(Hadoop)Hadoop高可用
hadoop2.0的改进与提升
| 组件 | Hadoop1.0局限和不足 | Hadoop2.0的改进 |
|---|---|---|
| HDFS | NameNode存在单点故障风险 | HDFS引入了高可用机制 |
| MapReduce | JobTracker存在单点故障风险,且内存扩展受限 | 引入了一个资源管理调度框架YARN |
Yarn资源管理框架
Yarn体系结构
YARN(Yet Another Resource Negotiator,另一种资源协调者)是一个通用的资源管理系统和调度平台,它的基本设计思想是将MRv1(Hadoop1.0中MapReduce)中的JobTracker拆分为两个独立任务,这两个任务分别是全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。
体系结构

- ResourceManager
是全局资源管理系统,负责整个YARN集群资源的监控、分配、管理工作 - NodeManager
是每个节点上的资源和任务管理器,一方面,他会定时向ResourceManager虎豹所在节点资源状况;另一方面,他会接受并处理ApplicationMaster容器启动、停止等各种请求 - ApplicationMaster
是一个全局资源管理系统,它负责的是整个Yarn集群资源的监控、分配和管理工作。用户提交的每个应用程序都包含一个ApplicationMaster,它负责协调来自ResourceManager的资源,把获得的资源进一步分配给内部的各个任务,从而实现“二次分配”。
YARN工作流程
YARN的底层工作流程是由核心组件互相协调管理,它们各尽其职,为Hadoop资源调度提供服务,其工作流程图如下所示。
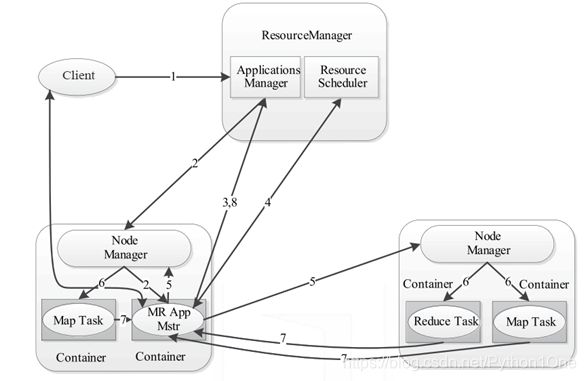
- 用户通过客户端Client向YARN提交应用程序Applicastion
- YARN中的ResourceManager接收到客户端请求后,内部的调度器会为应用程序分配一个容器运行本次程序对应的ApplicationMaster
- ApplicationMaster被创建后,首先向ResourceManager注册信息,用户通过ResourceManager查看应用程序的运行状态
- ApplicationMaster采用轮询方式通过RPC协议向ResourceManager申请资源
- ResourceManager向提出申请资源的ApplicationMaster提供资源
- NodeManager为任务设置好运行环境后,将任务启动命令写到一个脚本中,并通过运行改脚本启动任务
- 个任务通过RPC协议向ApplicationMaster汇报自己的运行状态,在任务运行失败时,ApplicationMaster可以重启新任务
- 应用过运行结束后,ApplicationMaster向ResourceManager注销并关闭自己
HDFS的高可用
HDFS的高可用框架
-
在HDFS分布式文件系统中,NameNode是系统核心节点,存储各类元数据信息,并负责管理文件系统的命名空间和客户端对文件的访问。若NameNode发生故障,会导致整个Hadoop集群不可用,即单点故障问题。为了解决单点故障,Hadoop2.0中HDFS中增加了对高可用的支持。
-
在高可用HDFS中,通常有两台或两台以上机器充当NameNode,无论何时,都要保证至少有一台处于活动(Active)状态,一台处于备用(Standby)状态。Zookeeper为HDFS集群提供自动故障转移的服务,给每个NameNode都分配一个故障恢复控制器(简称ZKFC),用于监控NameNode状态。若NameNode发生故障,Zookeeper通知备用NameNode启动,使其成为活动状态处理客户端请求,从而实现高可用。
-
HDFS的高可用框架

