Hive常用窗口函数实战
点击蓝字关注!

本篇文章大概3799字,阅读时间大约10分钟
本文介绍了Hive常见的序列函数,排名函数和窗口函数。结合业务场景展示了Hive分析函数的使用
Hive作为一个分析型的数据仓库组件提供了很多分析函数,熟练使用分析函数可以快速的进行离线业务的开发。
窗口函数属于分析函数,主要用于实现复杂的统计需求。窗口函数和聚合函数的主要区别是:在分组后,窗口函数会返回组内的多行结果而聚合函数一般返回一行结果。
1
over关键字
窗口函数是针对每行数据的窗口,使用over关键字可以进行窗口创建,如果over中没有给定参数,会统计全部结果集。
举个栗子
数据集:销售表
| dep_no |
部门 |
| series_code |
商品类型 |
| code_sales_num |
销售数量 |

业务场景
统计每个部门内每种商品占总销售数量的百分比
如果不使用over关键字,那么第一步应该先计算总数,然后把总数带入hql进行计算,HQL如下:
--计算总数 总数为22089,再带入hql中进行计算
select sum(code_sales_num) from lab.dep_sales_detail
--计算商品销售占比
select dep_no, series_code, code_sales_num, 22089 as total_sales_num,
concat(round((code_sales_num / 22089) * 100, 2), '%') as sales_ratio
from lab.dep_sales_detail这种写法会产生两个job,需要把第一步的结果带入第二步进行计算,比较麻烦
使用over关键字进行开窗操作
over关键字可以清晰的表达统计商品占比的业务逻辑,且只产生了一个job
select dep_no,
series_code,
code_sales_num,
sum(code_sales_num) over() dep_sales_num ,
concat(round((code_sales_num / sum(code_sales_num) over() * 100), 2), '%') as sales_ratio
from lab.dep_sales_detail执行结果如下

2
partition by
partition by表示在over执行的窗口中进行分区操作,也就是在进行分区统计
业务场景
统计每个部门内每种商品占该部门总销售数量的百分比
HQL:
select dep_no,
series_code,
code_sales_num,
sum(code_sales_num) over(partition by dep_no) dep_sales_num ,
concat(round((code_sales_num / sum(code_sales_num) over(partition by dep_no) * 100), 2), '%') as sales_ratio
from lab.dep_sales_detail执行结果

这里可以看到partition by子句将dep_no分为了两组,分别统计其总和
3
partition by order by
over(partition by order by)子句,统计的是从分区的第一行到当前行的统计值,可以认为是window函数的特例
业务场景
统计每天每个部门每种商品的累计销售情况
数据集:每日销售表
| dep_no |
部门编号 |
| series_code |
商品类别 |
| sales_date |
销售日期 |
| sales_num |
销售数量 |
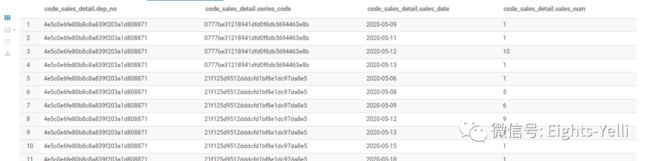
该业务表达的是按照日期统计累计的销售情况,也就是以每个商品进行分区,从初始行一直累加到当前行的统计值
HQL
select series_code,
sales_date,
sales_num,
sum(sales_num) over (partition by series_code order by sales_date) as cum_sales
from lab.code_sales_detail
从结果来看,该HQL实现了日期升序下的销售数量累加统计
4
window窗口
partition by order by语法给出了一个从分区首行到当前行的窗口,如果业务需要对窗口进行细粒度划分,则需要使用窗口函数
窗口函数中可以指定窗口大小,下表展示了一个商品从5月1日开始到6月1日的销售情况
unbounded preceding指分区的上限——分区的第一行
1 preceding指当前行的上一行
1 following指当前行的下一行
unbounded following指分区的下限——分区的最后一行

