(数据库存储)S7 Hive数据仓库 安装 操作
数据仓库概念
起源于Facebook,使用SQL语言。
数据仓库
面向主题的,集成的,随时间变化的,信息相对稳定的数据集合。
-
面向主题:
操作性数据库的数据注释是面向事务处理任务。主题指用户使用数据仓库进行决策时关心的重点方面。如商品的推荐。 -
随时间变化
数据仓库是不同时间的数据集合,数据仓库中的数据保存时限要能满足进行决策分析的需要(如5到10年),而数据仓库中的数据都要标明数据的历史时期。 -
数据仓库数据相对稳定
一般不可更新,进入仓库后长期保留,进行大量查询操作,很少修改和删除操作。
OLTP和OLAP
联机事务管理OLTP联机分析处理OLAP
- OLTP是传统关系型数据库的主要应用,针对基本的日常事务处理,如银行转账
- OLAP是数据仓库的主要应用,支持复杂分析操作,侧重决策支持,并且提供直观易懂的查询结果,如商品推荐

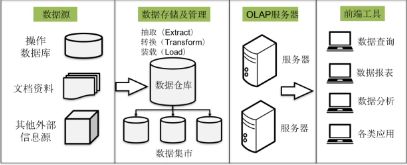
数据仓库的结构
-
数据源:
是数据仓库的基础,包含内部信息和外部信息 * 内部信息:业务数据和自动化系统中包含的各类文档。 * 外部信息:各类法律法规,市场信息,竞争对手信息.. -
数据存储和管理
是数据仓库的核心,针对系统现有数据进行抽取、清理并有效集成,并按主题进行组织。数据集市,小型部门的数据仓库 -
OLAP服务器
对分析的数据按照多维数据模型进行重组,支持用户随时进行多角度、多次层次的分析。 -
前段工具
分析工具、报表工具、查询工具、数据挖掘工具以及各基于数据仓库或者数据集市开发的应用
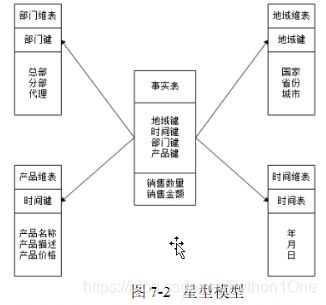
数据仓库的数据模型
星型模型
- 以一组事实表和一组维度表组合而成
雪花模型
- 是对星型模型的扩展
- 效率比较低使用不多

Hive简介
什么是Hive
-
Hive是建立在Hadoop文件系统上的数据仓库,它提供一系列工具,对存储在HDFS中的数据今夕数据提取、转换和加载(ETL),是一种可以存储、查询和分析储存在Hadoop中的大规模数据的工具
-
定义了简单类SQL语言HQL,可以将结构化数据文件映射为一张数据表,可以使用SQL语言也可使用MapReduce开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂分析工作。
-
Hive除了有类似数据库的查询语言,再无相似之处。
Hive与传统数据库的对比
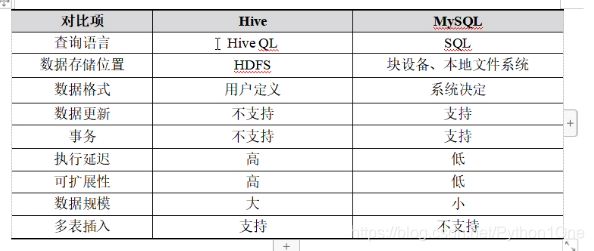
Hive面向分析数据,MySQL注重处理,注重业务
Hive系统架构
包含四个部分:用户接口,跨语言服务,底层的驱动引擎和元数据存储系统
-
用户接口:CLI是shell终端命令、JDBC/ODBC(Hive的java实现)和webUI(通过浏览器访问Hive)。其中CLI用的最多
-
跨语言服务(Thrift Server):Thrift 是Facebook开发的框架,用于不同的语言的调用Hive的接口
-
底层的驱动引擎:包含编译器、优化器、执行器。用于完成HQL查询语句从词法分析、语法分析、编译、优化及查询计划的生成,生成的查询计划存在HDFS中随后MapReduce调用执行
-
元数据存储系统(metastore):metastore默认存在自带的Derby数据库中,但是不适合多用户操作,并且数据存储目录不固定,不方便管理。通常将原数据存在MySQL数据库中。
* Hive元数据存储系统中通常存储表名、列、分区及其相关属性
Hive工作原理
- ui向Driver发送查询操作
- Driver借助编译器解析查询,期望获取查询计划
- 编译器将元数据请求发送费MetaStore
- Metastore将元数据以响应的方式发送给编译器
- 编译器坚持需求,并将计划重新发送给Driver
- Driver将执行计划,发送给执行引擎,执行任务
- 执行引擎从DataNode中获取结果,并将结果发送给UI和Driver
Hive数据模型
数据模型存在HDFS中。有数据库,表,分区表和捅表
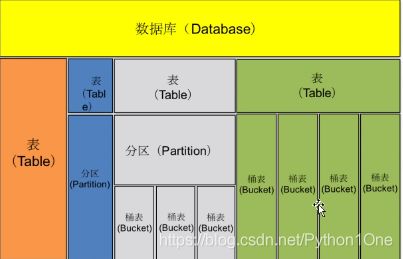
一个表就是一个文件夹,一个桶表是一个子文件,分区是表文件夹里的子文件夹
- 数据库:类似关系型数据库中的数据库
- 表:放在HDFS中,内部表存在Hive数据仓库中;外部表,可以存在Hive数据仓库外的分布式文件系统中。hive数据仓库就是HDFS的一个目录,这个目录是hive的默认路径,可以再Hive配置文件中配置,最终也会存在元数据库中
- 分区:根据“分区列”值进行粗略划分,如在Hive文件夹下有子文件夹分别存储。目的为了快速查询
分区列不是某个字段,而是独立的列,根据这个列查询表中的数据文件 - 桶表:将“大表”分为“小表”,为了更高的查询效率,桶表是Hi侧数据模型的最小单元,数据加载到桶表是,对字段值进行哈希取值,然后除以桶的个数,保证每个桶表都有数据。每个桶表就是表或者分区的一个文件。
Hive安装
安装模式
- 嵌入模式:使用内嵌的Derby数据库存储元数据,配置简单,但是只能连接一个客户端,只能用来测试。
- 本地模式:采用外部数据库存储运输局,不会开启Metastore服务,因为本地模式使用的和Hive同一个进程中的Me他store服务
- 远程模式:与本地模式相仿,但是需要单独开启Metastore服务,然后在每个客户端都在配置文件汇总连接该服务,远程模式下Metastore服务和hive 服务运行在不同的进程中
安装
嵌入式安装
- 下载安装包
- 解压后在hive目录下 执行bin/hive 启动hive
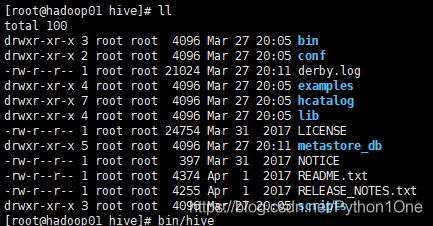
- 进入到hive后使用类Sql语句,show databases;查看数据库只有默认的default数据库。

