论文翻译《Background modeling methods in video analysis: A review and comparative evaluation》
Abstract
前景检测方法可以有效地将前景对象(包括运动或静态对象)与背景区分开来,这在视频分析尤其是视频监控应用中具有重要意义。一个良好的背景模型可以获得良好的前景检测结果。虽然已经提出了很多背景建模方法,但是对它们的综合评价却很少。这些方法面临着光照变化和动态背景等诸多挑战。本文首先分析了各种背景建模方法在视频分析应用中的优缺点,然后从质量和计算成本两方面比较了它们的性能。使用Change detection.Net(CDnet2014)数据集和另一个不同环境条件(室内、室外、雪)的视频数据集来测试每种方法。实验结果充分证明了传统的和最近提出的最先进的背景建模方法的优缺点。这项工作对研究人员和工程实践者都有帮助。Codes of background modeling methods evaluated in this paper are available at www.yongxu.org/lunwen.html.
1. Introduction
很多背景模型被提出,它们通常共用以下方案[2,12]:利用第一帧或前几帧建立背景模型,然后比较当前帧和背景模型,检测前景目标,最后更新背景模型。各种背景建模方法可以归纳为pixel-based,region-based, and hybrid-based方法。背景建模方法也可以分为参数和非参数方法。
基于像素的参数化方法中最著名的一种是高斯模型。Stauffer和Grimson提出[16, 17]高斯混合模型(GMM) ,它用K个高斯函数的混合对每个像素进行建模。然后,利用基于在线EM的算法对背景模型中的参数进行初始化,对GMM模型进行了改进。Zivkovic[18, 43]还提出了自适应GMM (AGMM)以有效更新GMM中的参数,Lee[19]在不改变GMM的稳定性的情况下使用了新的自适应学习率来提高收敛率[9]。与参数背景建模方法不同,Maddalena等[30]提出了基于人工神经网络自组织(SOBS)的非参数算法。Kim等[28,29]提出了一种码本方法来建模背景,该方法通过初始化码本的码字来存储背景状态。wang[55]提出了一种计算背景样本一致性(SACON)的方法,用于估计背景的统计模型,即每像素。SACON利用颜色和运动信息来检测前景目标。 Barnich等[23,24]提出了一种名为Vibe的基于像素的非参数算法,利用一种新的随机选择策略来检测前景。Vibe的性能优于许多其他最先进的方法,它可以代表在最近的帧[25]确切的背景变化。Van Drogenbroeck和Paquot [ 26 ]进一步研究了Vibe方法,并考虑了提高Vibe性能的额外约束。虽然基于像素的背景建模方法可以有效地获得前景物体的详细形状,但是它们很容易受到噪声、光照变化和动态背景的影响。
不同于基于像素的方法,基于区域的方法利用像素间的关系将图像分割成区域,并从图像区域中识别前景目标。Elgammal等[21,41]提出了一种新的基于核密度估计(KDE)的非参数背景建模方法。Heikkila等人[67]使用一种称为局部二值模式(LBP) [77]的判别纹理特征来建模背景。他们基于背景的部分重叠区域建立LBP直方图,并通过直方图交集将它们与传入帧每个区域的LBP直方图进行比较。liu等[68]提出了一个基于二进制描述符的背景建模方法,用于提取光照变化下的前景目标。此外,huang等人[69]将背景建模为二进制描述符样本,可以代替参数分布。与基于像素的方法相比,基于区域的方法可以降低噪声的影响,但只能获得前景物体的粗略形状。
混合方法结合了基于像素和区域的方法,可以实现更好的背景表示,并处理光照变化和动态背景[70]。Toyama等[1]提出的Wallvol系统利用像素级、区域级和帧级信息获得背景模型。它使用Wiener filter在像素级预测背景值,在区域级填充前景对象的均匀区域,在帧级处理视频序列的突然或全局变化。huang等[71]集成了基于像素的RGB颜色和光流运动来建模背景。混合方法虽然能有效地从背景中提取前景对象,但其计算复杂度相对较高。因此,Tsai等[72]提出了在硬件中嵌入混合算法来实现前景检测。

在本文中,我们使用了检测.Net(CDnet2014)[39]数据集和另一个视频数据集[83]进行背景建模方法的对比实验。
CDnet2014数据集包含53个视频序列,代表11个视频类别,包括有汽车、行人和其他物体的室外和室内环境。视频中的大多数帧都经过了注释,以获得GT前景、背景和阴影区域边界。另一个视频数据集[83]包含四个视频序列。该数据集包含了大尺寸遮挡的挑战,并且每个序列中每10帧被标记为GT。
本文从两个方面客观地评价了背景建模方法的性能。对于方法的客观比较,使用召回率、特异性、假阳性率(FPR)、假阴性率(FNR)、错误分类百分比(PWC)、精确度和F-测量评估指标来表示检测的准确性。为了计算探测精度,我们将前景探测掩模与地面真实情况进行了比较。对于一种背景建模方法,速度和内存需求的评估也很重要,因此也进行了相应的评估。本文的其余部分安排如下:第二部分分析了背景建模方法所面临的挑战。第3节简要回顾了背景建模的代表性方法。第四部分给出了实验方案。第五节给出了实验结果。本文在第六节结束。本文的结构如图1所示。

