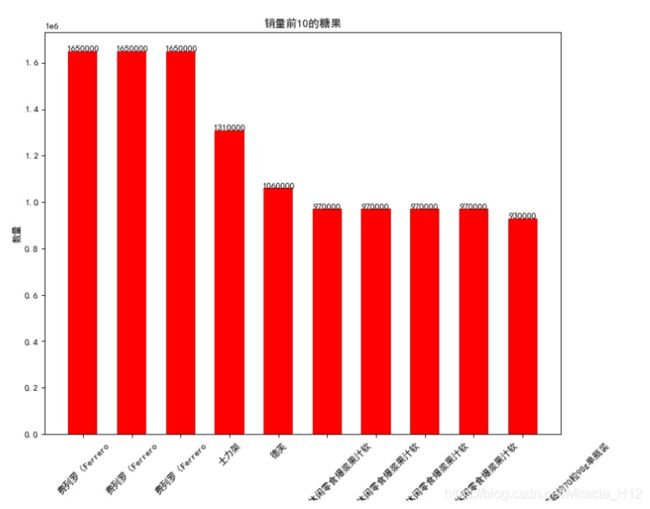
可以看到,费罗列 牌子的巧克力以165万的销量笑傲群雄。我最喜欢的大白兔竟然没有上榜┭┮﹏┭┮
3.5销量前10的店铺
分析完销量前10的商品后,我们再来看下销量前10的店铺:
代码如下:
top_shop = data.groupby('shop')['comm_num'].sum().sort_values(ascending=False)[:10]
top_shop.head(10)
plt.figure(figsize=(10,8),dpi = 80)
top_shop.plot(kind = 'bar',color='brown',width= 0.6)
plt.ylabel('数量')
plt.xlabel('店铺名')
plt.title('销量前10的店铺')
plt.xticks(rotation=45)
for x,y in enumerate(list(top_shop)):
plt.text(x,float(y)+0.1,y,ha='center')
#plt.show()
plt.savefig('./jingdong/销量前10店铺.jpg')
结果

可以看到:箭牌京东自营旗舰店占据第一名,达2000多万。其他前10的店铺中也基本是京东的自营店
3.6商品价格和销量关系
这个,我们采用散点图的方式,看看价格和销量的分布关系
plt.figure(figsize=(10,8))
plt.scatter(data['price'],data['comm_num'], color='blue')
plt.xlabel('价格')
plt.ylabel('销量')
plt.title('价格、销量的散点分布')
#plt.show()
plt.savefig('./jingdong/价格、销量的散点分布.jpg')
结果如下:

可以看到:价格在0-50之间的销量是最高的,而随着价格的增加,销量越来越少。嗯?还有600多的糖果?

3.7价格和成交总额的关系
由上图观察,我们发现价格和销量之间似乎有个负相关的关系,那么,我们就来建立个模型分析分析叭!
import seaborn as sns
data['sum_sale'] = data['price']*data['comm_num']
print(data['price'].corr(data['sum_sale'])) #查看相关系数
sns.regplot(x='price', y='sum_sale', data=data, color='red') #拟和程度不高,模型价值不大
plt.savefig('./jingdong/价格和成交总额的关系.jpg')
结果如下:

但实际上,这个图的价值不大,我们看下两者的相关系数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tbiOQ8EM-1584540171804)![(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20200318172119859.png)]](http://img.e-com-net.com/image/info8/89de75b9181941bf90ef2b3f9de9c462.png)
说明我这个模型建的很失败!呜呜,看来直觉都是骗人的。

这里就不对上面那张图分析啦。
结语
磕磕拌拌,总算完成了这次分析。作为一枚数据分析小菜鸟,我的python之路,任重而道远。