- 当退出hive是当前目录产生derby.log文件,记录了用户操作Hive的日志文件,当重新打开hive会产生新的derby文件。
- 换路径启动时产生新的derby文件无法共享文件。
本地模式和远程安装
mysql的安装配置
- 安装mysql
yum install mysql mysql-server mysql devel
- 启动MySQL
/etc/init.d/mysqld start
- 连接mysql
[root@hadoop01 hive]# mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.1.73 Source distribution
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
- 修改登录密码
mysql> use mysql
mysql> UPDATE user SET Password=PASSWORD('密码') WHERE user='root';
- 允许远程登录
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '登录密码' WITH GRANT OPTION;
- 强制写入
FLUSH PRIVILEGES;
- 设置mysql服务开机启动
[root@hadoop01 ~]# service mysqld status //启动mysqld服务
[root@hadoop01 ~]# chkconfig mysqld on // 开机启动
[root@hadoop01 ~]# chkconfig mysqld --list //看一下
hive的配
- 进入hive的conf文件夹
- 将hive-env.sh.template复制一份并重命名
[root@hadoop01 conf]# cp hive-env.sh.template hive-env.sh
- 修改hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/opt/hadoop # Hadoop的安装路径。
这个文件是指定Hadoop的路径
- 创建hive-site.xml并 添加一下代码
javax.jdo.option.ConnectionUserName</name># 用户名
root</value>
</property>
javax.jdo.option.ConnectionPassword</name># 登录密码
1123</value>
</property>
javax.jdo.option.ConnectionURL</name>#地址,并使用hive数据库?没有创建=true
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
javax.jdo.option.ConnectionDriverName</name>#驱动连接
com.mysql.jdbc.Driver</value>
</property>
</configuration>
* 配置完成后hive会将默认的Derby数据库变为mysql数据库
- 将mysql连接驱动jar包上传到hive的lib下
[root@hadoop01 mysql-connector-java-5.1.48]# cp mysql-connector-java-5.1.48.jar /opt/hive/lib/
# 文件已上传、先tar xf mysql-connector-java-5.1.48.tar.gz -C ./
# 后里面有mysql-connector-java-5.1.48.jar
- 本地模式安装完成启动 和之前一样。。。
- 远程模式将hive-site.xml的localhost改为由mysql的服务节点ip即可
- 启动hive后创建表,退出后查看mysql的hive数据库有很多表
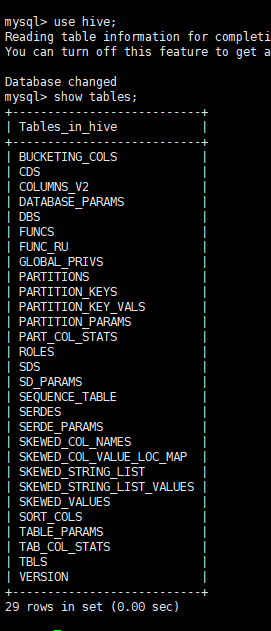
错误解决方法
点击跳转
Hive的管理
CLI方式
-
启动Hive
安装目录启动bin/hive -
退出hive
exit;或者quit; -
查看数据库
show databases; -
使用数据库查看表
show tables
注意:hive默认使用defulat数据库 -
查看自带函数
show functions;
远程服务
当我们使用JDBC或者ODBC进行hive操作时,CLI不能进行多节点同时访问,还会造成服务器阻塞。一般Hive部署的服务器用户是无法访问到的,所以使用远程服务进行hive操作。
- 将hadoop01的hive分发下去。
[root@hadoop01 opt]# scp -r ./hive hadoop04:`pwd`
- 在hadoop01启动hive安装包下的Hiveserver2服务
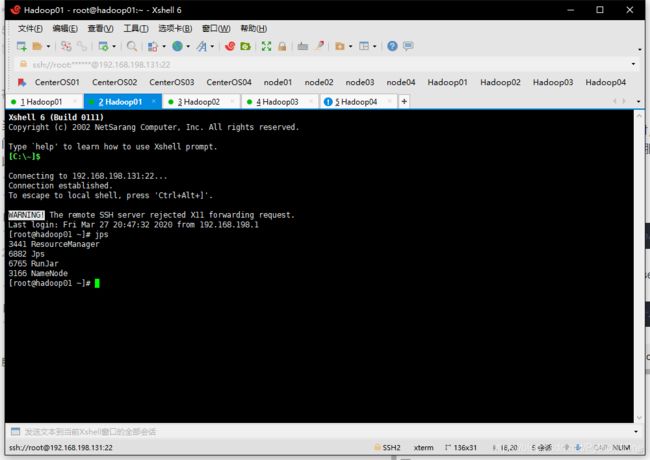
[root@hadoop01 hive]# bin/hiveserver2
启动后shell窗口没反应不动他,再开一个hadoo01的链接jps一下出现RunJar说明hive服务启动成功
- 在新开的hadoop窗口进行连接
[root@hadoop01 ~]# cd /opt/hive/
[root@hadoop01 hive]# bin/beeline
Beeline version 1.2.2 by Apache Hive
beeline>
- 输入远程连接协议
beeline> !connect jdbc:hive2://hadoop01:10000 # hive2的默认端口号为10000
Connecting to jdbc:hive2://hadoop01:10000
Enter username for jdbc:hive2://hadoop01:10000: root #用户名
Enter password for jdbc:hive2://hadoop01:10000: **** # 密码
- 查看数据库
代码和mysql差不多了
0: jdbc:hive2://hadoop01:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
| text01 |
+----------------+--+
2 rows selected (0.894 seconds)
注意
在启动hive之前必须hadoop集群和mysql已经启动。
Hive内置数据类型
| 数据类型 | 描述 |
|---|---|
| TINYINT | 1字节有符号整数 ,从-128到127 |
| SMALLINT | 2字节有符号整数,从-32768到32767 |
| INT | 4字节有符号整数 |
| BIGINT | 8字节有符号整数 |
| FLOAT | 4字节单精度浮点数 |
| DOUBLE | 8字节双精度浮点数 |
| DOUBLE PRECISION | DOUBLE的别名从Hive2.2.0开始提供 |
| DECIMAL | 任意精度带符号小数 |
| NUMERIC | DECIMAL别名,Hive3.0开始 |
| TIMESTAMP | 精度到纳秒的时间戳 |
| DATE | 以年/月/日形式的日期 |
| INTERVAL | 表示时间间隔 |
| STRING | 字符串 |
| VARCHAR | 可变长度字符串 |
| CHAR | 固定长度字符串 |
| BOLLEAN | 存TRUE和FALSE |
| BINARY | 字节数组 |
| 复杂数据类型 | 复杂数据类型描述 |
|---|---|
| ARRAY | 有序字段,字段类型相同 |
| MAP | 一组无序键值对,键必须是原子类型,值无所谓,同一映射的键数据类型相同,值数据类型相同。(java中的Map集合) |
| STRUCT | 一组命名的字段,字段类型可以不同 |
- 与java中数据类型对应
- TINYINT、SMALLINT、INT以及BIGINT等价与java中的byte、short、int、和long,分别为1、2、4、8、字节
- FLOAT和DOUBLE对应java中的float和double分别是32位和64位浮点数
- STRING用于存储文本,理论上最多可存2GB的字符数
- BINARY用于变长的二进制数据存储
- 复杂数据类型与java的同名数据类型类似。而STRUCT是一种记录类型,它封装了一个命令的字段集合。示例如下
CREATE TABLE complex(
col1 ARRAY<int>,
col2 Map<int,STRING>
col3 STRUCT<a:STRING,b:INT,c:DOUBLE>
)
数据模型操作
数据库操作
- 创建数据库
create database|schema [if not exists] db_name;
* database|schema表示是创建数据库还是创建数据库模式
* [if not exists] 表示库不存在才创建
* 默认情况下数据库在/user/hive/
2. 查看数据库
show databases;
- 查看数据库详情
desc databases|schema db_name;

