第一单元作业总结
·程序结构分析
第一次作业
思路
第一次作业为简单表达式的求导,其因子可分为两类,分别为常数和幂函数。数据的形式十分简单,可以两个用两个BigInterger来表示,所有数据都可归一化为<系数,指数>的形式,其中指系数和指数可以通过正则表达式进行提取。由于对面向对象的理解还不够深入,加之数据种类过于单一,故依然采用了面向过程的编程方式,仅仅将程序拆分成了读入、处理、输入三个类。
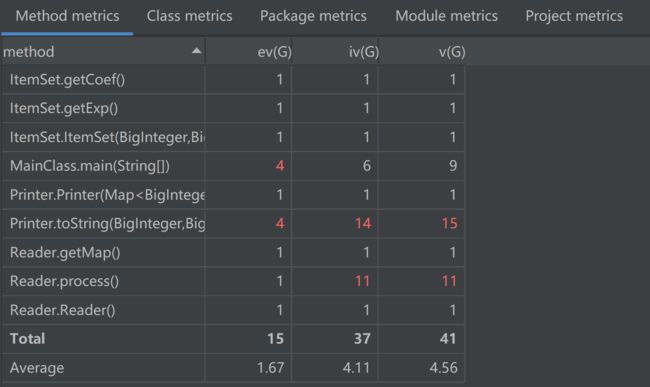
方法矩阵
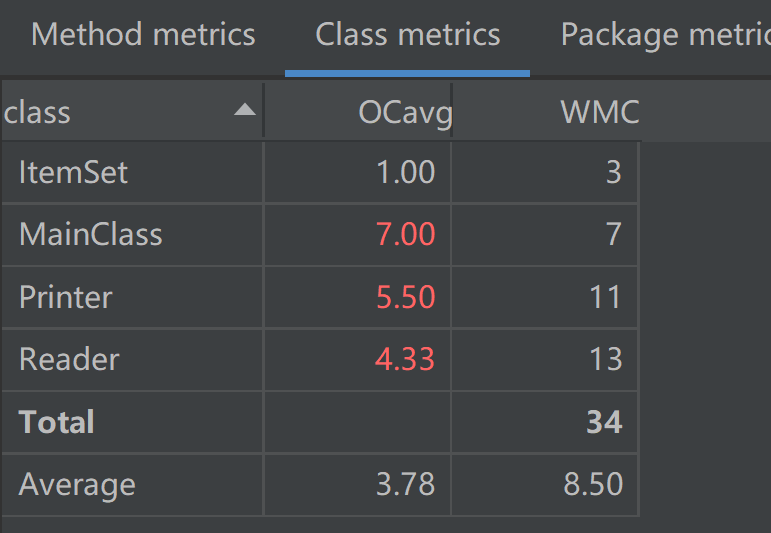
类矩阵
UML类图
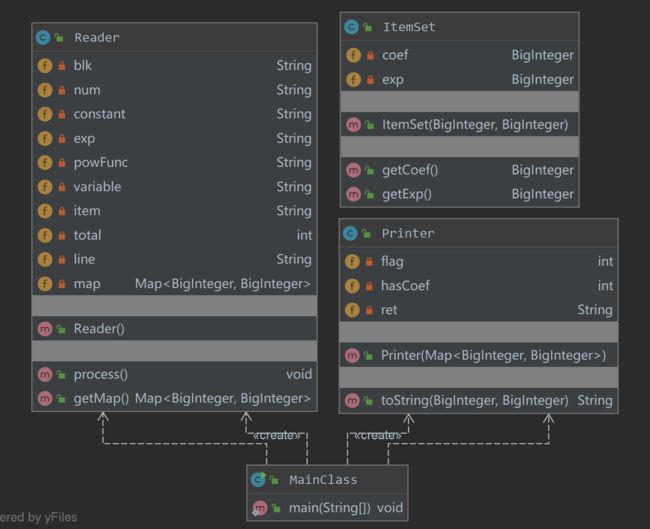
由图看见,由于采用的是面向过程的编程方法,因此main、reader、printer这个类普遍存在着高基本复杂度、高模块设计复杂度、高圈复杂度的问题。这代表着,三个模块难以分割、难以修改、路径复杂的问题,是典型的面向过程编程方式
第二次作业
思路