3. Representative methods
在这一部分中,本文回顾了需要比较和评价的背景建模算法。这些算法从最经典的基于像素的参数化方法,如GMM[16,17]到复杂的非参数方法[23,24,27,30],以及基于区域的方法,如KDE[21,41]。这些方法旨在提高分类的准确性,并在可能的条件下实现最大速度和低内存消耗[14]。

3.1. Gaussian mixture model (GMM)
传统的GMM有几个优点。它不需要在运行过程中存储一组输入数据。GMM使用均值和协方差来度量像素。这意味着每个像素都有自己唯一的阈值,而不受统一的全局阈值的约束。GMM的多模态允许它处理由树挥舞和逐渐改变光照引起的多模态背景。
然而,GMM也存在一些缺点。高斯数必须预先确定,建议设置为3、4或5 [16]。
定义后台模型时,需要初始化GMM的参数。此外,结果取决于分布规律,该规律可以是非高斯分布,它只是缓慢地从故障中恢复。一系列不移动物体的训练帧来训练GMM背景模型是GMM的另一个局限性,该步骤需要足够的内存。
3.2. Kernel density estimator (KDE)
背景模型方法可以分为参数化方法和非参数化方法。参数化方法通过建立基于图像颜色分布的参数估计概率分布来估计背景[9]。在非参数方法中,引入核函数对分布进行建模。对于这种方法,Elgammal等人[21]在N个最近的强度值样本{x1,x2…,xn}上引入了核密度估计来建模背景分布。

