MySQL插入优化与requests连接池
最近工作比较忙,此外花了时间看杂书,文章写的比较少。
本篇文章分享一个工作中遇到的小问题。
背景
要完成一个开发任务,读取一个具有80w条数据的CSV文件,将其入库,因为CSV文件中缺少2个关键数据,需要通过调用内部Web API接口的形式去获得,2个参数分别请求两个URL,每次请求参数不同。
MySQL插入优化
先不考虑Web API方面的内容,80w条数据,如何快速的入库MySQL?
一个直观的想法就是将多条INSERT语句合并成一条INSERT执行,合并成一条SQL后,会减少MySQL的日志,从而降低日志的数据量与使用磁盘的评率,从而提高效率,此外合并SQL语句后,可以减少SQL语句的解析书以及减少网络传输IO(MYSQL C/S模式)
查阅资料,主要阅读了「MySQL 批量 SQL 插入性能优化」这篇文章,文中给出了相应的测试效果,这里分享一下。
多条插入数据
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
合并成一条后
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0), ('1', 'userid_1', 'content_1', 1);
文中提供一些测试对比数据,分别是进行单条数据的导入与转化成一条 SQL 语句进行导入,分别测试 1 百、1 千、1 万条数据记录。
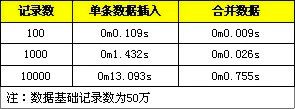
此外文中提出,使用事务可以提高数据的插入效率,其原因是因为MySQL在进行INSERT操作时内部会建立一个事务,在事务内才进行真正的插入处理,在使用INSERT语句时,直接使用事务可以减少多次创建事务的消耗。
使用事务的修改如下。
START TRANSACTION;
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
...
COMMIT;
文中同样给出了测试对比,分别是不使用事务与使用事务在记录数为 1 百、1 千、1 万的情况。
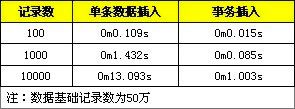
此外,还需要注意,插入数据时,其索引是有序的会比无序索引快那么一些。
数据有序的插入是指插入记录在主键上是有序排列。
例如 datetime 是记录的主键。
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('2', 'userid_2', 'content_2',2);
从上面sql可以看出,datetime是记录主键,但却是无序的。
将其修改成。
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('2', 'userid_2', 'content_2',2);
MySQL在进行入库操作时,需要维护索引数据,插入时,索引数据无序会增大维护索引的成本,因为MySQL索引使用的结构是B+树,这个树本文就不讨论先,留点素材给未来的自己。
下面是随机数据与顺序数据的性能对比,分别是记录为 1 百、1 千、1 万、10 万、100 万。

将上面提到的三种方式合起来使用,可以让INSERT语句执行效果大幅提高。
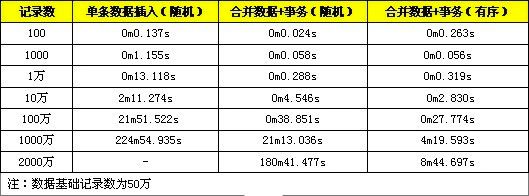
引用「MySQL 批量 SQL 插入性能优化」结论
从测试结果可以看到,合并数据 + 事务的方法在较小数据量时,性能提高是很明显的,数据量较大时(1 千万以上),性能会急剧下降,这是由于此时数据量超过了 innodb_buffer 的容量,每次定位索引涉及较多的磁盘读写操作,性能下降较快。而使用合并数据 + 事务 + 有序数据的方式在数据量达到千万级以上表现依旧是良好,在数据量较大时,有序数据索引定位较为方便,不需要频繁对磁盘进行读写操作,所以可以维持较高的性能。
因为我插入的数据其主键索引本身就是无序的,所以使用了「合并数据 + 事务」的方法,但在具体实践时,还是遇到了「(2006, “MySQL server has gone away (BrokenPipeError(32, ‘Broken pipe’))”)」这个问题。
阅读MySQL相关文档与其他资料,出现这个问题有3个可能原因。
1.max_allowed_packet值太小,在MySQL中max_allowed_packet默认为4M,即插入数据其大小不能超过4M,我要做的就是将其设置成更大的值。
// 查看 max_allowed_packet
>show VARIABLES like '%max_allowed_packet%';
// 将修改成 100M
>set global max_allowed_packet = 1024*1024*100;
这种修改只会临时生效,MySQL重启后,依旧会变为4M,想要长期生效,需要修改「my.ini」。
