局部性原理在php、mysql、kafka的实际应用
何为局部性原理?
工作已经快10年的时间,看了很多各种技术书籍,总结了其中一些共性,其中就有一点,在系统性能方面,尤其是存储方面,局部性原理都在其中扮演着非常重要的角色,比如PHP5到PHP7的优化、比如MySQL索引、kafka的page cache 的应用等等,都或多或少夹杂着局部性原理在其中的应用。
那么,究竟什么是局部性原理?这里一般分为2种:
时间局部性:如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
空间局部性:在最近的将来将用到的信息很可能与正在使用的信息在空间地址上是临近的。
总结起来就是一句话:当一个数据被用到时,其附近的数据也通常会马上被使用。
CPU缓存与局部性原理
CPU的运算速度实在太快了,现有的内存条和硬盘是跟不上这个速度的,为了解决CPU运行处理速度与内存读写速度不匹配的矛盾,在CPU和内存之前,加入了L1、L2、L3三个级别的缓存,缓存有着更快的速度,但是考虑到CPU芯片的面积和成本,缓存一般都特别小。一二三级缓存的成本依次降低,因此容量依次增大。CPU会先在最快的L1中寻找需要的数据,找不到再去找次快的L2,还找不到再去找L3,L3都没有那就只能去内存找了。
CPU各级缓存与内存速度到底差多少?
我们来简单地打个比方:如果CPU在L1一级缓存中找到所需要的资料要用的时间为3个周期左右,那么在L2二级缓存找到资料的时间就要10个周期左右,L3三级缓存所需时间为50个周期左右;如果要到内存上去找呢,那就慢多了,可能需要几百个周期的时间。
CPU缓存命中率
CPU需要找的内容,80% 都可以从L1中找到,剩余的20%可以在L2、L3、以及内存中找到,为什么会有如此高的一个概率,就是因为局部性原理在起作用。
缓存命中率在PHP7优化的应用
大家都知道PHP5升级到PHP7有着至少2倍的性能提升,其实在优化中,并没有用到非常先进的技术,完全是在细节处的把握,这里我主要讲到3点,
1、PHP7的变量底层结构zval,有着更加的精妙的结构,更少的内存占用。
2、数组底层结构HashTable也是更少的内存占用,而且会为每个Bucket单独分配空间,这样的弊端如下:
- 内存分配总是低效的,而且每次还额外需要分配8/16个字节,这是内存分配的冗余。分开分配也意味着这些buckets会分布在内存空间的不同地址中。
- Zvals也需要分开分配。上面已经说明这种方式很低效,它也会产生一些额外的头开销冗余(header overhead)。另外这需要在每个bucket中保存一个指向zval结构的指针,由于老的实现过于考虑通用性,所以不止需要一个指针,而是两个指针。
- 双向链表中的每个bucket需要4个指针用于链表的连接,这会带来16/32个字节的开销,遍历这种链表也不利于缓存(cache-unfriendly)操作。
PHP7的数组结构不仅拥有更加精简的HashTable结构。而且采用arData数组保存了所有的buckets(也就是数组的元素),另外有一个数组做hash对应数据数组的下标。
这样PHP7的HashTable除了有更低的内存,而且拥有更紧凑的内存结构。
以上更低的内存占用和更紧凑的内存结构,都是为了更高的CPU缓存命中率。
3、除此之外,在执行器层面还有一个非常重要的优化,execute_data、opline采用寄存器变量存储,执行器的调度函数为execute_ex(),这个函数负责执行PHP代码编译生成的ZendVM指令,在执行期间会频繁地用到execute_data、opline两个变量,在PHP5中,这两个变量是有execute_ex()通过参数传递给各指令handler的,在PHP7中不再采用传参的方式,而是将execute_data、opline通过寄存器来进行存储,避免传参导致的频繁出入栈操作,同时,寄存器相比内存的访问速度更快,这使得PHP的性能有了5%左右的提升。
寄存器是离CPU最近的存储结构,拥有比一级缓存还要快的速度。
局部性原理在MySQL的应用
MySQL索引采用的数据结构是B+Tree,其结构采用如下:
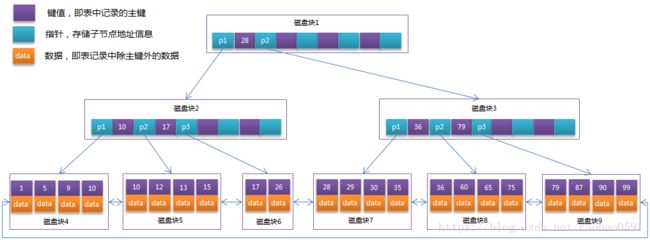
树的每个节点占用一个页的磁盘空间,InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗^3)。也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录。
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在2~4层。mysql的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1~3次磁盘I/O操作。
为什么使用B+Tree?