(翻译上图)在该方法中,每个像素xt在时间t的强度的概率可以通过公式6计算,其中,N是采样数,d是通道数,^表示每个颜色通道的核函数带宽,其中m是像素的连续值相对于样本的绝对偏差中值[21]。Mittal和Paragio[40]还使用了一种基于可变带宽核的更复杂的方法来确定s。
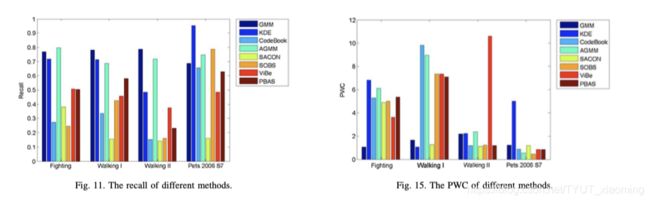
如果Pr(x i) KDE方法的优点之一是能够避开一部分精细的参数估计步骤,因为它依赖于过去观察到的像素值[21,40-44]。另一个优点是KDE可以处理多模式背景,特别是在快速变化的背景下,直接将新观察到的值包含在像素模型中。 KDE也有缺点。例如,在整个前景检测过程中,KDE需要在内存中保存N个帧,当N较大时,这是非常耗时的。为了解决这些问题,研究人员提出了不同的改进措施。例如,可以通过确定帧缓冲器的适当大小来减少训练样本的数目[45]。此外,采用递归策略保持背景以减少计算时间也是可行的[46,47]。然而,关键的改进是改变核函数,例如Zivkovic[43]在矩形核函数中使用了可变的核带宽。Ianasi等人[45]和Tanaka等人[49]也使用了矩形核函数,但具有恒定的核带宽。Tavakkoli等人[48]在高斯核函数中自动选择核带宽,Ramezani等人[50]使用Cauchy核函数。 基本GMM使用固定数量的组分,但是Zivkovic基于[54]的结果设计了一个改进的算法来自适应地调整GMM的参数和组分数目。改进后的算法可以通过为每个像素选择组件的数目来自动适应场景[18]。 给定时间t处的新数据样本xt,该方法递归地更新参数w, u, 6,如下所示 例如,如果与组件的马氏距离小于3,则样本与组件“接近”。与第i个分量的平方距离计算为。 如果部件被排序为具有递减重量w,则公式(5)更新如下 公式(12)其中,cf是在不影响背景模型的情况下属于前景对象的最大数据部分的度量。例如,如果一个新对象进入场景并在一段时间内保持静止,则它将作为一个附加的簇在时间上呈现。由于“旧”背景被遮挡,新簇的权重w将不断增加。如果物体长时间保持静止,它作为一个物体的重量将大于cf,它将被归类为背景的一部分。 Maddalena和Petrosino[30]提出了一种基于人工神经网络自组织的背景建模方法SOBS。提出的方法能够适应动态背景、逐渐变化的光照和摄像机图像,并对固定摄像机捕捉到的不同类型的视频实现鲁棒检测[30]。 对于每个像素,该方法构建一个由n*n个权值向量组成的神经网络图,每个像素的模型可以表示为C =(c1,c2,…cn)。整个权重向量集作为背景模型。对于第t序列帧的一个输入像素pt,如果在当前像素模型c中找到一个最佳匹配的权重向量cm,将pt视为背景像素。否则,如果pt是阴影,则仍将其视为背景,不应用于更新相应的权重向量。如果pt不是背景和阴影,它应该属于前景。 如果在模型C中,权重向量cm与pt之间的距离是所有权重向量中最小的,并且距离不大于固定阈值,则权重向量cm为传入像素pt提供最佳匹配。此公式由 阈值ε可以区分前景像素和背景像素,它是一个小常数,定义为。ε1应大于ε2,因为ε1的高值允许在前K序列帧内获得(可能是粗糙的)背景模型,包括观察到的几个像素强度变化,应将ε2设置为较低的值以获得更精确的背景模型。 该算法利用视频序列的第一幅图像初始化每个像素神经元,并通过加权平均法实现神经元的自组织。只有当像素被视为背景像素时,背景模型才会根据保守性和区域性原则进行更新,更新后的当前像素模型将扩展到相邻的模型中。 SOBS是基于通过学习图像序列变化来建立图像序列神经背景模型的思想[57],因此它不需要有关所涉及模式的先验知识。该网络表现为一个竞争性神经网络,实现赢家通吃的功能,其相关策略改变了神经元的局部突触可塑性,使得学习它们的空间局限于最活跃神经元的局部邻域。因此,神经背景模型能够适应场景的变化,能够捕捉到图像序列中最持久的特征。 然而,对于每个颜色像素,SOBS构建了一个由n*n个权重向量组成的神经元映射图。因此,每一个输入的样本必须在权重向量之间进行测量,并确定最小值,这是非常耗时的。如果有一个有效更新背景模型的策略,这个问题可能会得到解决。 Barnich和Droogenbroeck[23]使用了在背景建模领域首次使用的随机策略来选择值来构建基于样本的背景估计。该算法需要为每个像素建立一个缓存,以保存前一帧中N个背景样本值M(x)= {v1,v2,…vn}的集合。随机抽取M为单位的样本。输入像素根据其对应的模型M(x)进行分类。该算法定义了半径R以v(x)为中心的球面SR(v(x)),并从一组样本中确定值v(x)的最近样本。如果该球体与模型样本集合M(x)的集合交集的基数(用#表示)大于或等于给定阈值#min[24],则将像素值v(x)视为背景。 在背景模型的更新过程中,采用了非递归和保守的更新策略。如果被归类为背景,像素值将随机替换M(x)中的样本。与“先入先出”策略相比,该策略保证了像素模型中先前样本值的概率存在指数单调衰减。此外,算法中使用的随机时间策略也扩展了背景像素模型所覆盖的时间窗口。当一个像素值被分类为背景时,由于采用了时间子采样因子,该像素在p中有一次被选择来更新其像素模型。不幸的是,一个背景样本有可能被错误地归类为前景,这会妨碍背景像素模型的更新。为了解决这个问题,Vibe通过一个背景样本传播方案来使用空间一致性。根据该方案,当一个像素被更新时,该算法使用该值v(x)来更新M)中的邻域像素样本。 Vibe将背景训练序列像素的观察颜色值作为观察背景的样本。因此,与其他方法相比,Vibe具有更高的性能,因为使用样本作为背景模型可以成功地表示背景变化[25]。然而,Vibe的缺点是它只使用像素的颜色值来构建背景,但是颜色值通常对噪声和光照变化敏感[58]。因此,Vibe的前景检测性能很容易受到噪声和光照变化的影响。此外,Vibe使用固定参数来确定像素是否属于背景。因此,对于不同的视频,特别是包含动态背景的视频,Vibe需要手动调整参数以适应背景的变化。 我们在像素级pixel-level.评估了背景建模方法的性能。因此,我们将前景检测视为每个像素的二进制分类。这一分类的正确性通过CDnet 2014挑战[76]的框架来表示。 