Hive安装
Hive安装。
Hive是基于hadoop的,如果没安装hadoop的小伙伴请先去安装hadoop。
Hive安装非常简单,分成三种模式。
1.嵌入模式
2.伪分布模式。
3.完全分布模式。
首先,无论哪个模式,都需要先下载Hive安装包。直接去官网https://hive.apache.org/下载一个和你的hadoop版本契合的hive版本即可。这里我使用已经编译好的bin,比较方便。
1.首先是嵌入模式,嵌入模式的意思是元数据,即metastore存放在本地的hive自带的derby数据库当中。
嵌入模式有很大的局限性,他一次只允许创建一个连接到hive中,不允许多用户访问,一般只用于demo,用来尝试一下当前hive是否能正常启动。
使用嵌入模式的方式非常简单,解压好hive到某一目录,进入hive目录的bin目录下,直接./hive即可进入hive命令行模式,hive嵌入模式就启动了。当然前提是你的hadoop已经启动了。
建议先使用嵌入模式,尝试hive是否能正常启动,再使用其他模式,如果嵌入模式无法启动,建议更换hive版本。
2.伪分布模式和完全分布模式。
这两个模式非常类似,对于hive来说其实是一样的,区别在于伪分布模式实际上连接的是本地的数据库,而完全分布模式连接的是远程的数据库。
和嵌入模式不同,这两个模式将元数据存放在其他的我们指定的数据库当中,例如mysql数据库。
一般开发测试环境都会使用这两个模式。建议在使用嵌入模式尝试版本没有问题之后就使用这两个模式之中的其中一个。
使用mysql作为metastore的伪分布模式
前提:安装好mysql
配置:
1.解压hive到我们希望的目录之后,例如/usr/local/hive/
2.进入其中的lib目录,由于我们需要和mysql进行连接,hive的连接是基于JDBC的,所以我们需要提供一个jdbc的连接包给hive。到mysql官网下载jdbc的connector:https://dev.mysql.com/downloads/connector/j/。将下载好的jar包复制进去lib目录下。
/apache-hive-1.2.2-bin/lib$ ls | grep mysql
mysql-connector-java-5.1.42-bin.jar
3.进入/apache-hive-...-bin/conf目录。
vim hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://127.0.0.1:3306/hive?characterEncoding=UTF-8
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
your user
username to use against metastore database
javax.jdo.option.ConnectionPassword
your password
password to use against metastore database
保存即可。
4.最后配置环境变量。配置在./bashrc比较舒服。
增加以下环境变量:
export HIVE_HOME=hive解压目录
export PATH=$HIVE_HOME/bin:$PATH在使用hive数据库之前,我们还需要去mysql数据库中创建数据库。
打开mysql数据库
create database hive;
alter database hive character set latin1;
我们就可以尝试使用hive了。
一开始是没有数据的。
~/Desktop$ hive
Logging initialized using configuration in jar:file:/usr/local/hive/apache-hive-1.2.2-bin/lib/hive-common-1.2.2.jar!/hive-log4j.properties
hive>
可以发现这里多了很多的表,这些就是元数据。存放在mysql数据库当中。
我们可以尝试创建一张表。
hive> create table test2 (
> id int,
> name string);
OK
Time taken: 0.578 seconds
hive>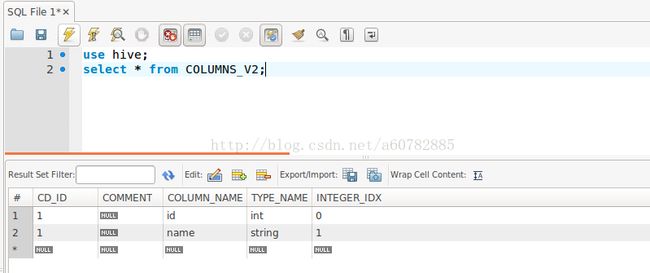
这里的CD_ID指的是test2表的id,里面列对应列名,以及对应的类型说明等等。
这说明hive中的元数据确实是存在mysql当中的。
hive是基于hadoop的。存放表的信息,即元数据是在mysql当中,但是表的实际数据是存放在hadoop的hdfs当中的。
我们来查看一下是否如此。
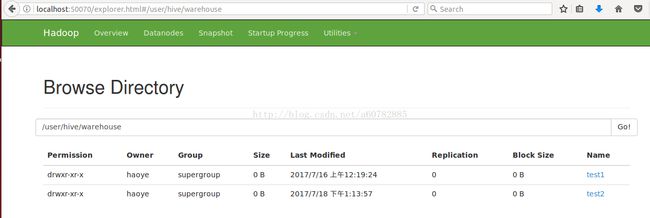
我们在hadoop的目录下确实能找到我们存放的test2表。