十一、MapReduce中的InputFormat
MapReduce执行过程可以分为Map和Reduce,而在Map过程中,有个很重要的部分是InputFormat,本文主要介绍InputFormat。关注专栏《from zero to hero(Hadoop篇)》查看相关系列的文章~
目录
一、 切片与MapTask并行度
二、FileInputFormat切片
三、CombineTextInputFormat切片
四、FileInputFormat的实现类
4.1 TextInputFormat
4.2 KeyValueTextInputFormat
4.2.1 KeyValueTextInputFormat示例
4.3 NlineInputFormat
4.3.1 NlineInputFormat示例
4.4 自定义InputFormat
4.4.1 自定义InputFormat示例
一、 切片与MapTask并行度
(1)一个Job的Map阶段并行度由客户端在提交Job时的切片数决定。(2)每一个Split切片分配一个MapTask并行实例处理。(3)默认情况下,切片大小=blocksize。(4)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片。
二、FileInputFormat切片
切片机制:(1)简单的按照文件的内容长度进行切片。(2)切片大小,默认等于Block大小。(3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片。
可以通过以下代码获取切片信息:
//获取切片的文件名称
String name = inputSplit.getPath().getName();
//根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit) context.getInputSplit();三、CombineTextInputFormat切片
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。CombineTextInputFormat切片用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中。这样多个小文件就可以交给一个MapTask处理,从而提高处理效率。虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值,设置方法如下:
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);//设置切片最大值为4M切片机制:生成切片过程包括虚拟存储过程和切片过程两部分。
1、虚拟存储过程:将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
2、切片过程:判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
四、FileInputFormat的实现类
FileInputFormat常见的接口实现类包括:TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat。
4.1 TextInputFormat
TextInputFormat是默认的FileInputFormat实现类。按照行读取每条记录。键是存储该行在整个文件中的起始字节偏移量,LongWritable类型。值是这行的内容,不包括任何行终止符,Text类型。
4.2 KeyValueTextInputFormat
KeyValueTextInputFormat每一行均为一条记录,被分隔符分割为key,value。可以通过在驱动类中设置conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "\t");来设定分隔符,默认分隔符为\t。此时的键是每行排在制表符之前的Text序列。
4.2.1 KeyValueTextInputFormat示例
1、首先来看一下数据与需求。数据如下图所示,现在要求统计每行第一个单词相同的行数。

2、编写Mapper类
package com.xzw.hadoop.mapreduce.keyvaluetextinputformat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/7/29 14:19
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class KVTextMapper extends Mapper {
//1、设置value
private LongWritable v = new LongWritable(1);
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
//写出
context.write(key, v);
}
}
3、编写Reducer类
package com.xzw.hadoop.mapreduce.keyvaluetextinputformat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/7/29 14:19
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class KVTextReducer extends Reducer {
LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
long sum = 0L;
//1、汇总统计
for (LongWritable value:values) {
sum += value.get();
}
v.set(sum);
//2、输出
context.write(key, v);
}
}
4、编写Driver驱动类
package com.xzw.hadoop.mapreduce.keyvaluetextinputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/7/29 14:19
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class KVTextDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"e:/input/xzw.txt", "e:/output"};
Configuration configuration = new Configuration();
//设置分隔符
configuration.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "\t");
//获取job对象
Job job = Job.getInstance(configuration);
job.setJarByClass(KVTextDriver.class);
job.setMapperClass(KVTextMapper.class);
job.setReducerClass(KVTextReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
//设置输入格式
job.setInputFormatClass(KeyValueTextInputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
5、测试结果

4.3 NlineInputFormat
如果使用NlineInputFormat,代表每个map进程处理的InputSplit不再按Block块去划分,而是按NlineInputFormat指定的行数N来划分。即输入文件的总行数除以N等于切片数,如果不能整除,切片数等于商加一。这里的键和值与TextInputFormat一致。
4.3.1 NlineInputFormat示例
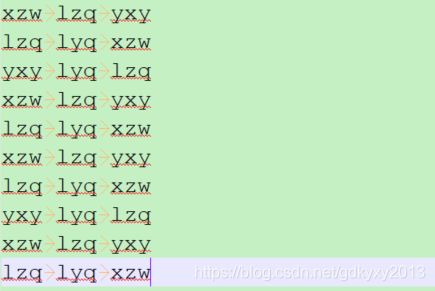
1、需求和数据:数据内容如下所示,需求是统计每个单词出现的次数,三行数据放入到一个切片中。
2、编写Mapper类
package com.xzw.hadoop.mapreduce.nlineinputformat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/1 11:05
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class NLMapper extends Mapper {
private Text k = new Text();
private LongWritable v = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、获取一行数据
String line = value.toString();
//2、切分数据
String[] fields = line.split("\t");
//3、写出
for (int i = 0; i < fields.length; i++) {
k.set(fields[i]);
context.write(k, v);
}
}
}
3、编写Reducer类
package com.xzw.hadoop.mapreduce.nlineinputformat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/1 11:12
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class NLReducer extends Reducer {
LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
long sum = 0L;
//1、汇总
for (LongWritable value: values) {
sum += value.get();
}
v.set(sum);
//2、写出
context.write(key, v);
}
}
4、编写Driver类
package com.xzw.hadoop.mapreduce.nlineinputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/1 11:12
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class NLDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"e:/input/xzw.txt", "e:/output"};
//1、获取job对象
Job job = Job.getInstance(new Configuration());
//2、设置每个切片InputSplit中划分三条记录
NLineInputFormat.setNumLinesPerSplit(job, 3);
//3、使用NLineInputFormat处理记录数
job.setInputFormatClass(NLineInputFormat.class);
//4、设置相关jar包
job.setJarByClass(NLDriver.class);
job.setMapperClass(NLMapper.class);
job.setReducerClass(NLReducer.class);
//5、设置Mapper和Reducer输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//6、设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//7、提交job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
5、测试结果如下所示