第二次作业,输入数据加入了sin和cos函数,故总共有常数、幂函数、sin、cos四种数据形式。面对多种数据形式,我决定尝试采取更加面向对象的编程方式。在第一次的基础上,首先通过正则表达式对输入数据进行格式判断,随后进行数据的预处理,以及数据的提取。由于数据的特殊性,我采用了ax**bsin(x)c*cos(x)d的四元组记录数据,并在四元组类内增加了求导的方法,进一步增加了数据的内聚性,并降低了耦合度,解决了第一次作业中数据存储与数据方法分离的问题。
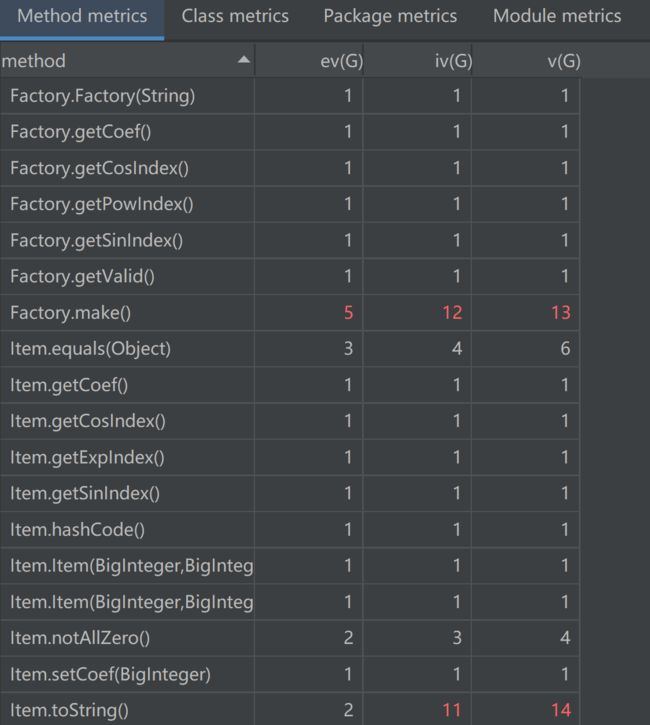
方法矩阵
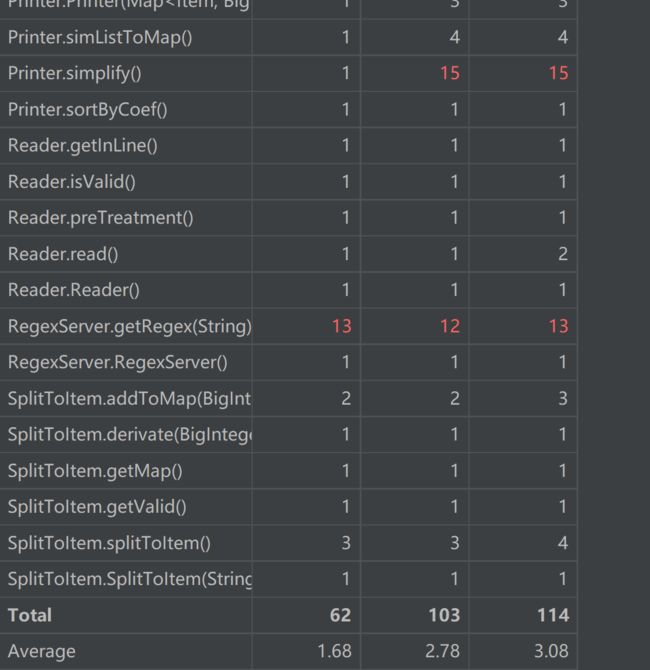
类矩阵
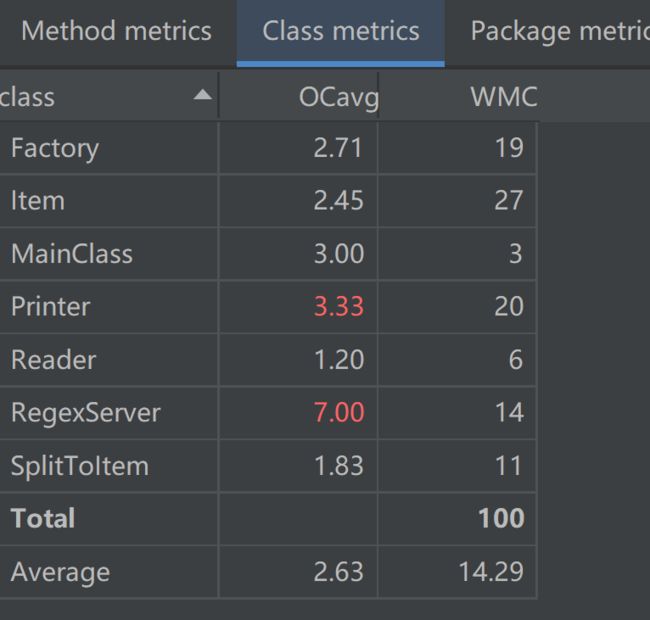
UML类图
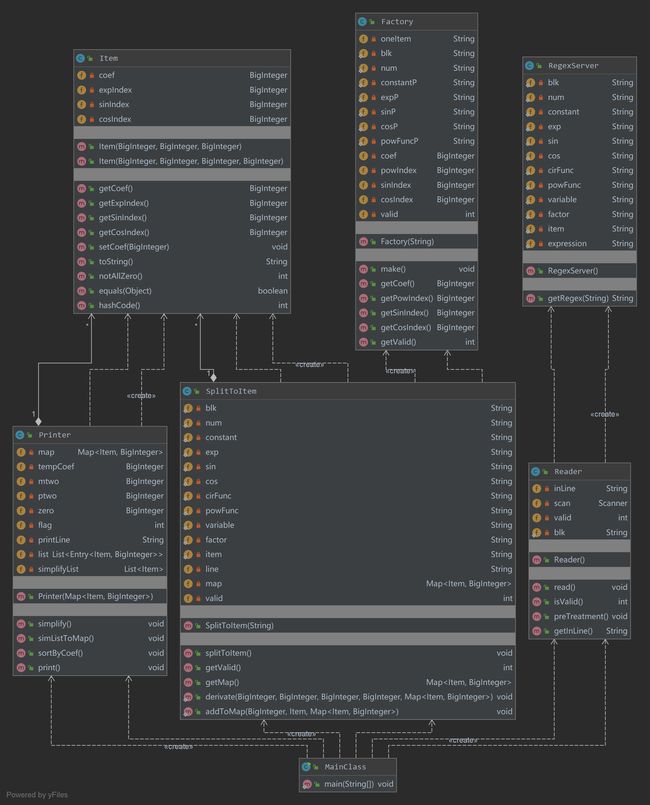
由上图可见,程序整体的基本复杂度、模块设计复杂度、圈复杂度别第一次作业显著降低,我的编程思想也逐渐由面向过程转向了面向对象。但是程序中依然存在着“肿块”,如RegexServer。建立RegexServer的本意是集中管理程序中用到的正则表达式,但是从中取出正则表达式的过程过于繁琐,导致其基本复杂度过高。