- 切换数据库
use db_name
- 修改数据库
alter (database|schema) db_name set dbproperties(property_name=property_valus,.....)
* dbproperties一般是键值对
- 删除数据库
drop (database|schema) [if exists] db_name [restrict|cascade]
* cascade强制删除,如果不加当库里有表就会删除失败。但是不建议加。。(删库跑路)
表操作
内部表操作
- 创建表
create [temporary(临时表)][external(外部表)] table [if not exists] tb_name
[(字段名 字段类型 [comment 字段注释信息],....)]
[comment 表注释信息]
[partiitioned(指定分区表) by(字段名 字段类型 [comment 字段注释信息],....)]
[clustered(创建分桶表) by (字段名,字段名,...)]
[sorted(指定排序规则) by (字段名 [ASC(升)|DESC(降序)],..)]
[row format (一行字段的分隔符)]
[stored as (数据表文件的存储格式)]
[location (hdfs_path(文件存放位置)(创建外部表必须有))]
- 复制表
- 复制一张一样的格式,只会复制结构,不复制内容
create [temporary][external] table [if not exists] tb_name like (已存在表的名字)[location (hdfs_path(文件存放位置))];
| 参数名称 | 说明 |
|---|---|
| temporary(临时表) | 加上说明创建临时表,改表仅当前对话可见,会话结束时删除 |
| external | 创建一个外部表,需要制定数据文件的实际路径,忽略这个选项,默认创建内部表,Hive将数据文件移动到数据仓库目录下。外部表,只会记录数据所在路径,不会移动数据 |
| partitioned by | 创建带有分区的表 |
| clustered by | 对每个表或者分区 |
| sorted by | 对列排序,可以提高查询效率 |
| row format | hive默认采用‘\001’作为分隔符 |
| stored as | 指定文件存储格式,默认textfile。 |
| location | 文件在hdfs上的路径 |
基本表创建
- 首先在hadoop01上的hivedata目录下创建一个user.txt文件
1,zcx,20
2,lxm,20
3,sss,55
- 针对hivedata目录准备的结构化文件user.txt先创建一个内部表
create table t_user(id int,name string,age int)
row format delimited fields terminated by ',';