业务场景
统计每种商品近7天的销售数量
思路:采用一个6 preceding到current row的窗口进行业务统计
HQL
select series_code,
sales_date,
sales_num,
sum(sales_num) over (partition by series_code order by sales_date rows between 6 preceding and current row) as cum_sales
from lab.code_sales_detail
上述的HQL实现了一种滑动窗口的效果,也就是从分区的顶部开了一个7个元素的窗口在以步长=1的方式往下滑动求和
Tip:以下两个窗口的语义相同
-- 窗口1
over (partition by series_code order by sales_date
rows between unbounded preceding and current row)
-- 窗口2
over (partition by series_code order by sales_date)5
排名函数-TopN求解
对数据集分组求排名的需求非常常见(Top-N)
求取各产品线的销量前三
求取产品各功能模块使用次数前三
Hive可以非常便捷的利用排名函数实现类Top-N的需求。常用的排名函数有以下三个:
| 函数名 |
特点 | 例子 |
| row_number |
顺序增加排名 |
1 2 3 4 5...... |
| rank |
相同排名并列 且留下顺序空位 |
1 2 2 4 5...... |
| dense_rank |
相同排名并列 且顺序增加 |
1 2 2 3 4...... |
测试数据:班级 - 学生 - 成绩

按照班级用三种排名函数进行排名,HQL如下:
select cname, sname, score,
row_number() over (partition by cname order by score desc) as row_number_res,
rank() over (partition by cname order by score desc) as rank_res,
dense_rank() over (partition by cname order by score desc) as dense_rank_res from t2;查询结果如下

可以看出row_number会一直按照排序顺序走,rank如果存在并列的情况,会进行计数,也就是说rank函数认为并列的记录会进行排名占位。相反,dense_rank认为并列的记录不会占用排名的顺序。
以上三个函数需要根据业务场景灵活使用。
业务场景
统计每个班的前三名,并列名次算作一个名次。
并列算作一个名次则使用dense_rank函数,先排名然后对名次进行过滤即可
HQL:
with q1 as (
select cname, sname, score,
dense_rank() over (partition by cname order by score desc) as rank
from t2
)
select * from q1
where rank <= 3查询结果如下:

6
序列函数-物联网状态变化统计分析
Hive中常见的序列函数
| lag |
当前行上一行数据 |
| lead |
当前行下一条数据 |
| first_value |
分区窗口内的第一个值 |
| last_value |
分区窗口内的最后一个值 |
| ntile |
将分组数据按顺序切分 |
有了之前的分析函数经验,这里不展示每个序列函数的用途,下面以物联网的一个典型场景介绍lead函数的使用。
业务场景
统计物联网控制板上温度控制模块的使用次数(曾经为了实现这个需求,我写了Spark应用去分组按照时间排序,然后遍历数据集。。。 ),其中温控模块的关闭状态为0,打开状态为1。统计使用次数,即是统计温控模块的状态从0-1的变化次数。
),其中温控模块的关闭状态为0,打开状态为1。统计使用次数,即是统计温控模块的状态从0-1的变化次数。
数据格式:设备ID - 时间戳 - 温控模块状态
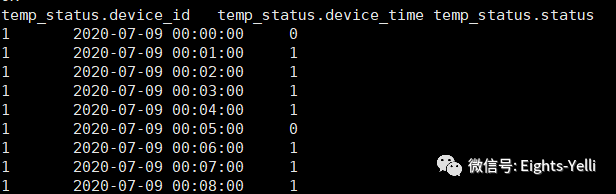
统计思路:统计0-1的状态跳变,在当前行获取上一行的status值作为一列并在最后即可,然后通过lag_status = 0 and status = 1即可统计出使用的次数
HQL:
select device_id, device_time, status,
lag(status) over(partition by device_id order by device_time) as lag_status
from temp_status;
完整的统计HQL如下:
with q1 as (
select device_id, device_time, status,
lag(status) over(partition by device_id order by device_time) as lag_status
from temp_status
)
select device_id, count(1) as use_num
from q1
where lag_status = 0 and status = 1
group by device_id执行结果

 Hive常见的窗口函数你会了么?
Hive常见的窗口函数你会了么?

扫码二维码
获取历史文章
Eights


喜欢本文就点个在看吧~
