飞桨深度学习学院零基础深度学习7日入门-CV疫情特辑学习笔记(二)DAY01 新冠疫情可视化
本课分为理论和实战两个部分。
理论:图像识别与人工智能.pdf
1.图像识别定义和问题
理想目标:让计算机像人一样理解图像
实际目标举例:让计算机将语义概念相似的图像划分为同一类别
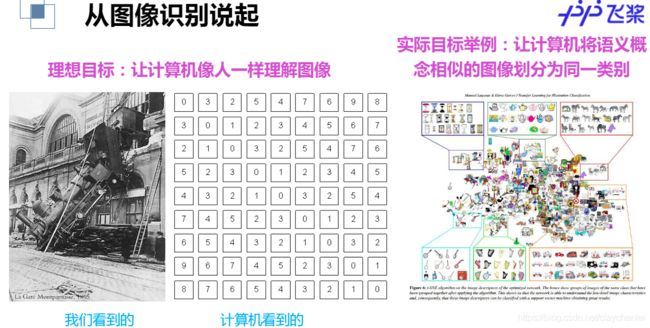
面临的难题:语义鸿沟 Semantic Gap: the gap between low-level visual features and high-level concepts(图像的底层视觉特性和高层语义概念之间的鸿沟)Ø例如:相似的视觉特性(color, texture, shape,...) ,不同的语义概念,简单的就是对人来说是包含丰富信息的图像,对计算机来说是由数字组成的多维数据。
2.传统图像识别方法
早起图像识别:特征提取---->索引技术---->相关反馈--->重排序
全局特征提取:用全局的视觉底层特性统计量表示图像(颜色、形状、纹理),原图片的各种特征通过向量空间映射形成向量。
索引技术:KD-Tr e e , L S H ( L o c a l i t y Sensitive Hashing),二进制哈希减少了特征存储的空间,以及特征相似度计算的复杂度
问题:过于关注全局特征,丢掉了图像细节
中期图像识别:特征提取---->向量化---->索引技术---->后处理
3.人工智能发展历程
人工智能(Artificial Intelligence,AI)是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新技术科学。简单来说就是使一部机器像人一样进行感知、认知、决策、执行的人工程序或系统。

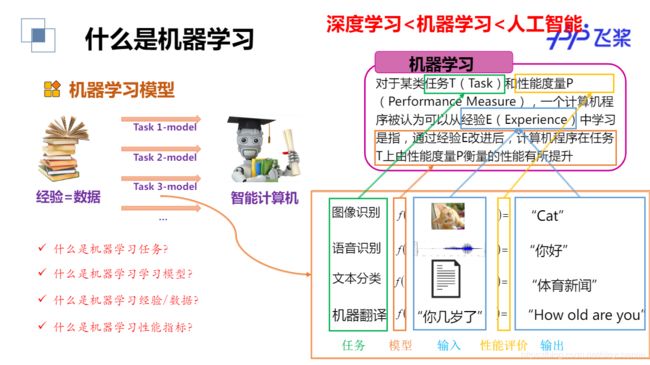
基于深度学习的图像识别
任务描述:输入图像像素,通过深度学习网络处理,输出分类结果,识别是猫还是狗。
深度学习应用:自动驾驶,人脸识别,语音识别,下棋对弈,影像识别,对话机器人等。
实战:新冠疫情可视化-基础版
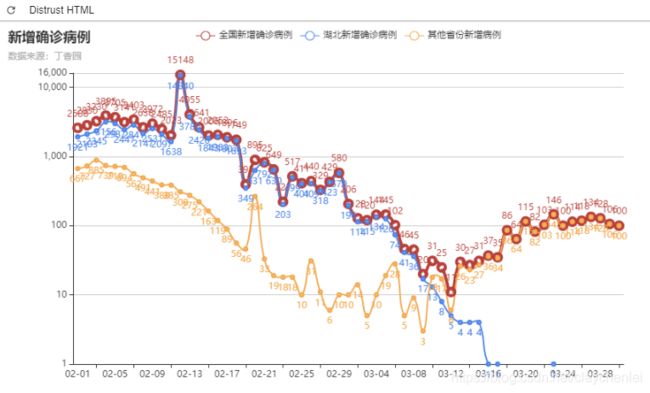
可视化,是一种利用计算机图形学和图像处理技术,将数据转换成图像在屏幕上显示出来,再进行交互处理的理论、方法和技术。本次实践基于丁香园公开的统计数据,实现新冠疫情可视化,包括疫情地图、疫情增长趋势图、疫情分布图等。
学习方法:
1.直接在百度AI Studio中阅读案例代码,并运行,查看结果
老师基本上逐行讲解代码,注释很到位,理解上没问题。Python爬虫代码网上一大批一大批的,自己之前也接使用过,抓取某东的分期商品信息特好使。
总体过程描述:模拟浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 提取有用的数据 --> 保存到本地/数据库。
爬虫的过程:
1.发送请求(requests模块)
2.获取响应数据(服务器返回)
3.解析并提取数据(re正则)
4.保存数据
使用到的模块:json,re,requests,datetime
新的知识点就是pyecharts,之前只用过echarts,配置选项和图像显示美观方面浪费了不少时间。
关于pyecharts:
使用 options 配置项,在 pyecharts 中,一切皆 Options。
主要分为全局配置组件和系列配置组件。
(1)系列配置项 set_series_opts(),可配置图元样式、文字样式、标签样式、点线样式等;
(2)全局配置项 set_global_opts(),可配置标题、动画、坐标轴、图例等;
放图:



2.由线上导出ipynb格式文件,导入到本地jupyterLab环境
一般来说,我喜欢在固定的工作目录工作学习,所以需要更改jupyter默认的工作路径。
在CMD或者Anaconda Prompt终端中输入下面命令,如果没有则生成,查看你的notebook配置文件在哪里:
jupyter notebook --generate-config
根据你运行实际显示的路径,推荐sublime或notepad++软件打开这个配置文件,默认工作目录为C:\Users\用户\.jupyter\jupyter_notebook_config.py,找到c.NotebookApp.notebook_dir 更改为自己的workfolder。
此外多说一句强烈推荐一个便捷小工具,utools,类似mac系统的launchpad ,稍微配置符合自己的习惯,工作学习小助手,谁用谁知道。

本地运行后同样得到以上疫情图。
3.进行部分参数调整,思考会有何变化,查看结果
todo: 展示全球疫情患者人数前10的国家柱形图,词云图等
配套参考资料:1.百度深度学院课程课件 2.Python机器学习教程 3.pyecharts
https://aistudio.baidu.com/aistudio/projectdetail/350434
http://gallery.pyecharts.org/#/WordCloud/basic_wordcloud