2.wait_timeout太小,MySQL链接长时间没有新请求,就被Server端关闭了,对于一些ORM库而言,这个过程是透明的,此时还在使用被Server端关闭的链接来进行SQL操作,就会出现上述错误,而我要做的就是将其设置为更大的值。
>show global variables like '%timeout';
// MySQL无操作28800秒后会被自动化关闭
> set global wait_time = 28800;
但这不是长久之策,因为长时间不操作,MySQL Server端依旧会将其关闭,这个问题依旧会出现,为了避免这个问题,你需要自己关闭链接,对于一些MySQL操作量不大的情景,建议使用短连接的形式,如果依旧需要用MySQL连接池,以长连接的方式来操作MySQL,就需要实现判断当前链接是否存活的逻辑并在不存活的情况下自动重连。
如果使用的是pymysql,那么可以通过ping()方法来进行重连,其源码如下。
def ping(self, reconnect=True):
"""Check if the server is alive"""
if self._sock is None:
if reconnect:
self.connect()
reconnect = False
else:
raise err.Error("Already closed")
try:
self._execute_command(COMMAND.COM_PING, "")
return self._read_ok_packet()
except Exception:
if reconnect:
self.connect()
return self.ping(False)
else:
raise
其实就是先判断当前链接是否存活,不存在就通过connect()方法再链接一次。
此外可以利用「try…except…」,当使用当前MySQL链接执行SQL时,如果报错,直接执行except中的逻辑,在except中只需将当前链接关闭,然后再获取新链接,然后再执行SQL则可。
3.此外执行大量数据的INSERT或REPLACE也可能会导致此类错误(这才是我遇到这个错误的原因),要做的就是降低单词INSERT的数据行数则可,我原本一次性插入10000条,将其改成5000条后,这个问题就没有出现了。
这个原因可以从其开发官方查阅到,地址为:https://dev.mysql.com/doc/refman/5.7/en/gone-away.html
支持,80w条数据高效插入的问题就解决了
requests连接池
MySQL入库方面的问题解决后,接着就来考虑一下requests问题,要实现23条请求,并发是必须的,键盘啪啪啪两三下,利用线程池(ThreadPoolExecutor)的并发请求逻辑就实现好了,一个经验是,将参数处理后,其他的事情就不用多想了,通过ThreadPoolExecutor.map()方法,轻松实现并发。
我以为事情就这样结束了,但程序正常运行一段时间后,出现了大量的「Cannot assign requested address」报错。
这是因为客户端短时间内频繁的请求服务器,每次请求链接都在很短的时间内结束,从而导致很多TIME_WAIT,操作系统的端口号等资源被迅速用光,新的请求链接没办法获得新的端口号等资源,就抛出Cannot assign requested address。
可以通过netstat -an | grep TIME_WAIT验证一下。
理解了问题所在,解决起来就很简单了,使用requests连接池就好了,实现端口号等资源的复用。
需要注意,这里请求的Web API是相同的2个API,所以可以通过建立长连接的方式复用资源,如果每次请求的host、IP等都不同,这种方式是没有什么效果的。
requests其实已经考虑到了连接池的情况,简单使用一下则可。
@staticmethod
def get_http_session(pool_connections=1, pool_maxsize=10, max_retries=3):
'''
http连接池
pool_connections 要缓存的 urllib3 连接池的数量。
pool_maxsize 要保存在池中的最大连接数。
max_retries 每个连接的最大重试次数
'''
session =requests.session()
# 创建适配器
adapter = requests.adapters.HTTPAdapter(pool_connections=pool_connections,
pool_maxsize=pool_maxsize, max_retries=max_retries)
session.mount('http://', adapter)
session.mount('https://', adapter)
return session
结尾
至此,这个东西就正常跑起来了。
大家在工作中有没有遇到什么有意思的问题?
如果本文对你有所启发,记得点击「在看」支持二两。
感谢「MySQL 批量 SQL 插入性能优化」https://segmentfault.com/a/1190000008890065
