MySql第三章,分库分表、MyCat概述及安装登录
MySql第三章,分库分表、MyCat概述及安装登录
先下定论,数据库优化顺序:
1、单库单表;
2、单库单表主从复制;
3、垂直分库;
4、水平分区;
5、水平分表;
一、概述
1、为什么要分库分表
数据库的复制能解决访问问题(主从复制),并不能解决大规模的并发写入问题,由于无法进行分布式部署,而一台服务器的
资源(CPU、磁盘、内存、I0等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。要解决这个问题就要
考虑对数据库进行分库分表了。
2、分库分表的优点
1、解决磁盘系统最大的文件限制
2、减少增量数据写入时的锁对查询的影响,减少长时间查派造成的表锁,影响写入操作等锁竞争的情况,节省排队的时间开
支,增加吞吐量。
3、由于单表数量下降,常见的查询操作由于减少了需要扫描的记录,使得单表单次查询所需的检索行数变少,减少了磁盘
I0,时延变短。
3、什么是分库–垂直切分
分库又叫垂直切分,就是把原本存储于一个库的表拆分存储到多个库上,通常是将表按照功能模块、关系密切程度划分出来,
部署到不同的库上。如果数据库是因为表太多而造成海量数据,并且项目的各项业务逻辑划分清晰、低耦合,那么规则简单朋
了、容易实施的首选就是分库。
[如:将一个电商数据库拆分为:user库、shop库、ums库、home库、promo库、manager库等]
分库的优点是:实现简单,库与库之间界限分明,便于维护。
缺点是不利于频繁跨库操作,单表数据量大的问题解决不了。
3.1、分库思路
基本的思路就是分析业务功能,以及表间的聚合关系,把关系紧密的表放在一起。
分库的粒度指的是在做切分时允许几级的关联表放在一起,这个问题对应用程序实现有着很大的影响。关联打断的越多,
则受影响的join操作越多,应用程序为此做出的妥协就越大,但单表的路由会越简单,与业务的关联性会越小,就越容易使用
统一机制处理。
实际的粒度掌控需要结合“业务紧密程度”和“表的数据量”两个因素综合考虑,一般来说:若划归到一起的表关系紧密,且
数据量并不大,增速也非常缓慢,则适宜放在一起,不需要再进行水平切分:若划归到一起的表的数据量巨大且增速迅猛,则
势必要在分库的基础上再进行分表,这就意味着原单- -的库还可能会被拆分成多个库,这会导致更多的复杂性,-开始最好就
要考虑进去。
4、什么是分表–水平切分
分表又叫水平切分,是按照一定的业务规则或逻辑,将一个表的数据拆分成多份,分别存储在多个表结构一样的表中, 这多
个表可以存在一到多个库中。
[分表和上一章讲的分区很相似,但分区是在同一个库下的拆分。而分表是为了将表拆分到多个不同的数据库而设计的。]
[所以分表一般是和分库同时进行的,对于没有分库的分表是毫无意义的。]
垂直分表:
将本来可以在同一个表的内容,人为划分为多个表。(所谓的本来, 是指按照关系型数据库的第三范式要求,是应该在同一个
表的。)
水平分表:
也被称为数据分片:是把一个表复制成同样表结构的不同表,然后把数据按照一定的规则划分,分别存储到这些表中,从而保
证单表的容量不会太大,提升性能:当然这些结构一样的表,可以放在一个或多个数据库中。
分表的优点是:能解决分库的不足点,但是缺点是实现起来比较复杂,特别是分表规则的划分,程序的编写,以及后期的数据库拆分移植维护。