第三次作业
思路
第三次作业加入了嵌套等操作,这对程序的设计复杂度和圈复杂度有极大的要求,因为糟糕的设计可能会导致程序陷入多层嵌套,导致TLE。除此之外,第三次作业我们无法再像第二次作业一样轻松使用正则表达式对格式进行判断,只能采取“分而治之”的思想,但这又让我们不可避免地使用嵌套来处理。故如何处理好嵌套,在嵌套的过程中化简、优化是这次作业的一大挑战。
方法矩阵
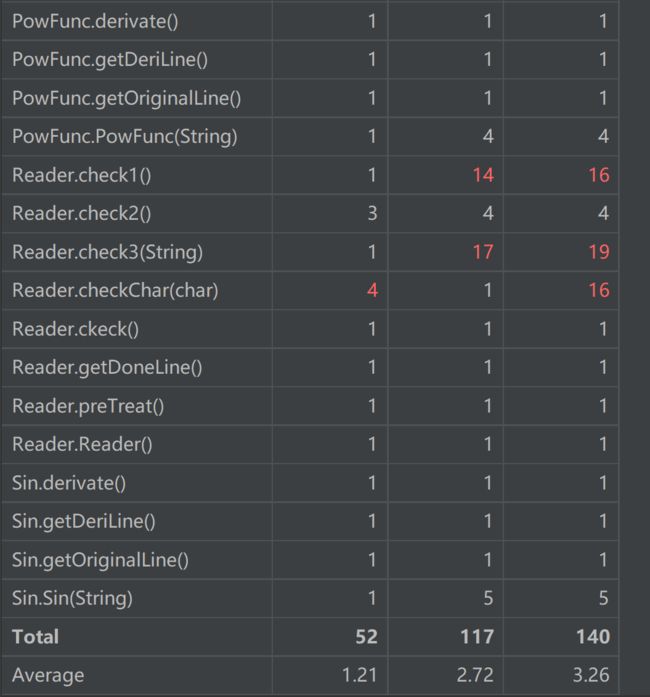
类矩阵
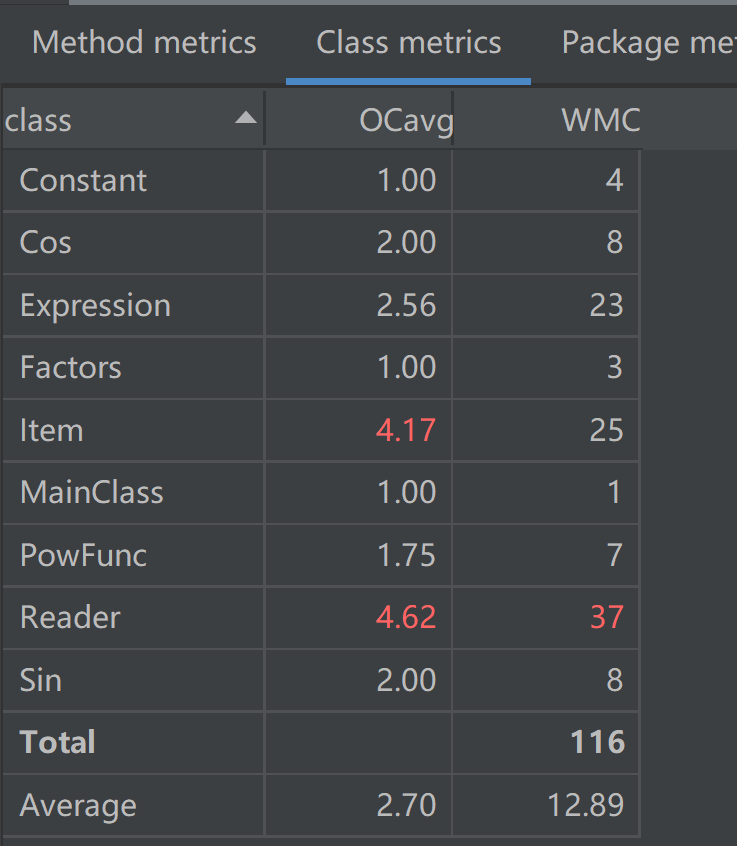
UML类图
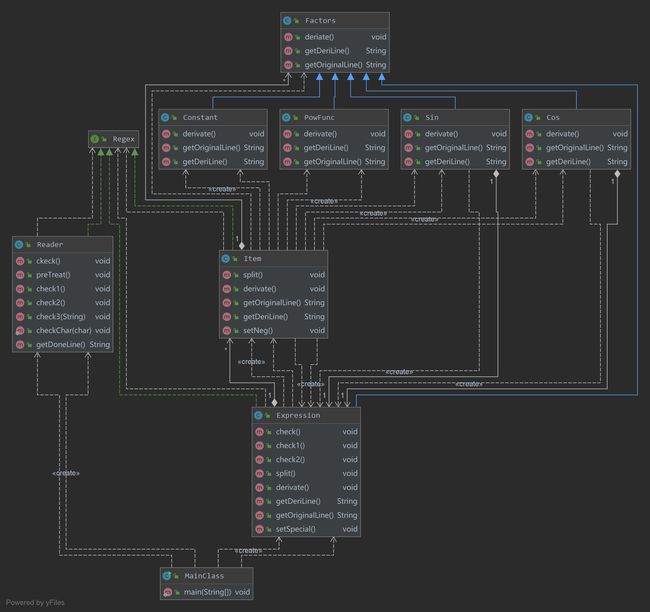
由上图可见,程序整体的基本复杂度、模块设计复杂度、圈复杂度较低,较好的实现了高内聚、低耦合的要求,但是Reader类中同样存在问题。由于在进行格式检查的时候选择了递归检测的方式,因此Reader部分的设计复杂度、圈复杂度较高,需要进一步优化
·程序中出现的bug