- 看看web的结构
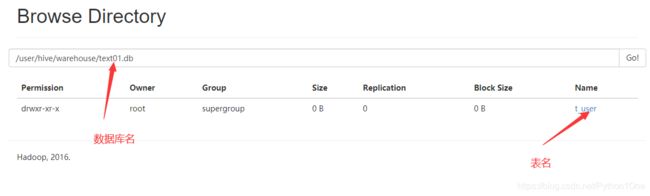
- 将创建的user.txt文件上传到HDFS的/user/hive/warehouse/text01.db/t_user目录下
[root@hadoop01 hivedata]# hadoop fs -put ./user.txt /user/hive/warehouse/text01.db/t_user

- 当将文件放到这个目录意味着表中就有数据了。
我们的hive可以结构化数据自动装换为表
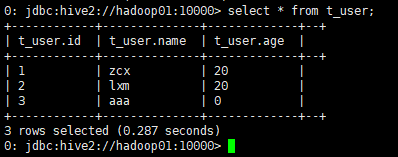
复杂类型数据建建表
- 现有结构化文件student.txt
1,张三,唱歌:非常喜欢-跳舞:喜欢-游泳:一般般
1,Lisa,打游戏:非常喜欢-篮球:不喜欢
- 创建表
create table t_student(id int,name string,hhobby map<string,string>)
row format delimited fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
- 上传student.txt到/user/hive/warehouse/text01.db/t_student
[root@hadoop01 hivedata]# hadoop fs -put ./student.txt /user/hive/warehouse/text01.db/t_student

4. 查看数据库
select * from t_student;