搭建Hadoop高可用集群
部署集群节点

环境准备
搭建普通Hadoop集群(参考第2章完成即可)。需要注意的是,原有虚拟机系统主机名为hadoop01,建议初学者在搭建Hadoop HA集群时重新安装虚拟机,以此来巩固前面所学知识,并将三台虚拟主机名设置为node-01、node-02和node-03。
配置Hadoop高可用集群
- 若使用新主机续配置Zookeeper,zookeeper/conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/export/data/zookeeper/zkdata
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
- 修改hadoop/etc/hadoop下的core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://ns1value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/var/zcx/hadoop/tmpvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>node1:2181,node2:2181,node3:2181value>
property>
<property>
<name>ipc.client.connect.max.retriesname>
<value>20value>
property>
<property>
<name>ipc.client.connect.retry.intervalname>
<value>5000value>
property>
configuration>
- 修改hdfs-site.xml文件,配置NameNode端口和通信方式,并指定元数据存放位置及开启失败自动切换服务,配置隔离机制方法
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/export/data/hadoop/namevalue>
property>
<property>
<name>dfs.namenode.dataname>
<value>file:/export/data/hadoop/datavalue>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.nameservicesname>
<value>ns1value>
property>
<property>
<name>dfs.ha.namenodes.ns1name>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1name>
<value>node1:9000value>
property>
<property>
<name>dfs.namenode.http-address.ns1.nn1name>
<value>node1:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2name>
<value>node2:9000value>
property>
<property>
<name>dfs.namenode.http-address.ns1.nn2name>
<value>node2:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://node1:8485;node2:8485;node3:8485/ns1value>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/export/data/hadoop/journaldatavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.nslname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
configuration>
- 修改mapred-site.xml文件,配置MapReduce计算框架为YRAN方式
<configuration>
<property>
<name>mapreduce.frameworkname>
<value>yarnvalue>
property>
configuration>
- 修改yarn-site.xml文件,开启ResourceManager高可用,指定ResourceManager的端口名称地址,并配置Zookeeper集群地址
<configuration>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>2048value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>2048value>
property>
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>1value>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yrcvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>node1value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>node2value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>node1:2181,node2:2181,node3:2181value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
- 修改slaves,配置集群主机名称
node1
node2
node3
- 修改hadoop-env.sh配置JDK环境变量
export JAVA_HOME=/export/servers/jdk1.8.0_161
将配置好的文件分发给node2和node3。
启动Hadoop高可用集群
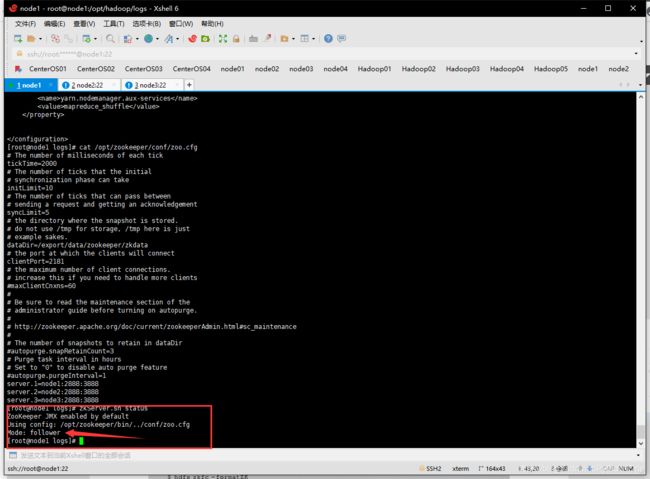
- 启动各个节点的Zookeeper服务
# 需要每台机器都输入
zkServer.sh start
# 启动完毕后查看一下
zkServer.sh status
# 关闭Zookeeper
zkServer.sh stop
- 启动集群各个节点监控NameNode的管理日志的JournalNode
# 需要每台机器都输入
hadoop-daemon.sh start journalnode
- 在node1节点格式化NameNode,并将格式化后的目录复制到node2中
# 格式化
hadoop namenode -format
# 将/export/data/hadoop文件发给node2
scp -r /export/data/hadoop node2:/export/data/
- 在node1节点格式化ZKFC
hdfs zkfc -formatZK
- 在node1上启动HDFS
start-dfs.sh
- 在node1节点启动yarn
start-yarn.sh
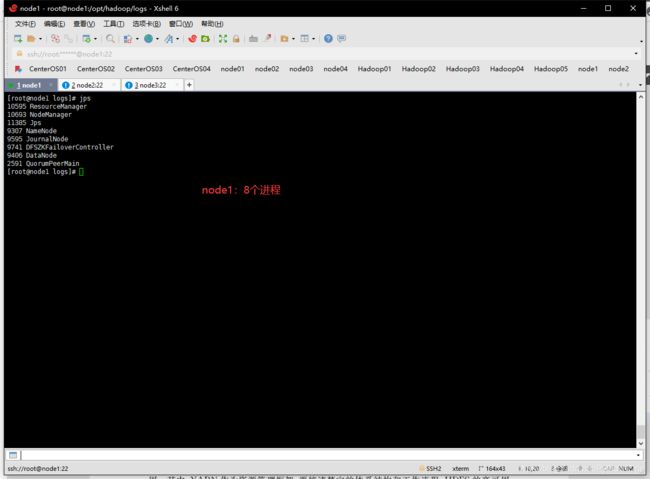


进程缺失,报错寻找方法
- hadoop日志文件在:
*/hadoop/logs下以.log结尾的。哪个没启动找哪个日志文件然后百度。
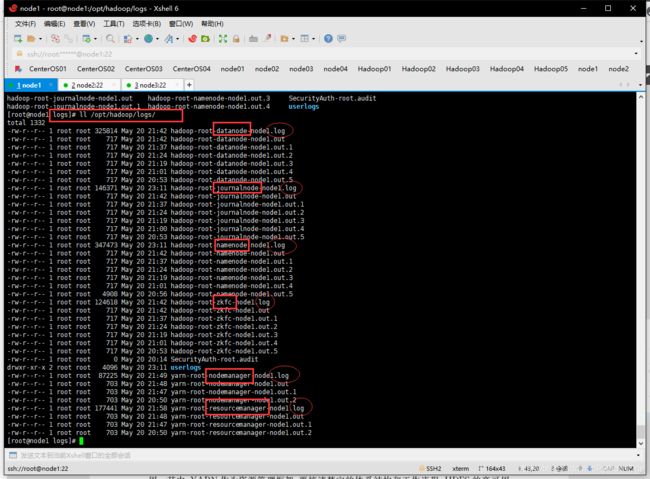
- Zookeeper日志文件在
*/data/zookeeper/zkdata下以.out结尾的。