前两次作业中无bug,但是由于严重低估了第三次作业的复杂度,以及将过多的经历花在了冯如杯答辩、奖学金申请和OS上,导致急匆匆地编写第三次作业的代码,导致了大量的bug,最终未能通过中测。这对我来说试一次非常惨痛的教训,我一定会吸取教训,统筹规划好时间。
第三次作业中的bug
递归的格式检测
由于编写代码时过于匆忙,在检查格式时,仅仅检测了最外层的格式,忽略了sin和cos内部的格式,从而出现了bug。
修改项:
1.取缔了之前错误地检测函数,使之失能
2.将Reader中的检测改为递归检测,即步骤为替换最外层括号、格式检测、提取最外层括号内部的表达式,递归调用check函数再次检测
cos求导的bug
编写代码的时候由于时间紧迫,我将写好的sin方法直接复制到了cos下,并且只进行了变量相应的替换,忽略了toString的字符串中存在的需要替换的字符,因此导致cos求导会出现错误。
由表达式创建项的bug
bug原因:
在由表达式生成项时,首先考虑了该项前面的符号,若是符号,则将Item内部的negFlag置为1(程序规定,如果某一项的negFlag为1,则在输出其求导的字符串时,在其后*-1)。在匹配完符号后,利用正则表达式捕获组将该项所对应的字符串送入项,进一步分解。