注意
1. 建表语句必须根据结构化文件内容和需求,指定匹配的分隔符;
2. 创建hive内部表必须将数据移动到对应的数据表的HDFS目录下,数据才会和表进行映射,产生响应的数据
外部表操作
- 创建表的时候添加External
- 内部表与结构化数据要产生映射必须将数据移动到目录下,当数据庞大是就非常耗时,这使可以使用外部表来避免。
- 案例
- 现有结构化数据student.txt
95001,李勇,男,20,CS
95002,啊啊,男,20,CS
95003,李送的,男,20,CS
95004,阿勇,男,20,CS
95005,执行勇,男,20,CS
95006,阿斯顿,男,20,CS
95007,张长旭,男,20,CS
95008,刘雪梅,你,20,CS
- 将文件上传到HDFS的/stu路径下,模拟生产环境产生的数据
hadoop fs -mkdir /stu
adoop fs -put ./student.txt /stu
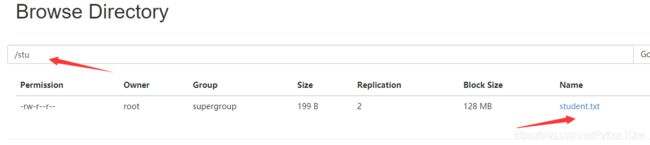
- 创建外部表
create external table student_ext(Sno int,Sname string,Sex string,Sage int,Sdept string)
row format delimited fields terminated by ','
location '/stu';
location表示表的目录在哪
- 查看表中是否有数据
select * from student_ext;
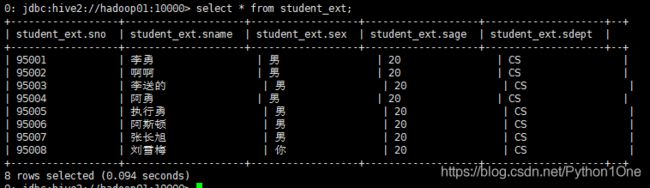
当我们看HDFS的web的student_ext目录下没有student_ext文件夹
提示
1. hive创建内部表是,会将数据移动到数据库指向的路径。
2. 创建外部表时仅记录数据所在路径,不会对数据的位置改变。
3. 在删除表时,内部表的元数据和数据一起都被删除,而外部表只删除元数据,不删除数据
分区表操作
分区表就对应hdfs上的一个文件夹
普通分区
- 创建表
create table t_user_p(id int,name string)
partitioned by (country string)
row format delimited fields terminated by ',';
partitioned by (country string)表明我是分区表,分区名为country
- 导入数据
- 语法
load data [local] inpath 'filepath' [overwrite]
into table tb_name [partition (partcol1=val1, partcol2=val2,)]
| 参数名称 | 说明 |
|---|---|
| load data | 固定语句 |
| filepath | 文件的路径或者文件。 |
| local | 若指定了local关键字,则使用本地路径,否则使用HDFS上的文件路径 |
| overwrite | 覆盖,若指定改属性则,表中数据被覆盖,否则在表中追加 |
load data local inpath '/root/hivedata/user_p.txt' into table t_user_p partition(country='USA');