输出的切片数量为:

4.4 自定义InputFormat
在实际开发过程中,Hadoop框架自带的InputFormat类型并不能满足所有的业务场景,有时需要自定义InputFormat来解决相应的问题。自定义InputFormat首先需要定义一个类继承FileInputFormat,然后改写RecordReader,实现一次读取一个完整文件封装为KV,最后在输出时使用SequenceFileOutputFormat输出合并文件。
4.4.1 自定义InputFormat示例
1、需求:SequenceFile文件是Hadoop用来存储二进制形式的kv对的文件格式,现在需要将多个小文件合并成一个SequenceFile文件,存储的形式为文件路径+名称作为key,文件内容为value。文件是如下的三个小文件:

2、自定义RecordReader类
package com.xzw.hadoop.mapreduce.inputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/1 13:34
* @desc: 自定义RecordReader类
* @modifier:
* @modified_date:
* @desc:
*/
public class CombinerRecordReader extends RecordReader {
private Configuration configuration;
private FileSplit fs;
private FSDataInputStream inputStream;
private boolean isProgress = true;
private BytesWritable value = new BytesWritable();
private Text key = new Text();
/**
* 初始化方法,框架会在一开始的时候调用一次
*
* @param inputSplit
* @param context
* @throws IOException
* @throws InterruptedException
*/
public void initialize(InputSplit inputSplit, TaskAttemptContext context) throws IOException,
InterruptedException {
//转换切片类型到文件切片
fs = (FileSplit) inputSplit;
//通过切片获取路径
Path path = fs.getPath();
//通过路径获取文件系统
configuration = context.getConfiguration();
FileSystem fileSystem = path.getFileSystem(configuration);
//开流
inputStream = fileSystem.open(path);
}
/**
* 读取下一组KV值
*
* @return 如果读到了,返回true;如果读完了,返回false
* @throws IOException
* @throws InterruptedException
*/
public boolean nextKeyValue() throws IOException, InterruptedException {
if (isProgress) {
//读key
key.set(fs.getPath().toString());
//读value
byte[] buf = new byte[(int) fs.getLength()];
inputStream.read(buf);
value.set(buf, 0, buf.length);
isProgress = false;
return true;
} else {
return false;
}
}
/**
* 返回当前读到的key
*
* @return 当前key
* @throws IOException
* @throws InterruptedException
*/
public Text getCurrentKey() throws IOException, InterruptedException {
return key;
}
/**
* 返回当前读到的value
*
* @return 当前value
* @throws IOException
* @throws InterruptedException
*/
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
/**
* 当前数据读取的进度
*
* @return 当前进度
* @throws IOException
* @throws InterruptedException
*/
public float getProgress() throws IOException, InterruptedException {
return isProgress ? 0 : 1;
}
/**
* 关闭资源
*
* @throws IOException
*/
public void close() throws IOException {
IOUtils.closeStream(inputStream);
}
}
3、定义类继承FileInputFormat
package com.xzw.hadoop.mapreduce.inputformat;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/1 13:24
* @desc: 定义类继承FileInputFormat
* @modifier:
* @modified_date:
* @desc:
*/
public class CombinerFileInputFormat extends FileInputFormat {
/**
* 返回false,表示不可分割
* @param context
* @param filename
* @return
*/
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
/**
* 创建RecordReader对象
* @param inputSplit
* @param taskAttemptContext
* @return
* @throws IOException
* @throws InterruptedException
*/
public RecordReader createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
return new CombinerRecordReader();
}
}
4、编写Mapper类
package com.xzw.hadoop.mapreduce.inputformat;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/1 13:49
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class SequenceFileMapper extends Mapper {
@Override
protected void map(Text key, BytesWritable value, Context context) throws IOException, InterruptedException {
context.write(key, value);
}
}
5、编写Reducer类
package com.xzw.hadoop.mapreduce.inputformat;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/1 13:51
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class SequenceFileReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException,
InterruptedException {
context.write(key, values.iterator().next());
}
}
6、编写Driver驱动类
package com.xzw.hadoop.mapreduce.inputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/1 13:58
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class SequenceFileDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"e:/input", "e:/output"};
//1、获取job对象
Job job = Job.getInstance(new Configuration());
//2、设置jar包存储位置,连接自定义的Mapper和Reducer
job.setJarByClass(SequenceFileDriver.class);
job.setMapperClass(SequenceFileMapper.class);
job.setReducerClass(SequenceFileReducer.class);
//3、设置输入的InputFormat
job.setInputFormatClass(CombinerFileInputFormat.class);
//4、设置输出的Outputformat
job.setOutputFormatClass(SequenceFileOutputFormat.class);
//5、设置Mapper和Reducer的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(BytesWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
//6、设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//7、提交job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
7、测试结果如下所示

至此,本文就讲解完了,你们在这个过程中遇到了什么问题,欢迎留言,让我看看你们遇到了什么问题~