这样的做法存在问题,例如,当某个表达式为x*x-5x**2+sin(x)时,程序会发现-5*x**2这一项,并且捕获符号,将其negFlag置为1,与此同时-5*x**2被送入Item类进行分解。Item在对其进行分解时,会将其分解为-5和x**2,这样一来,“负号”就被统计了两次,造成了计算错误
修改项:
1.有表达式创建项时,根据项前符号进行了分类讨论,避免了负号被统计两次的情况
·刀人策略
采用手动+自动生成的策略。
1.首先手写测试数据,主要测试边界情况。例如:-+1、-++x、cos(x)**-50等
2.其次进行自动生成数据的覆盖测试,尽可能多的找到问题
3.阅读代码,重点分析其他同学的优化算法在,找出他们的逻辑上的漏洞
事实证明,1和3中出现的bug最多,因为这部分的逻辑比较复杂,细节处理上稍有不慎就会出现问题
(补充手写数据的策略:我认为测试的目标在于用尽量少的测试测出尽量多的bug,我觉得有类似如何在一个数组中尽快找出我们想要的那一个元素,所以我的策略如下。将测试数据分为三组,第一组采用二分法的思想,尽可能多的遍历这个程序的逻辑通路;第二组测试数据主要测试程序对边界值的应对。在有前两次的基础的情况下,第三组数据更有针对性地测试程序已经出现bug的部分,并在已有bug的周边进行定点爆破。根据二八定律,bug往往比较集中,因此我觉得这样能够尽可能地测出程序的bug)
·应用对象创建模式来重构
为了解决程序的机构问题以及更深刻地理解面向对象的思想,我决定对三次程序进行重构
第一次作业
针对第一次作业面向过程的编程方式,我决定将数据的存储与方法合并在一个类中,并对输入进行预处理,从而简化提取逻辑,减小程序的设计复杂度
方法矩阵
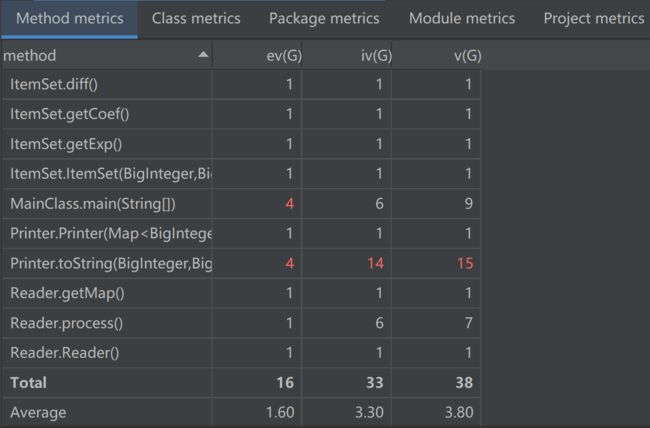
类矩阵
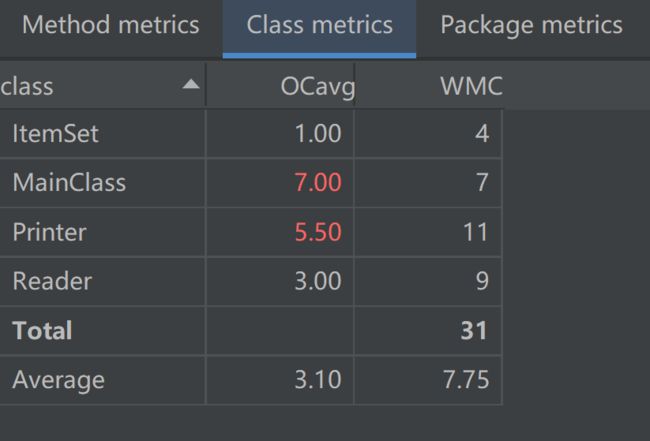
UML类图
经过优化ev、iv、v降低4%、19.7%、16.7%
OCavg、WMC降低18%、8%
第二次作业
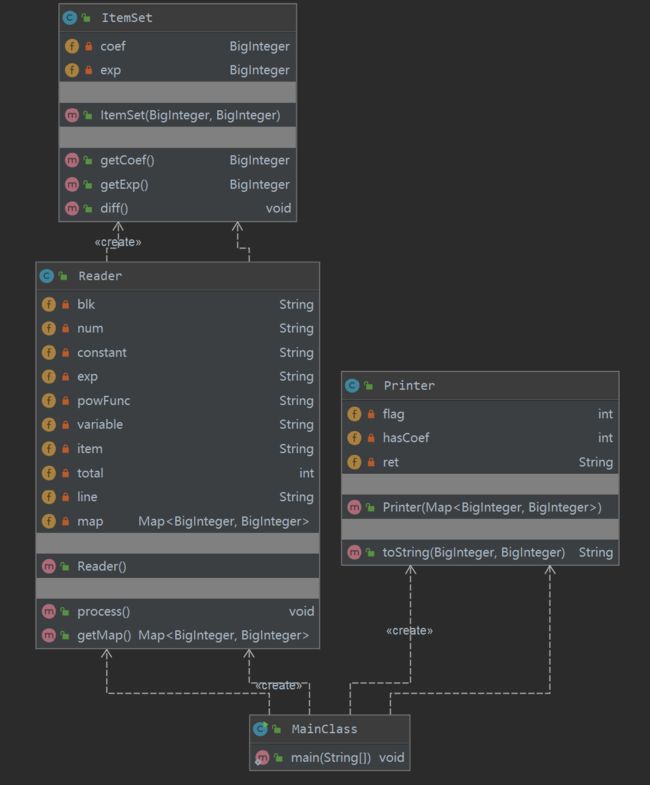
第二次作业主要针对Regex进行了重构,通过将RegexServer由实体类改为了接口,实现了数据的共享,同时还不会影响Reader继承和实现其他类或接口的能力