一般都是先分库再分表,两者结合使用,取长补短,这样能发挥扩展的最大优势,但是缺点是架构很大,很复杂,应用程序的编写也比较复杂。
4.1、分表思路
对于垂直分表:
通常是按照业务功能的使用频次,把主要的、热门的字段放在一起做为主要表:然后把不常用的,按照各自的业务属性进行聚
集,拆分到不同的次要表中:主要表和次要表的关系一般都是一 -对-的。
对于水平分表:
通常是按照具体的业务规则和数据的格式,选择能够把数据进行合理拆分的业务数据做为拆分标准,以此来对数据进行拆分。
常见的一些拆分方式:按业务属性、按时间、按区间、Hash、 按数据的活跃度、按数据量等,不管采用什么方式,都要结合
具体的业务场景进行分析和考量。
二、水平分表
1、面临问题
水平分表的实现面临一系列问题:切分策略、库节点路由、表路由、全局主键生成、
跨节点排序/分组/分页/表关联等操作、多数据源事务处理、数据库扩容等。
2、相关开源方案
1: MySQL Fabric: 官方产品,非代理方式,目前不太稳定,性能也不够好,但很有前景,综合了HA和水平分表的功能,是未来的首选。
2: Atlas: 360开源,代理方式,基于MySQL -Proxy二次开发的,主要支持两个特性:分表和读写分离,但是分表的话只支持单库多表,事实上是不支持分布式分表的
3: Cobar: 阿里开源,代理方式,支持分布式分表,但是不支持单库分多表,不支持读写分离,事务支持也比较麻烦
4、kingshard由小团队用go语言开发,还需要发展,需要不断完善。
5、Vitess是Youtube生产在使用,架构很复杂。不支持MySQL原生协议,使用需要大量改造成本。。
6、MaxScale是mariadb (MySQL原作者维护的一个版本) 研发的中间件。
7、MySQLRoute是MySQL官方Oracle公司发布的中间件。
8: MySQL Proxy: 官方提供,基于MySQL协议接口,主要提供负载平衡,读写分离,failover等, 但性能较差,不支持大数据量的分库分表
9: Amoeba: 支持分数据库实例,每个数据相同的表,不支持事务;类似MySQL Proxy,相对更简单
10: Hibernate Shards: 支持分数据库实例,比较复杂,需事先规划数据规模,对HQL的支持非常有限
11: mybatis shardbatis: 主要通过插件机制来实现分表,但是插件机制控制不到多数据源的连接:离开插件层又失去了对sql进行集中解析和路由的机会
12:Mycat是开源社区在阿里cobar基础上进行二次开发,解决了cobar存在的问题,并且加入了许多新的功能在其中。青出于蓝而胜子蓝。
10: sharding-jdbc
三、MyCat简述
1、功能作用
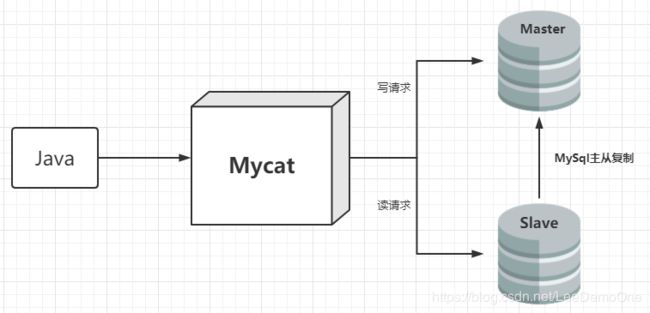
1.1、读写分离
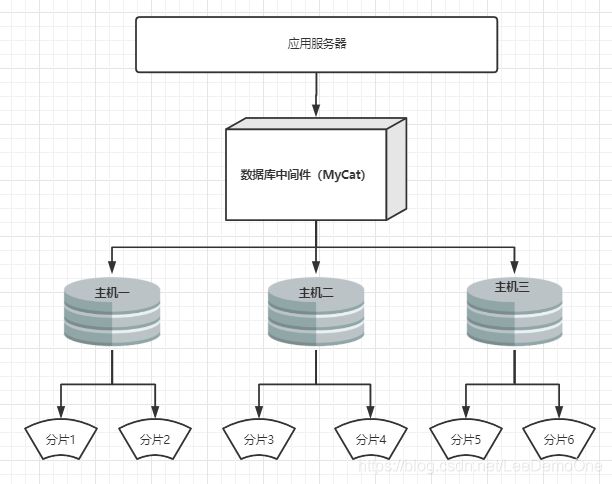
1.2、数据分片
垂直拆分(分库)、 水平拆分(分表)、 垂直+水平拆分(分库分表)
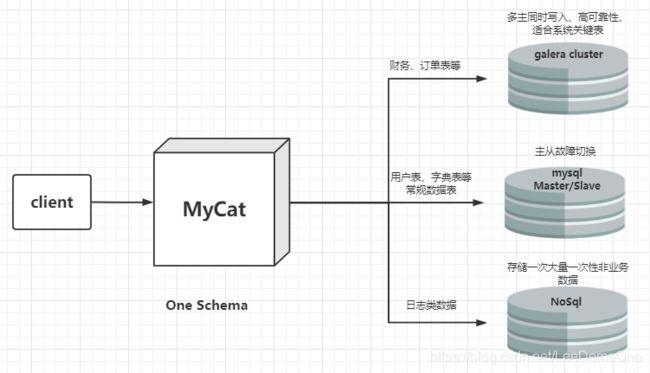
1.3、多数据源整合
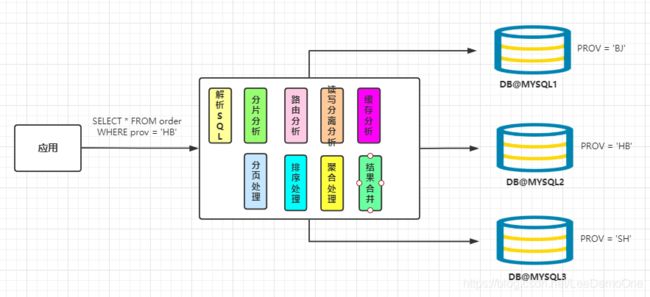
2、原理
