如何设计一款暗度陈仓的反爬虫

文末有彩蛋 | 字数:3223字
评论有惊喜 | 阅读时间:9分钟
明修栈道、暗渡陈仓是一组出自《史记·淮阴侯列传》的成语,指将真实的意图隐藏在表面行动的背后,用明显的行动迷惑对方,使敌产生错觉,从而忽略我方的真实意图,达到出奇制胜效果的手段。
市面上常见的反爬虫手段种类繁多,例如文本混淆反爬虫、动态渲染反爬虫、信息校验反爬虫和代码混淆反爬虫等等。其中的文本混淆反爬虫就是明修栈道,暗度陈仓的具体实现,举个例子:

上图中的评论数 3803 是给用户看的,即明修栈道;但如果通过爬虫程序或者自动化工具去取值,只能得到几个不知其意的方框。《Python3 反爬虫原理与绕过实战》一书中提到过,这是因为字体的渲染是在浏览器层面进行的,而不是把字体写入到 HTML 文件中,遂爬虫程序无法获得真实有效的评论数。
这种类似的方法还有很多,例如利用 SVG 映射与 CSS 样式关系实现的文本混淆、利用 CSS 坐标偏移实现的文本混淆,利用 Canvas 绘图实现的图片文本混淆等,这些在《Python3 反爬虫原理与绕过实战》均有详细的原理介绍和用于绕过的反向推导过程,感兴趣的读者可以去翻阅此书。
今天我们我们来学习这种明修栈道,却暗度陈仓的另外一种应用场景,并掌握其反爬虫原理和具体的实现方法。在开始学习之前,请你尝试解密这段字符串:
GBHDHJGOGDGJGOHD==
为什么要解密它呢?
我们来设定一个场景,假设你是一名爬虫工程师,你现在需要爬取上图中的店铺名称——小龙坎老火锅(工体店),当你分析网络请求时发现请求信息如下:

从请求信息中可以看出,city 大概率代表城市、street 大概率代表街道编号、id 大概率是这个店铺的编号,time 大概率是当前请求的时间戳、key 有可能是生成 sign 的钥匙。如果你想用程序模拟发出这样的请求,你就必须知道 key 的值是怎么来的,这正是前后端工程师设置的反爬虫手段。
这段值看起来像是 Base64 编码后的结果,我们试试用 Base64 进行解码,看看得到什么值:
Ã1áÃĄ
没错,你得到的是这个东西,看起来不像是正常的字符串,也就是说那并不是 Base64 编码的结果。
现在怎么办呢?
翻代码,你需要去翻 JavaScript 代码,尝试找到加密的位置和对应的算法。
经过你一顿搜索和调试,你看到了这样的代码:

这几乎可以肯定,网站就是用了 Base64 进行编码,但为什么解码结果就是不对呢?
百思不得其解
你感到非常困顿
这件事耽误了你两天
总觉得哪里有问题
… …
没错,这就是前后端工程师想要的反爬虫效果,也是这次明修栈道 暗渡陈仓反爬虫设计想要的效果。那么我们怎么设计,又如何实现这样的反爬虫呢?
Base64 编码详解
我们来看看 Base64 编码的规范,看它是如何实现字符串编码功能的。Base64 的 RFC 文档编号为 4648,文档地址为 https://tools.ietf.org/html/rfc4648。RFC4648 约定了 Base16、Base32 和 Base64 的编码规范和计算方法。将字符进行 Base64 编码时:
先要将字符转换成对应的 ASCII 码,得出 8 位二进制数
接着连接 3 个 8 位输入,形成字节数为 24 的输入组
再将 24 位输入组拆分成 4 组 6 位的二进制数
然后将 6 位二进制数转换为十进制数
最后找到十进制数在 Base64 编码表中对应的字符,并将这些字符组合成新的字符串
这个字符串就是编码结果,编码过程中用到的 Base64 编码表如下图所示:
文档中提到:如果字符位数少于 24 位,那么就需要进行特殊处理,即在编码结果的末尾用“=”符号填充。这也正是为什么很多 Base64 编码结果末尾总是带有 1 或 2 个“=”符号的原因。
我们可以通过一个例子来加深对 Base64 编码过程的理解。我们将字符 async 转换成 ASCII 码,并找到对应的 8 位二进制数,字符、ASCII 码和 8 位二进制数的对应值如下图所示:

接着将 3 组 8 位二进制数连接成 24 位的输入组,再将 24 位输入组拆分成 4 组 6 位的二进制数。
要注意的是,如果输入组的元素不足 24 位,那么就用 0 进行填充。24 位输入组转换成 6 位二进制数 的过程下图所示:

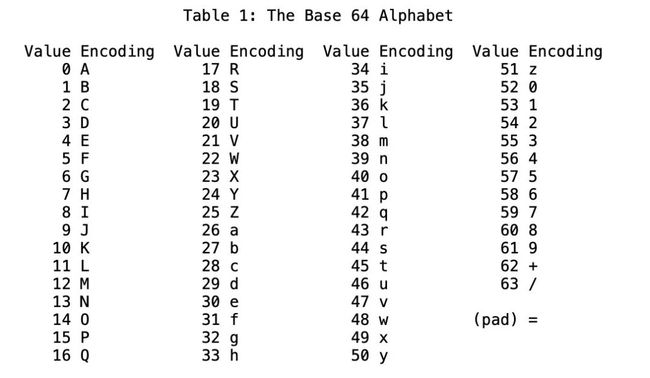
得到 6 位二进制数之后,我们还需要计算出对应的十进制。二进制转十进制其实是按权相加,将 8 二进制数写成加权系数展开式,并按十进制加法规则求和。字符“a”对应的 6 位二进制数为 011000,将其转换成十进制时的计算过程下图所示:
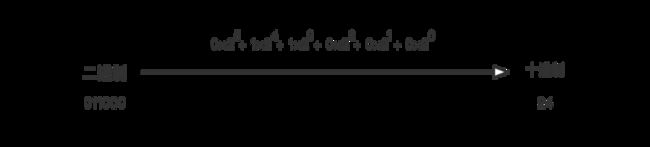
按照这个计算方法,计算其他的 6 位二进制数,最后得到字符“async”对应的十进制值:
24 23 13 57 27 38 12 65
补位字符“=”没有对应的值,本书约定其值为 65。在得到所有的十进制值之后,就可以将其与 RFC4648 中的 Base64 编码表进行映射,从而得出编码后的字符串。映射过程下图所示:

最终得出字符“async”的 Base64 编码结果为“YXN5bmM=”,完整的编码过程如下图所示:

Base64 编码时所用的对照表是固定的,也就是说它的编码过程是可逆的。这意味着我们只需要将编码的流程倒置,就能够得解码的方法。
知识扩展:Base64 编码表中的“+”和“/”会影响文件编码和 URI 编码,我们在实际使用时,需要考虑到应 用场景中是否包含文件编码或 URI 。如果在 URI 场景下使用 Base64,就会引起错误,RFC4648 文档 中给出了一个解决办法:使用“-”和“_”替代“+”和“/”。
基于编码的反爬虫设计
在上一节中我们学习了 Base64 编码的相关知识,了解到编码过程以及使用到的对照表。Base64 被广泛应用在互联网中,有经验的爬虫工程师看到带有“==”符号或者“=”符号的字符串时,自然 就会认为这是 Base64 编码字符串后得到的结果。如:
d3d3Lmh1YXdlaS5jb20=
d3d3Lmp1ZWppbi5pbQ==
这时候,爬虫工程师只需要按照 Base64 解码规则进行倒推,就能得到原字符。很多编程语言有 Base64 解码模块,解码不费吹灰之力。我们可以使用 Python 解码上方的字符串:
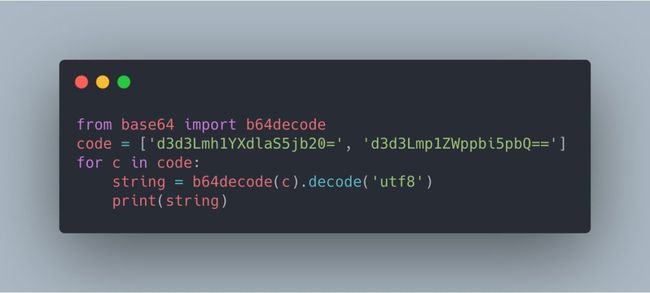
代码运行后,输出结果如为:
www.huawei.com
www.juejin.im
爬虫工程师很轻松就拿到了原字符,这显然不是开发者想要见到的结果。其实我们可以通 过自定义编码规则的方式保护数据。只需要稍微改动一下 Base64 编码过程中用到的对照表,或者改动输入组的划分规则,就可以创造一个新的编码规则。
Base64 编码和解码时都是将原本 8 位的二进制数转换成 6 位的二进制数。如果我们改动位数,将其设置为 5 位或者 4 位,那么就可以实现新的编码规则,对应的 Python 代码如下:
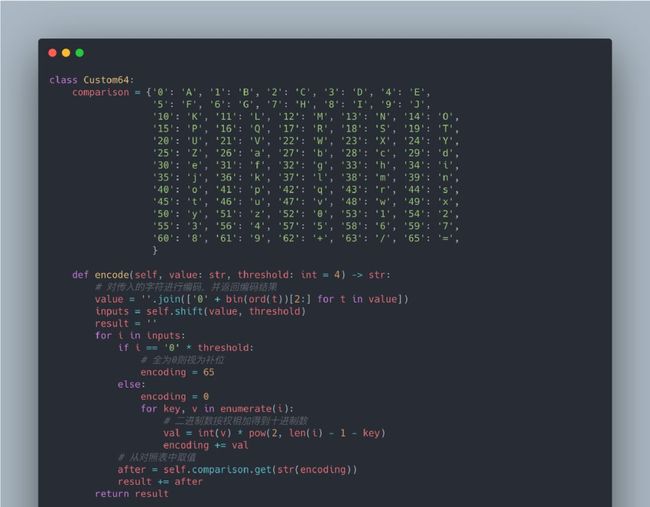
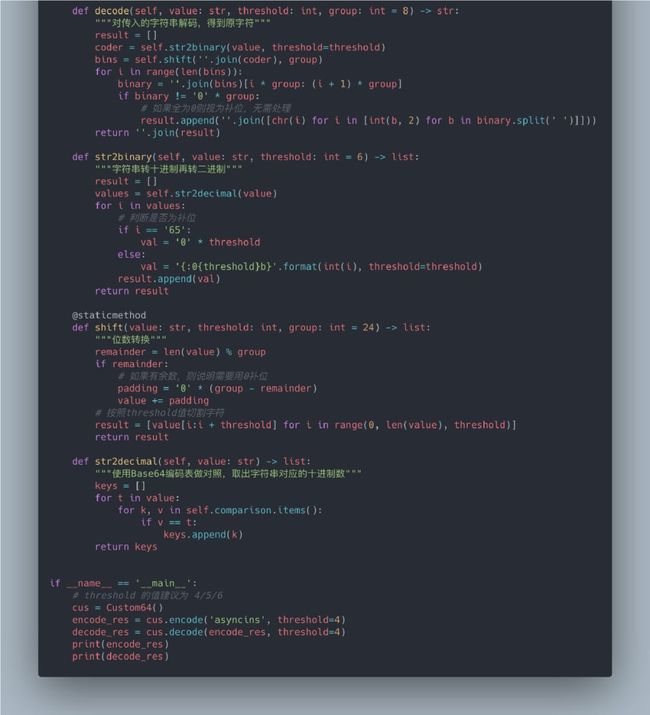
类 Custom64 完成了自定义位数的编码和解码功能。代码大体功能和逻辑如下:
用字典实现 RFC4648 中的 Base64 编 码表
然后定义了用于编码字符串的方法 encode() 和用于解码的方法 decode(),以及其他用于转换的方法
使用参数传递的方式就可以在 Base64 编码和自定义编码之间进行切换
代码运行后,输出结果如下:
GBHDHJGOGDGJGOHD==
asyncins
当我们使用 Custom64 对字符“asyncins”进行编码时,只要设置 threshold 的值不为 6,得到的编码结果就是不相同的。如果爬虫工程师使用 Base64 对该编码结果进行解码,那么他将无法得到正确的原字符。这不仅达到了保护数据的目的,还能够迷惑爬虫工程师,使其将时间花费在“Base64 解 码不成功”的问题上

