对猫眼T100进行简单数据分析
对猫眼T100进行简单数据分析
- 前言
- 可视化分析
- TOP100最多的国家或地区
- TOP10电影
- 影产量年份趋势
- 演员出演TOP100电影情况
- 结语
前言
上一次,我们爬取了猫眼电影的Top100数据,并将它存放在了csv文件中。今天,我们就将数据取出,来进行个简单的分析吧!
可视化分析
TOP100最多的国家或地区
首先,我们看一下拥有Top100最多的国家或者地区:
代码如下:
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname='C:/Windows/Fonts/msyh.ttc',size = 14)
#加载数据
index = ['index','name','actor','releasetime','country','score']
data = pd.read_csv('./MoviesTop100.csv',header=None,names= index) #从第0行开始读取,索引为 index
#print(data.shape)
#查看电影分布情况
country_count = data.groupby('country')['country'].count().sort_values(ascending = False)
plt.figure(figsize=(10,8),dpi=80)
country_count.plot(kind='bar',color='blue',width = 0.8)
plt.xticks(rotation=0)
plt.ylabel('数量(部)',fontproperties=my_font)
plt.xlabel('国家/地区',fontproperties=my_font)
plt.title('国家/地区电影数量排名',fontproperties=my_font)
for x,y in enumerate(list(country_count.values)): #将其组合成一个索引,例如[(0,44),(1,17)]
plt.text(x,y+0.5,y,ha='center')
plt.show()
结果如下图:
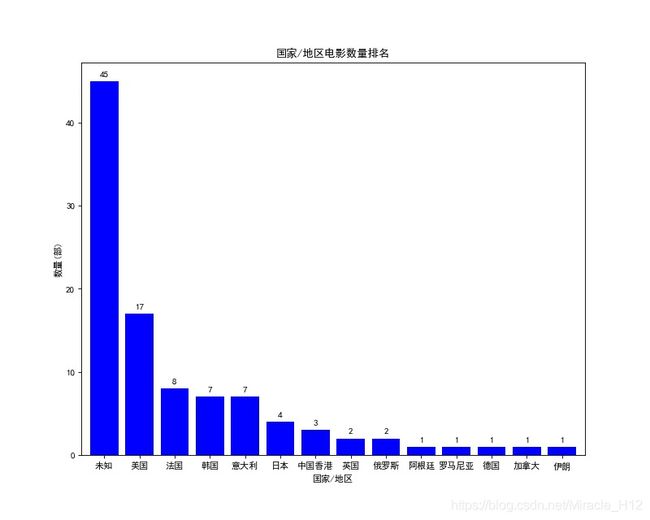
可以看到除了网站中没有显示国家/地区的电影外,美国以17部占了绝大优势,其次是韩国,而中国内地一部电影也没有上榜。。。
TOP10电影
接下来,我们看一下评分最高的10部电影是哪几部
代码如下:
top10_movies = data.sort_values('score',ascending=False)
name = top10_movies['name'][:10]
score = top10_movies['score'][:10]
plt.figure(figsize=(10,8),dpi = 80)
plt.bar(range(10),score,width=0.6,color='red')
plt.xticks(range(10),name,rotation=45)
plt.ylim((9,9.7)) #设置y轴坐标
plt.ylabel('评分')
plt.xlabel('电影名称')
plt.title('TOP10电影名称')
for x,y in enumerate(list(score)):
plt.text(x,float(y)+0.01,y,ha='center')
#plt.show()
plt.savefig('./绘图/Top10电影名称.jpg')
结果如下:
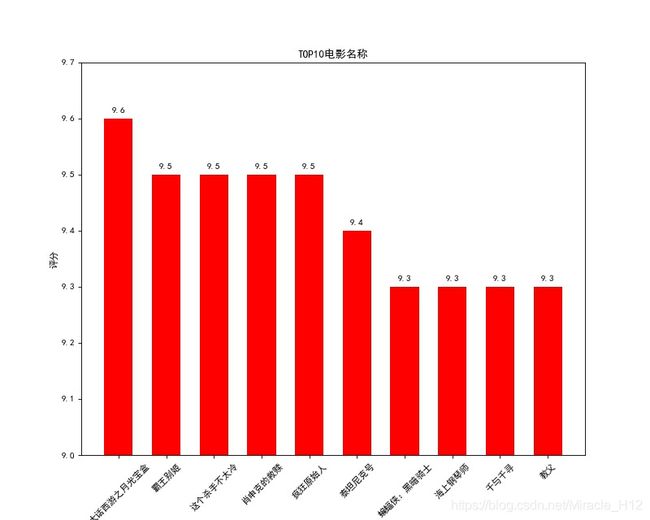
让我有点意外的是,大话西游之月光宝盒竟然排到了第一名,高达9.6的评分,星爷的电影还是十分经典的。嗯,幸好其中大部分电影还是都看过的
影产量年份趋势
接下来,我们站在时间的维度上去看下,哪一年盛产了最多的Top100电影
代码如下:
year_data = pd.Series() #创建一个Series对象,用于后面赋值
for i,item in data.iterrows(): #遍历每一行
year = item['releasetime'].split('/')[0]
dict_obj = {} #创建一个空字典
dict_obj['time'] = year
year_df = pd.Series(dict_obj)
year_data = year_data.append(year_df)
year_moviesnum = year_data.groupby('time').count()
plt.figure(figsize=(10,8),dpi = 80)
year_moviesnum.plot(kind = 'line',color='red',marker='o')
plt.ylabel('数量(部)')
plt.xlabel('年份')
plt.title('电影产量趋势')
#plt.show()
plt.savefig('./绘图/电影产量趋势.jpg')
结果如下:
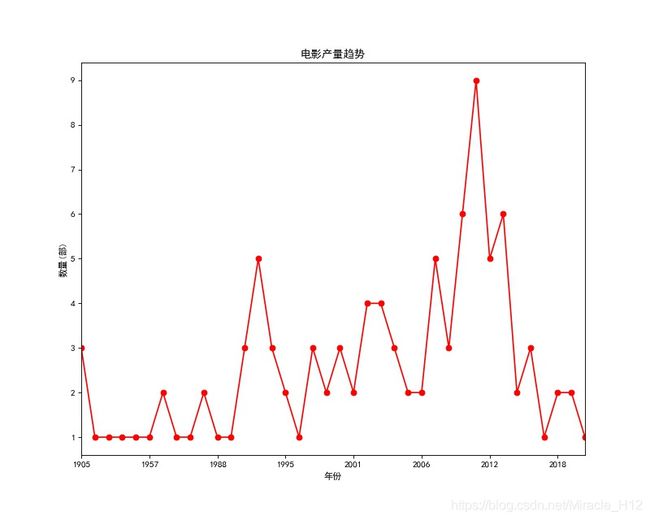
可以看出,在11年的时候,产出了9部Top100。11年,貌似那时候还是使用的DVD吧,那时候的网络也没有现在这么发达,也想不起有哪些电影是那年上映的。
演员出演TOP100电影情况
最后,我们再来看一下,哪些演员出演的Top100电影最多
代码如下:
ctor_data = pd.Series() #创建一个Series对象,用于后面赋值
actor_dict = {}
for i,item in data.iterrows():
actor = item['actor'].split(',')
for name_item in actor:
actor_dict['actor_name'] = name_item
actor_df= pd.Series(actor_dict) #转换为Series类型
actor_data = actor_data.append(actor_df)
actor_moviesnum = actor_data.groupby('actor_name').count().sort_values(ascending=False)[:12]
plt.figure(figsize=(10,8),dpi = 80)
actor_moviesnum.plot(kind = 'bar',color='brown',width= 0.6)
plt.ylabel('数量(部)')
plt.xlabel('姓名')
plt.title('出演Top100电影演员情况')
plt.xticks(rotation=45)
for x,y in enumerate(list(actor_moviesnum)):
plt.text(x,float(y)+0.1,y,ha='center')
#plt.show()
plt.savefig('./绘图/演员情况.jpg')
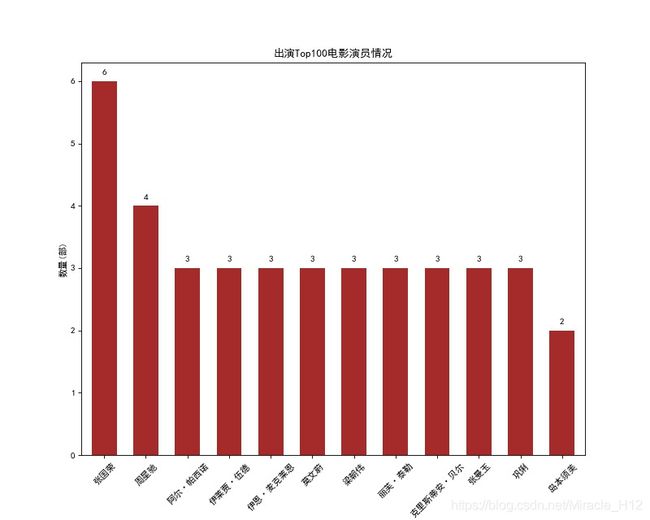
从上图可以看出,张国荣拥有6部Top100电影,其次是星爷。最可惜的是感觉是张国荣,英年早逝。
结语
由于数据量太小,所以做的分析并不是很全面。