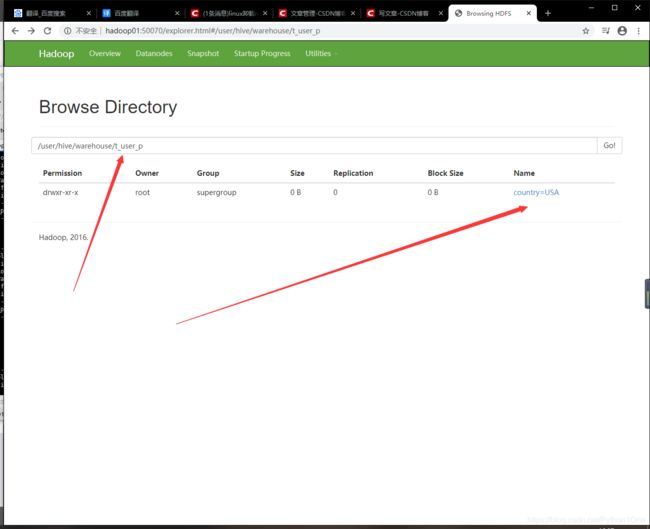
- 新增分区
alter table 表名 add partition (country='China') location '/user/hive/warehouse/t_user_p/country=China';
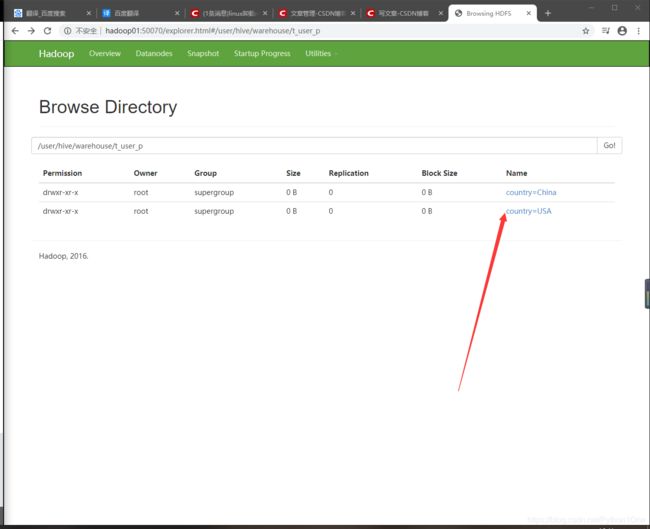
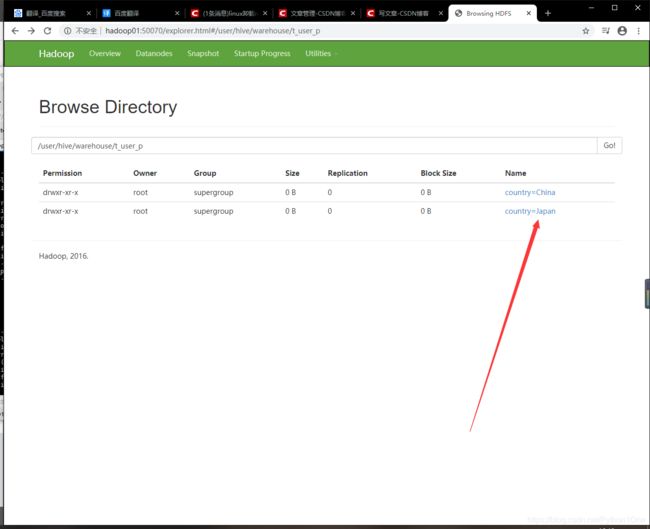
- 修改分区名
alter table 表名 partition(country='原来分区名') rename to partition(country='分区名');
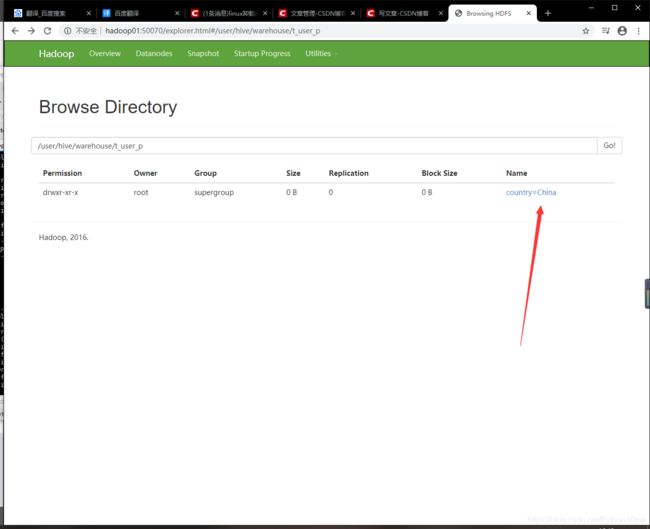
- 删除分区
alter table 表名 drop if exists partiton(country='分区名');
动态分区
- 当数据量大时不可能手动添加字段,所以用到动态分区,
- 开启动态分区
set hive.exec.dynamic.partition=ture;
set hive.exec.dynamic.partition.mode=nonstrict;
- hive默认不支持动态分区,hive.exec.dynamic.parttion默认值为False需开启。hive.exec.dynamic.parttion.mode默认为static设置为nonstrict,表示允许所有的分区字段都可以使用动态分区。
- hive中insert语句是用于动态插入数据,语句:
insert overwrite table 表名
partition (partcol1[=val1],partcol2[=val2]....)
select_statement from from_statement;
例如
- 有一个结构化数据文件dynamic_partition_table.txt
2020-02-15,ip1
2020-02-11,ip2
2020-02-13,ip3
2020-02-14,ip4
2020-03-15,ip5
2020-04-15,ip6
2020-05-15,ip7
- 将文件进行动态分区的数据插入,按照时间插入到目标表d_p_t的相应分区中
- 创建表
create table dynamic_partition_table(day string,ip string)
row format delimited fields terminated by ',';
- 将数据文件加载到数据表
load data local inpath
'/root/hivedata/dynamic_partition_table.txt'
into table dynamic_partition_table;
- 创建目标表
create table d_p_t(ip string)
partitioned by (month string,day string);
- 实现动态插入
insert overwrite table d_p_t partition (month,day)
select ip,substr(day,1,7) as month,day
from dynamic_partition_table;
substr(day,1,7):截取数据,day中的第一个字符到第六个字符截取出来
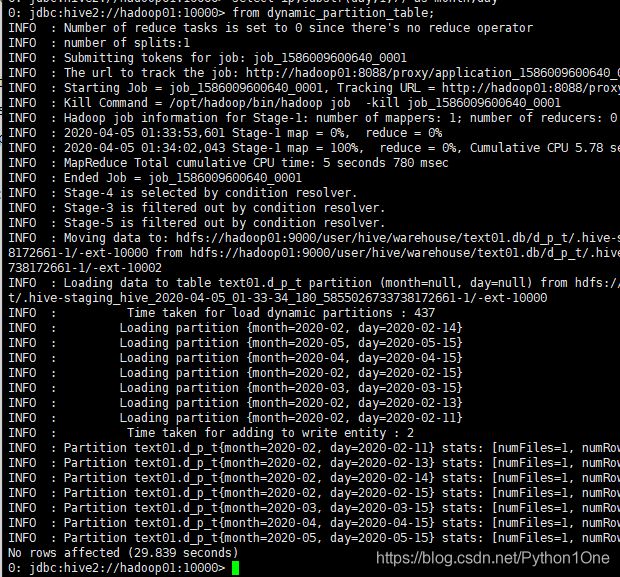
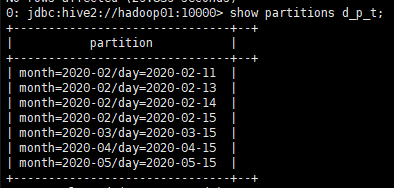
- 查看目标表中的分区数据
show partitions d_p_t;
桶表操作
- 就是在文件层面把数据分开
- 首先开启分桶功能
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
第一行设置开启,
第二行,因为HQL最终会装换称MR程序,所以分桶数与ReduceTask保持一致,从而昌盛相应文件个数
- 创建分桶表
create table stu_buck(Sno int,Sname string,Sex string,Sage int,Sdept string)
clustered by (Sno) into 4 buckets
row format delimited fields terminated by ',';
* clusetred by(Sno):表示分桶关键字,Sno分桶字段,必须为表字段的一个。
* into 4 buckets:按照Sno分桶,分成四个桶。
- 在HDFS的/stu有文件student.txt,将文件复制到/hivedata目录,然后加载数据到桶表中,因为桶表加载数据不能使用load data方式导入(load data实际上是将数据文件进行复制或移动到hive表对应的地址中),所以要创建临时表student,该表与stu_buck表字段必须一致
create table student_tmp(Sno int,Sname string,Sex string,Sage int,Sdept string)
row format delimited fields terminated by ',';
- 加载数据到student临时表
load data local inpath '/root/hivedata/student.txt'
into table student_tmp;