红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-/+Tree作为索引结构,这一节将结合计算机组成原理相关知识讨论B-/+Tree作为索引的理论基础。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。下面先介绍内存和磁盘存取原理,然后再结合这些原理分析B-/+Tree作为索引的效率。
局部性原理与磁盘预读
索引一般以文件形式存储在磁盘上,索引检索需要磁盘I/O操作。与主存不同,磁盘I/O存在机械运动耗费,因此磁盘I/O的时间消耗是巨大的。
因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据就是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
B-/+Tree索引的性能分析
从使用磁盘I/O次数评价索引结构的优劣性:根据B-Tree的定义,可知检索一次最多需要访问h个结点。数据库系统的设计者巧妙的利用了磁盘预读原理,将一个结点的大小设为等于一个页面,这样每个结点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:
每次新建结点时,直接申请一个页面的空间,这样可以保证一个结点的大小等于一个页面,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根结点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出读d是非常大的数字,通常超过100,因此h非常小。
综上所述,用B-Tree作为索引结构效率是非常高的。
而红黑树结构,h明显要深得多。由于逻辑上很近的结点(父子结点)物理上可能离得很远,无法利用局部性原理。所以即使红黑树的I/O渐进复杂度也为O(h),但是查找效率明显比B-Tree差得多
page cache与Kafka
关于Kafka的一个灵魂拷问:它为什么这么快?
有很多文章已经对这个问题给出了回答,但本文只重点研究其中的一个方向,即对page cache的使用。先简单地认识一下Linux系统中的page cache。 该小节出自kafka:https://www.jianshu.com/p/92f33aa0ff52
page cache出现的目的是为了加速数据I/O:写数据时首先写到缓存,将写入的页标记为dirty,然后向外部存储flush,也就是缓存写机制中的write-back(另一种是write-through,Linux未采用);读数据时首先读取缓存,如果未命中,再去外部存储读取,并且将读取来的数据也加入缓存。操作系统总是积极地将所有空闲内存都用作page cache,当内存不够用时也会用LRU等算法淘汰缓存页,page cache能够有效,依然是局部性原理的应用。
在kafka中如何运营page cache 呢?我们通过下面一张图来看:
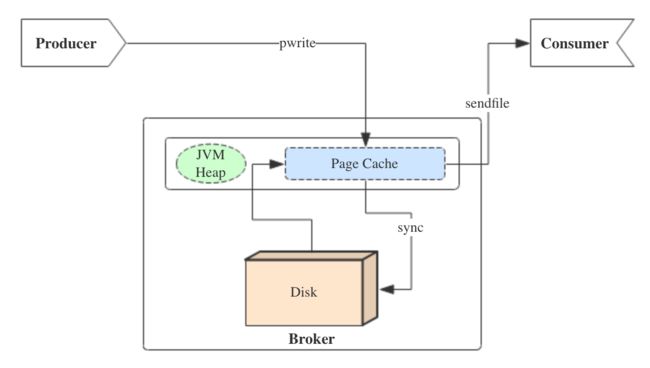
producer生产消息时,会使用pwrite()系统调用【对应到Java NIO中是FileChannel.write() API】按偏移量写入数据,并且都会先写入page cache里。consumer消费消息时,会使用sendfile()系统调用【对应FileChannel.transferTo() API】,零拷贝地将数据从page cache传输到broker的Socket buffer,再通过网络传输。
图中没有画出来的还有leader与follower之间的同步,这与consumer是同理的:只要follower处在ISR中,就也能够通过零拷贝机制将数据从leader所在的broker page cache传输到follower所在的broker。
同时,page cache中的数据会随着内核中flusher线程的调度以及对sync()/fsync()的调用写回到磁盘,就算进程崩溃,也不用担心数据丢失。另外,如果consumer要消费的消息不在page cache里,才会去磁盘读取,并且会顺便预读出一些相邻的块放入page cache,以方便下一次读取。
由此我们可以得出重要的结论:如果Kafka producer的生产速率与consumer的消费速率相差不大,那么就能几乎只靠对broker page cache的读写完成整个生产-消费过程,磁盘访问非常少。这个结论俗称为“读写空中接力”。并且Kafka持久化消息到各个topic的partition文件时,是只追加的顺序写,充分利用了磁盘顺序访问快的特性,效率高。