方法矩阵
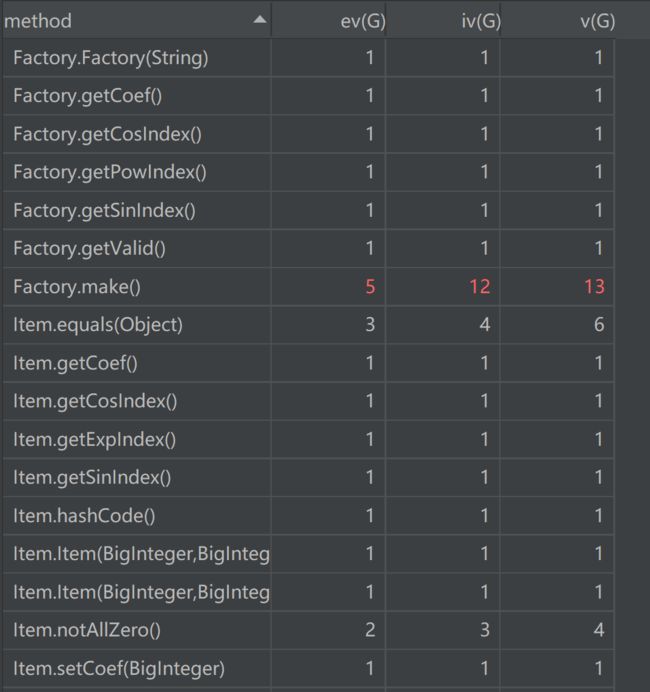

类矩阵
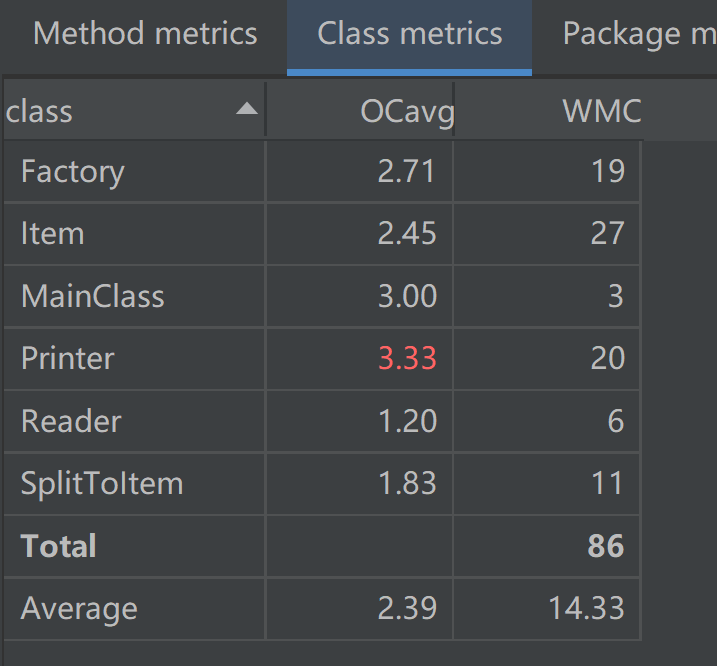
UML类图
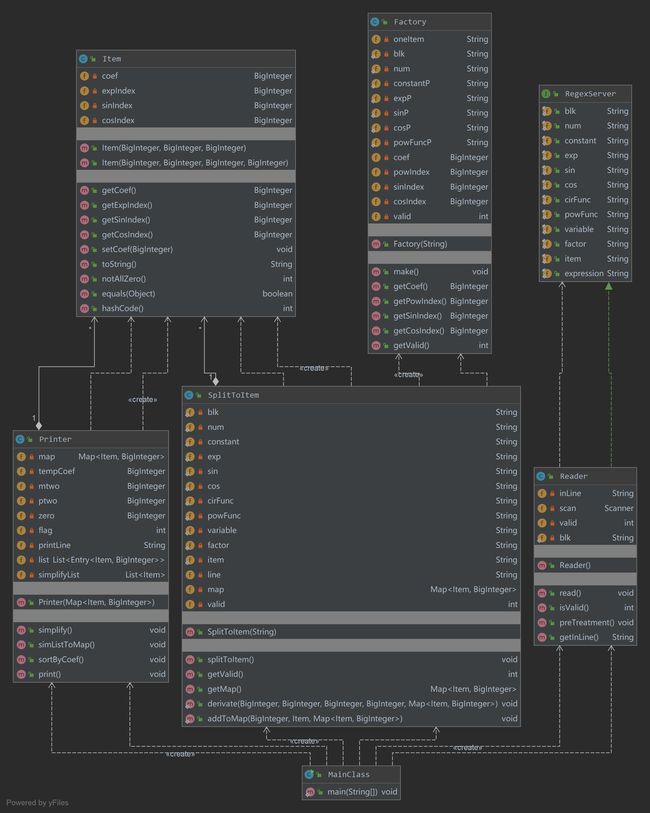
经过优化ev、iv、v降低18.4%、7.5%、7.1%
OCavg、WMC降低9.1%、-0.002%
由此,重构有效降低了程序的复杂度,进行了解耦,降低了此后修改程序所带来的风险
第三次作业
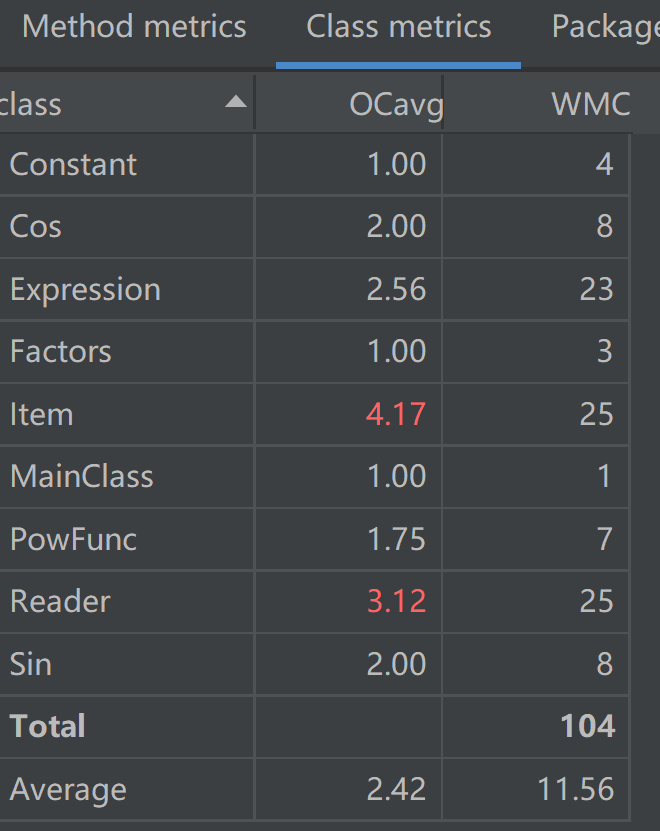
针对此前Reader“肿块”的问题对其内部进行了大量的优化,合并了重复的代码,以更简单的逻辑实现了格式的检测。除此之外,还利用工厂模式对Item类的求导方法进行了优化,如此一来,Item类的逻辑变得十分简单,并且实现了细节与功能的分离。
方法矩阵
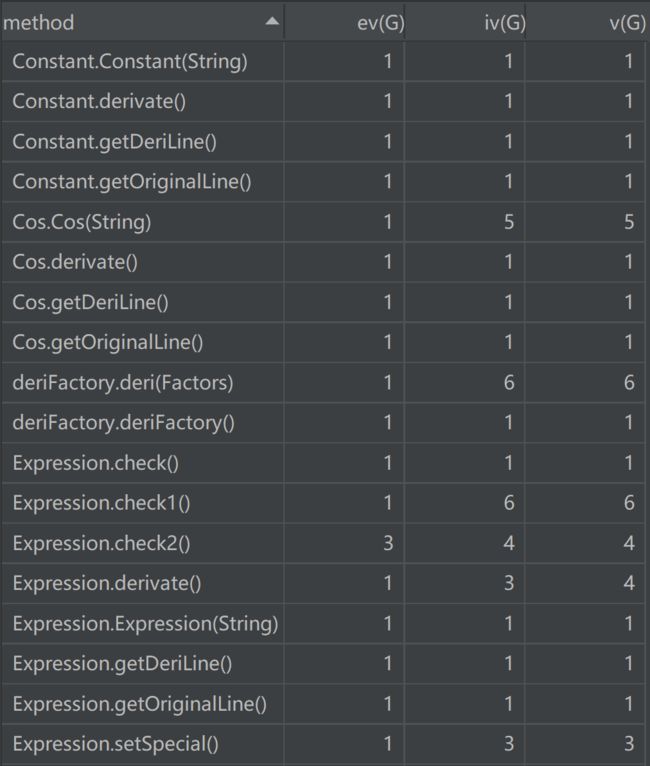

类矩阵
UML类图
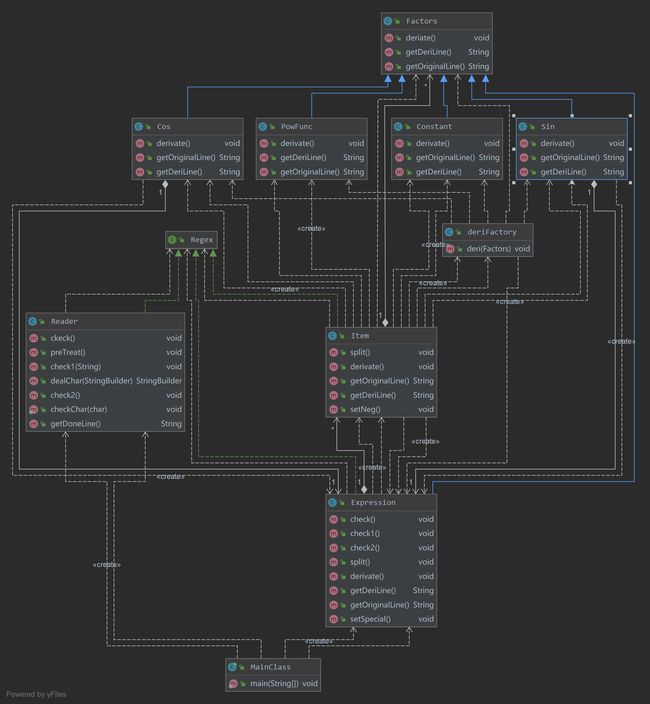
经过优化ev、iv、v降低0.8%、15%、14.7%
OCavg、WMC降低10.3%、10%
·对比和心得体会
面向过程的缺点:
代码的内聚程度低、耦合程度高,改一个小功能往往需要改好多个地方,一旦漏改一处,就会导致严重的问题。
重构的意义:
重构不单单是让代码变得更加易懂、好看,而是同时将相似的代码整合到了一切,并且给自己二次思考的机会。如果在将来需要修改代码,那么需要修改的位点往往比较集中,不会出现顾此失彼的问题,并且二次思考有助于减少问题出现的概率。例如,如果我在一开就对第三次作业的Reader进行重构,那么我就不会出现只检测了在外层格式,而没检测内层格式的bug了(原因是两份检测代码十分相似,我在调试的过程中只改了外层代码的细节,而忽略后内层检测。如果我当初把二者整合到一处,那么我只改一个地方就可以完成bug的修复)
工厂模式的使用:
试用工厂模式可以极大地改善代码的“外观”,不会让我们找某段代码找半天。一旦有了工厂,并且认识到问题出在创建对象的过程中,那么很容易,去工厂里改就完事了。在我目前看来,工厂是进一步提高内聚、降低耦合的手段。