recall, specificity, false positive rate (FPR), false negative rate (FNR), percentage of wrong classification (PWC), precision, and F-measure. 在本文中,我们测试了大量的背景建模方法,包括传统的GMM方法和最近的Vibe和PBAS方法。方法的细节在第3节中介绍。表2显示了我们在本文中评估的方法的概述。 对于GMM和AGMM方法,我们使用了Zivkovic编写的基于代码的实现来实现他的增强GMM。Vibe和PBAS方法的程序由Vibe和PBAS的作者提供。我们使用了作者提出的两种方法的最佳参数。对于KDE方法,我们使用了BGSlibrary中提供的实现。我们根据BGS中的建议调整了参数。由于SACON、SOBS和CodeBook方法的代码不可用,我们自己完成了代码,并根据作者的论文选择了最佳参数。 在背景建模方法的评价中,选择合适的参数是至关重要的。每种背景建模方法使用的各种参数设置如表3所示。默认参数,LF表示学习帧,a表示学习速率,其他参数见第3节。 我们评估了第3节中讨论的八种最先进的背景建模方法。我们测试了这些不同的背景建模方法,没有使用任何预处理和后处理方案。我们还提供了内存量以及每种方法所使用的计算时间。 首先,我们在CDnet2014视频数据集和另一个视频数据集上展示了评价方法的实验结果,如图2和3所示。用于评估不同方法的场景包括恶劣天气、基线、相机抖动、动态背景、间歇运动对象、低帧速率、云台、阴影、热、湍流、照明、步行I、步行II和Pets 2006 S7。热视频是由远红外摄像机拍摄的。每个场景都有几个视频。 这些危急情况具有不同的时空属性。我们从每个视频中选择一个典型的帧来代表每个视频。图2(a)-(e)和图3(a)-(e)是从CDnet2014数据集中的10个类别中选择的不同视频。图2(f)、(g)和图3(f)、(g)是从[83]中提出的数据集中选择的四个视频。图2(1)和图3(1)示出了视频的原始帧,图2(2)和图3(2)是地面真实数据的结果。图2(3)-(10)和图3(3)-(10)是最新的背景建模方法的前景检测结果。 Fig. 2. Foreground detection results of the bad weather, baseline, camera jitter, dynamic background, and intermittent object motion video from the CDnet2014 dataset, fighting, and walking I video from the dataset in [83]. (1) original frame. (2) ground truth. (3) GMM. (4) KDE. (5) CodeBook. (6) AGMM. (7) SACON. (8) SOBS. (9) Vibe. (10) PBAS. Fig. 3. Foreground detection results of the low frame rate, PTZ, shadow, thermal, and turbulence video from the CDnet2014 dataset, walking II and Pets 2006 S7 from the dataset in [83]. (1) original frame. (2) ground truth. (3) GMM. (4) KDE. (5) CodeBook. (6) AGMM. (7) SACON. (8) SOBS. (9) Vibe. (10) PBAS. 表4给出了[83]中提出的视频数据集中八种背景建模方法的七种评估指标。表5显示了CDnet2014数据集中八种背景建模方法的七种评估指标。不同方法的优势可以通过召回率、精密度、F-测度等指标来证实。哪种方法能获得较高的查全率、查准率和F测量分数,而PWC、FPR和FNR取得较低的数值,比较显而易见。对于每一个评价指标,我们给出了八种背景建模方法在不同场景下的结果,从图4到图17可以看出。 在选择背景建模方法时,评估其内存消耗和执行时间非常重要。在我们的实验中,每种方法都是在一台英特尔酷睿i3-3320计算机上用OpenCV库实现的,它有3.3ghz的CPU和4gb的内存。我们使用了三个不同大小的视频来估计内存和时间消耗。所有视频每秒25帧在我们的表中。 我们评估了八种背景建模方法的性能,并给出了挑战和综合实验结果。根据这些方法对运动的正确检测能力以及对各种视频(如室内/室外环境、运动背景、热视频)的时间和内存要求,对这些方法进行了测试。我们使用了七个评估指标来比较这些方法的相对准确度。总体评价见表4和表5。 虽然每种测试方法都有不同的优缺点,但我们发现AGMM、SOBS、Vibe和PBAS是最有前途的方法。但值得注意的是,复杂的方法并不总能产生更精确的结果,尽管它们在许多挑战中表现出良好的性能。考虑到背景建模方法的未来发展,我们认为背景建模方法能够处理诸如“移动物体”、“投射阴影”和“光照变化”等复杂情况,即使是我们研究的最好方法也不能完全应对这些挑战。 大多数背景建模方法都能很好地处理静态背景,但如何使其适应动态场景或移动背景是背景建模领域的一大挑战。 3.3. CodeBook
3.4. Adaptive Gaussian mixture model (AGMM)


3.5. Consensus-based method (SACON)
3.6. A self-organizing background subtraction method (SOBS)


3.7. A universal background subtraction algorithm (Vibe)
3.8. Pixel-based adaptive segmenter (PBAS)
4. Experimental protocol
4.1. Evaluation dataset
4.2. Performance measure

4.3. Experimental framework

5. Experimental results








6. Conclusion