- 将数据导入stu_buck表中
insert overwrite table stu_buck
select * from student_tmp cluster by (Sno);
将查询结果插入到stu_buck中,插过程中实现分桶cluster by (Sno)
执行时会启动MapReduce程序
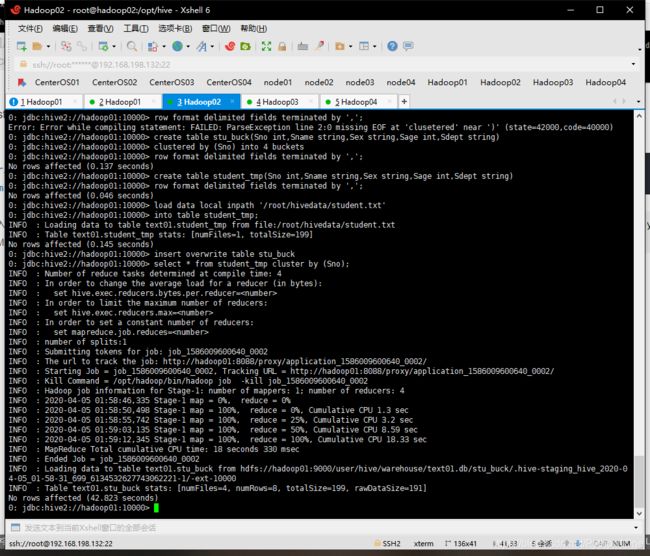
- 查看分桶表数据
select * from stu_buck;

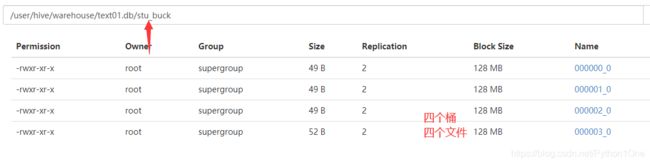
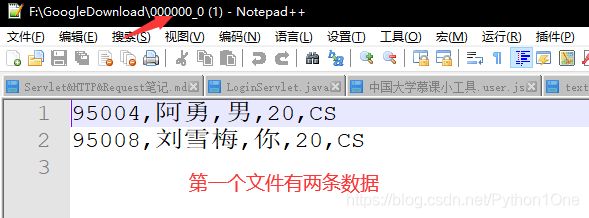
通过系统查看
[root@hadoop01 hivedata]# hadoop fs -cat /user/hive/warehouse/text01.db/stu_buck/000000_0
95004,阿勇,男,20,CS
95008,刘雪梅,你,20,CS
总结
分桶表就是把所映射的结构化数据分得更细致,分桶规则为:hive对目标列值进行哈希运算,得到哈希值再与分桶个数取模的方式决定数据的归并。使用分桶可以提高查询效率,如join操作时,两表有相同字段,如果两表都分桶了,可以减少join操作时的数据量,从而提高查询效率,还能够在处理大规模数据时,选择小部分数据进行抽样运算,减少资源浪费。
数据操作
查询操作
select [all|distinct] select_expr,select_expr,....
from table_reference
join table_other on expr
[where 查询条件]
[group by col_list [hiving condition]]
[cluster by col_list | [distribute by col_list] [sort by | order by col_list]]
[limit number]
| 参数 | 说明 |
|---|---|
| table_reference | 可以是一张表,一个视图,或者一个子查询语句 |
| where | 指定查询条件 |
| distinct | 用于剔除重复数据,默认为all全部显示 |
| group by | 用于将查询结果按照指定字段进行分组 |
| having | 与group by字段连用,将分组后的结构进行过滤 |
| distribute by | 根据指定字段分发到不同的reduce进行处理,分发算法采用哈希散列,与sort by连用 |
| sort by | 在数据进行Reduce前完成排序,不是全局排序,如果设置成mapreduce.job.reduces(分桶数目)>1,则sort by只能保证每个桶中是有序的。 |
| cluster by | 分桶查询语句,根据指定的字段进行分桶,分桶数取决于设置reduce的格式,分桶后,每个桶中的数据都进行排序。如果distribute by和sort by排序的字段是同一个时,distribute by+sort by=cluster by |
| order by | 对查询的数据进行全局排序,因此输出文件只有一个且只存在一个Reduce,数据量会很大,计算会很慢。 |
案例–
准备两个数据
- emp.txt
7369 SMITH CLERK 7902 1980-12-17 800.0 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JOESON MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAHER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-6 2450.00 10
- dept.txt
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
创建表
- emp表
create table emp(empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int)
row format delimited fields terminated by ' ';
- dept表
create table dept(deptno int, dname string, loc int)
row format delimited fields terminated by ' ';
查询
基本查询
- 全表查询
select * from emp;
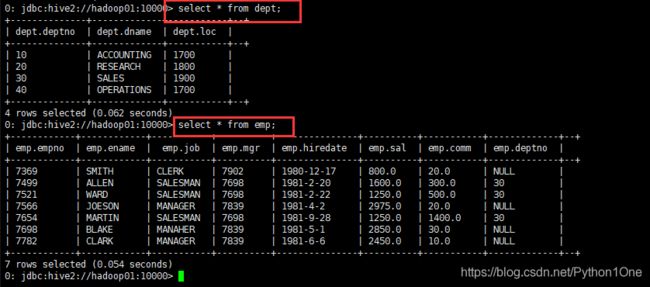
- 指定字段查询
select deptno,dname from dept;

