使用Python编写RSS阅读器(一)
使用Python编写RSS阅读器(一)
最近想写一个Python的RSS阅读器。
先来了解一下什么是RSS。所谓的RSS,即Really Simple Syndication(真正简单的信息聚合),它使用规定的XML格式提供信息内容。你访问一个RSS信息源(例如,知乎每日精选,http://www.zhihu.com/rss),就可以得到一个XML文件。对于信息发布方来说,也很简单,只要每天在固定时间生成一下XML文件就可以了。
RSS技术非常简单,它是XML技术的一个封装,规范了信息的XML格式。
一、RSS文件格式
我抓取了腾讯国际新闻的RSS,http://news.qq.com/newsgj/rss_newswj.xml,内容如下:
新闻国际
新闻国际
http://news.qq.com
http://mat1.qq.com/news/rss/logo_news.gif
新闻国际
http://news.qq.com/world_index.shtml
Copyright 1998 - 2005 TENCENT Inc. All Rights Reserved
zh-cn
www.qq.com
-
意大利政党达成共识 推举54岁法学教授为总理人选
http://news.qq.com/a/20180522/001629.htm
www.qq.com
2018-05-22 05:05:14
意大利五星运动党领导人迪马约当地时间21日,意大利五星运动党和联盟党代表再次与总统马塔雷拉会见,呈交组阁计划和内阁初定人选,为联合组建新政府进一步扫清道路。经过连日密集的谈判磋商,双方就组阁各项事宜达成共识,联合组阁协议也分别在两党党内获得通过。当天,两党确认推举现年54岁的法学教授朱塞佩·康特(Giuse
-
美国务卿:美国将确保伊朗永远无法拥有核武器
http://news.qq.com/a/20180522/001182.htm
www.qq.com
2018-05-22 03:09:38
中新社华盛顿5月21日电美国国务卿蓬佩奥21日在华盛顿的美国传统基金会演讲,阐述美国在退出伊核全面协议后新的对伊战略。资料图:美国国务卿蓬佩奥。中新社记者邓敏摄今年3月8日,美国总统特朗普宣布美国将退出伊核全面协议,重启对伊制裁。蓬佩奥21日在演讲时表示,美国将继续与盟友合作,打击伊朗破坏该地区稳定的行为、
......
根据RSS2.0的规范,一个RSS的XML文件,其根节点是
- title:标题
- image:图片
- description:描述
- link:链接
- copyright:版权
- language:语言
- generator:生成者
一个
- title:标题
- link:链接
- author:作者
- category:分类
- pubDate:发布日期
- comments:备注
- description:描述
信息发布方每天会更新这个文件,所以如果你想建立自己的新闻数据库,只要每天抓取一次这个文件,将内容转存入自己的数据库即可。
我写了一个小程序用于抓取这个文件:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
import codecs
url = 'http://news.qq.com/newsgj/rss_newswj.xml'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.82 Safari/537.36'}
page = requests.get(url, headers=headers)
page.encoding = 'utf-8'
page_content = page.text
f = codecs.open('d:/news.txt', 'w', 'utf-8')
f.write(page_content)
f.close()二、Python解析RSS文件
从网络上抓取到RSS的XML文件后,通常需要解读它,然后将相应的部分转存入数据库系统,所以需要从XML文件中找出信息的相关内容。
在Python中解析RSS,我主要介绍两种方法。
1. 使用BeautifulSoup
解析HTML文件,BeautifulSoup是很好用的,它也可以解析XML文件。
在解析XML文件之前,先装一个lxml插件(pip install lxml),lxml是一种HTML/XML文件的解析器。
之后就可以使用BeautifulSoup解析文件了。
代码如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
import codecs
from bs4 import BeautifulSoup
url = 'http://news.qq.com/newsgj/rss_newswj.xml'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.82 Safari/537.36'}
page = requests.get(url, headers=headers)
page.encoding = 'utf-8'
page_content = page.text
soup = BeautifulSoup(page_content, 'lxml-xml') # 指定文件解析器为lxml
news = soup.select('rss > channel > item')
f = codecs.open('d:/news.txt', 'w', 'utf-8')
for i in range(len(news)):
f.write(u'标题:' + news[i].title.string + '\r\n')
f.write(u'内容:' + news[i].description.string + '\r\n')
f.write(u'链接:' + news[i].link.string + '\r\n\r\n')
f.close()2. 使用feedparser
先安装一下feedparser(pip install feedparser),feedparser专用于解析RSS格式的XML文件。
下面是一个命令行下的简单示范:
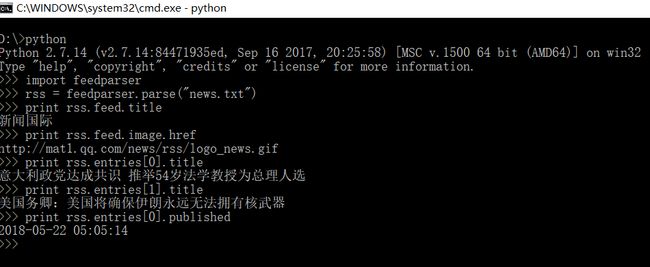
feedparser用起来很简单,首先调用feedparser.parse("news.txt")解析XML文件,得到解析结果之后,调用feed.title之类的方法可以得到
想了解feedparser的具体用法,请参考它的文档:https://pythonhosted.org/feedparser/。