Mycat的原理中最重要的-一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分
片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理I最终再
返回给用户。
这种方式把数据库的分布式从代码中解耦出来,程序员察觉不出来后台使用Mycat还是MySQL。
3、安装
3.1、mycat安装
##一般安装包 下载 至 opt 目录下
##解压后,安装的文件 放至 /usr/local
1、下载
wget http://dl.mycat.org.cn/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
2、解压
tar -zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
mv mycat /usr/local
3、主要配置文件
schema.xml 定义逻辑库,表、分片节点等内容【节点】
rule.xml 定义分片规则【规则】
server.xml 定义用户以及系统相关变量,如端口等
3.2、server.xml配置
##mycat对外暴露的逻辑MySQL,name为用户名、password为用户密码、schemas为逻辑数据库名称
<user name="mycat">
<property name="password">mycatproperty>
<property name="schemas">TESTDBproperty>
user>
3.3、schema.xml配置
其中:
schema:mycat对外暴露的逻辑库
dataNode:MySQL对应的数据库
dataHost:MySql对应的主从名称
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
schema>
<dataNode name="dn1" dataHost="host1" database="mycatdb" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostM1" url="192.168.0.111:3306" user="root"
password="admin123">
<readHost host="hostS1" url="192.168.0.107:3306" user="root" password="admin123" />
writeHost>
dataHost>
mycat:schema>
4、启动
##mycat bin目录
##控制台启动------能看到启动日志,方便定位问题
./mycat console
##后台启动
./mycat start
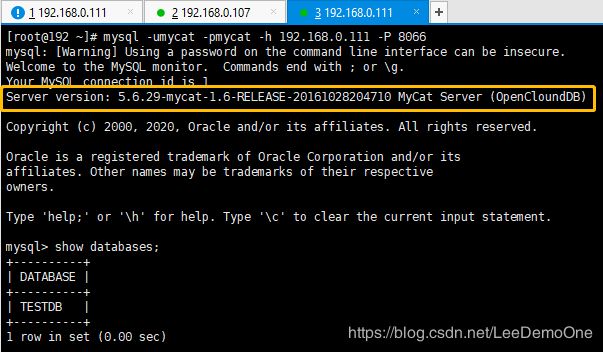
5、登录
##1、登录后台管理窗口---维护
mysql -umycat -pmycat -P 9066 -h 192.168.0.111 ##在server.xml中设置的账号密码
[常用命令:show database; show @@help;]
##2、登录数据窗口
mysql -umycat -pmycat -P 8066 -h 192.168.0.111