Hive 架构
下面是Hive的架构图。

Hive的体系结构可以分为以下几部分
(1)用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是CLI,Cli启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至Hive Server。在启动 Client模
式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。 WUI是通过浏览器访问Hive。
(2)Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,
比如select * from tbl不会生成MapRedcue任务)。
(一)用户接口
Hive 对外提供了三种服务模式,即 Hive 命令行模式(CLI),Hive 的 Web 模式(WUI),Hive 的远程服务(Client)。下面介绍这些服务的用法。
1、 Hive 命令行模式
Hive 命令行模式启动有两种方式。执行这条命令的前提是要配置 Hive 的环境变量。
1) 进入 /home/hadoop/app/hive 目录,执行如下命令。
./hive
2) 直接执行命令。
hive ‐‐service cli
Hive 命令行模式用于 Linux 平台命令行查询,查询语句基本跟 MySQL 查询语句类似,运行结果如下所示。
[hadoop@cdh01 hive]$ hive hive> show tables;
OK stock
stock_partition tst
Time taken: 1.088 seconds, Fetched: 3 row(s) hive> select * from tst;
OK
Time taken: 0.934 seconds hive> exit;
[hadoop@cdh01 hive]$
2、Hive Web 模式
Hive Web 界面的启动命令如下。
hive ‐‐service hwi
通过浏览器访问 Hive,默认端口为 9999。
3、 Hive 的远程服务
远程服务(默认端口号 10000)启动方式命令如下,“nohup...&” 是 Linux 命令,表示命令在后台运行。
nohup hive ‐‐service hiveserver & //在Hive 0.11.0版本之前,只有HiveServer服务可用 nohup hive ‐‐service hiveserver2 & //在Hive 0.11.0版本之后,提供了HiveServer2服务
Hive 远程服务通过 JDBC 等访问来连接 Hive ,这是程序员最需要的方式。
本课程我们安装的是hive1.0版本,所以启动 hive service 命令如下。
hive ‐‐service hiveserver2 & //默认端口10000
hive ‐‐service hiveserver2 ‐‐hiveconf hive.server2.thrift.port 10002 & //可以通过命令行直接将端口号改为hive的远程服务端口号也可以在hive-default.xml文件中配置,修改hive.server2.thrift.port
对应的值即可。
< property>
< name>hive.server2.thrift.port< /name>
< value>10000< /value>
< description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'bina
< /property>
Hive 的 JDBC 连接和 MySQL 类似,如下所示。
import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; public class HiveJdbcClient {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";//hive驱动名称 hive0.11. //private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";//hive驱动名称 public static void main(String[] args) throws SQLException {
try{
Class.forName(driverName); }catch(ClassNotFoundException e){
e.printStackTrace();
System.exit(1);
}
//第一个参数:jdbc:hive://cdh01:10000/default 连接hive2服务的连接地址
//第二个参数:hadoop 对HDFS有操作权限的用户
//第三个参数:hive 用户密码 在非安全模式下,指定一个用户运行查询,忽略密码
Connection con = DriverManager.getConnection("jdbc:hive://cdh01:10000/default", "hadoo System.out.print(con.getClientInfo());
}
}
(二)元数据存储。
Hive将元数据存储在RDBMS中,有三种模式可以连接到数据库:
(1)单用户模式。此模式连接到一个In-memory 的数据库Derby,一般用于Unit Test。
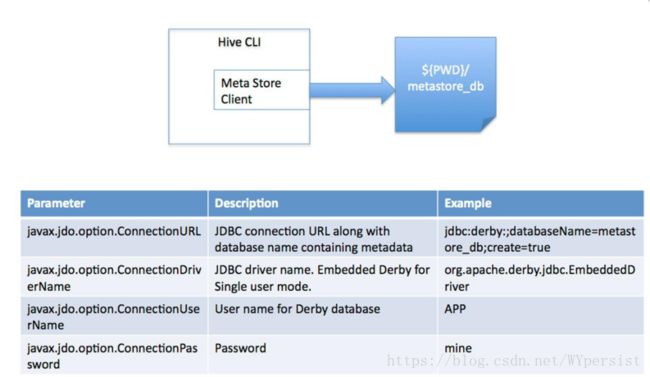
(2)多用户模式。通过网络连接到一个数据库中,是最经常使用到的模式。
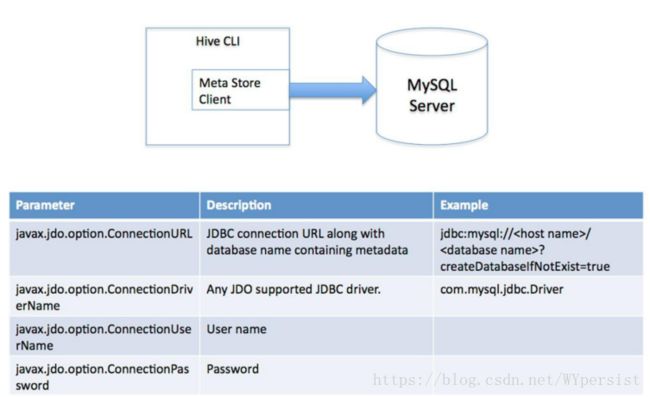
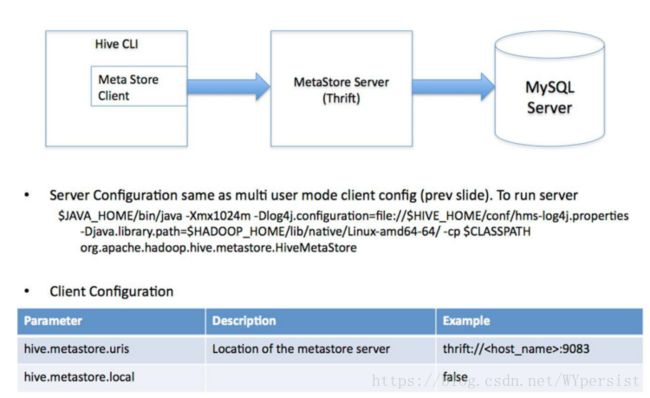
(3)远程服务器模式。用于非Java客户端访问元数据库,在服务器端启动
MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。
对于数据存储,Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。Hive中所有的数据都存储在HDFS中,存储结构主要包括数据库、文件、表和
视图。Hive中包含以下数据模型:Table内部表,External Table外部表,Partition分区,Bucket桶。Hive默认可以直接加载文本文件,还支持sequence file 、RCFile。
(三)解释器、编译器、优化器。
1)解析器(parser):将查询字符串转化为解析树表达式。
2)语义分析器(semantic analyzer):将解析树表达式转换为基于块(block-based)的内部查询表达式。
3)逻辑策略生成器(logical plan generator):将内部查询表达式转换为逻辑策略,这些策略由逻辑操作树组成。
4)优化器(optimizer):通过逻辑策略构造多途径并以不同方式重写。