- 查询员工表总人数
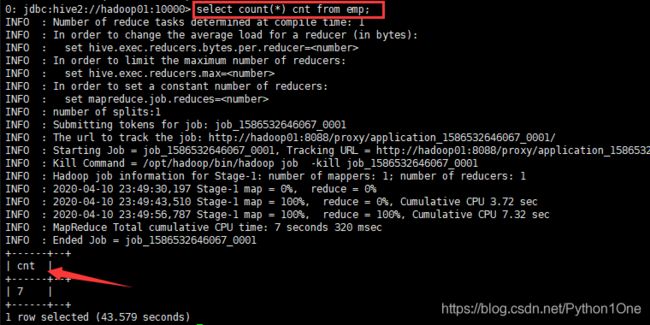
select count(*) cnt from emp;
count()累计函数
cnt是别名
启动了MapReduce任务
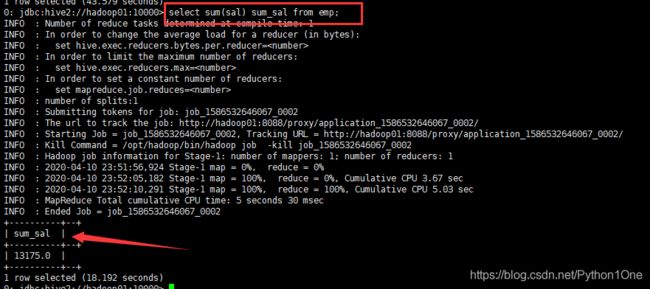
- 查询员工表总工资
select sum(sal) sum_sal from emp;

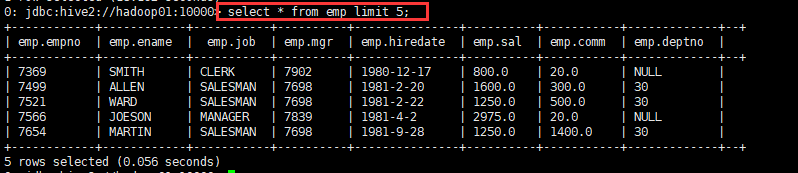
- 查询5条员工表信息
select * from emp limit 5;
Where条件查询
- 薪水等于800的所有员工
select * from emp where sal =800;

- 工资在500 和1500之间的员工
select * from emp where sal between 500 and 1500;

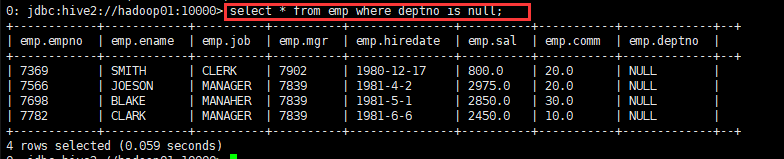
- deptno为空的所有员工
select * from emp where deptno is null;
- 查询工资是1250和1600的员工
select * from emp where sal in (1250,1600);

Like和Rlike
Rlike子句是hive的扩展,可以通过java的正则表达式来匹配数据
- 查询以2开头的薪水的员工
select * from emp where sal like '2%';

- 查询第二个数是2的薪水的员工信息
在这里插入代码片