要注意的是,在 JavaScript 代码中实现时,我们可以将对象名设置为 Base64,编码函数的名称设置为 encode 或者 encrypt,这样一来代码调用时的写法为:
Base64.encode()
// 或者
Base64.encrypt()
就算爬虫工程师跟进 encode 或者 encrypt 函数,看到的也会跟实际的 Base64 编码算法极其相似的代码,一不小心忽略细节,就会错过获得正确破解方法的机会。
同样的方法还可以应用在其他编码或者加密算法上,例如 MD5、AES 或者 SHA256 等。
关于本文
本文改编自《Python3 反爬虫原理与绕过实战》第 10 章,这本书是爬虫领域第一本专门介绍反爬虫的书,从“攻”与“防”两个角度描述了爬虫技术与反爬虫技术的对抗过程,并详细介绍了这其中的原理和具体实现方法。通过这本书,你将了解到签名验证、文本混淆、动态渲染、加密解密、代码混淆和行为验证码等反爬虫技术的成因和绕过方法。书本中介绍到的反爬虫知识覆盖了市面上 90% 以上的反爬虫手段知识点,非常硬核。

掌握这些知识后,你的理论基础将非常扎实,能够轻松应对一线大厂中高级爬虫工程师面试的理论和思路问题。实战方面,除了本书搭建的 21 个在线练习示例之外,还需要结合工作中遇到的综合反爬虫进行演练,从而稳步提升个人技术实力。
送书福利
为了感谢读者们对搜狐技术产品的支持,我们准备了 5 本《Python3 反爬虫原理与绕过实战》赠送给粉丝。
参与方式:进入文末留言板小程序进行留言,留言点赞数排名前五的同学就可以获得我们的奖品啦~
时间截止至下周四零点,开奖后三天内中奖者要抓紧填写收货信息哦 ~
~
活动最终解释权归公众号官方所有
也许你还想看
▼
NSURLSession最全攻略 2020-03-12
探秘AFNetworking 2020-03-12
开发者必知必会的ASCII规范与编程实现 2019-12-26
加入搜狐技术作者天团
千元稿费等你来!
戳这里!☛

