RPC框架原理及实现
RPC概述
RPC(Remote Procedure Call)即远程过程调用,允许一台计算机调用另一台计算机上的程序得到结果,而代码中不需要做额外的编程,就像在本地调用一样。
RPC采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。
现在互联网应用的量级越来越大,单台计算机的能力有限,需要借助可扩展的计算机集群来完成,分布式的应用可以借助RPC来完成机器之间的调用。
RPC框架原理
在RPC框架中主要有三个角色:Provider、Consumer和Registry。如下图所示:
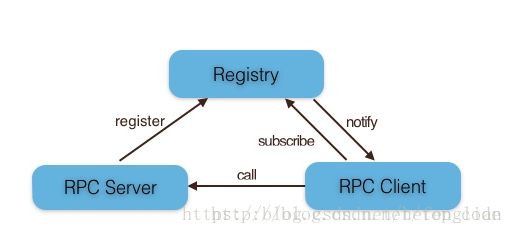
节点角色说明:
* Server: 暴露服务的服务提供方。
* Client: 调用远程服务的服务消费方。
* Registry: 服务注册与发现的注册中心。
RPC调用流程
RPC基本流程图:
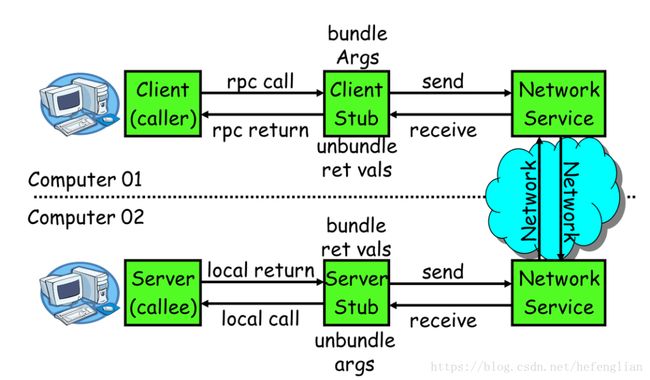
一次完整的RPC调用流程(同步调用,异步另说)如下:
1)服务消费方(client)调用以本地调用方式调用服务;
2)client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
3)client stub找到服务地址,并将消息发送到服务端;
4)server stub收到消息后进行解码;
5)server stub根据解码结果调用本地的服务;
6)本地服务执行并将结果返回给server stub;
7)server stub将返回结果打包成消息并发送至消费方;
8)client stub接收到消息,并进行解码;
9)服务消费方得到最终结果。
RPC框架的目标就是要2~8这些步骤都封装起来,让用户对这些细节透明。
或者:补充
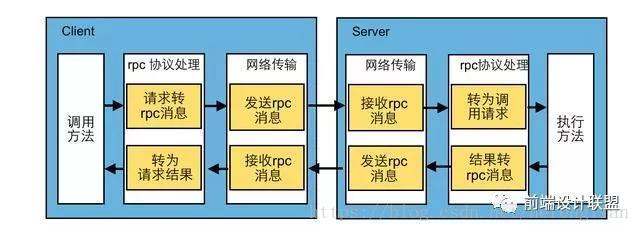
首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息的到达为止。
当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息。最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
hadoop、hbase等分布式体系结构就是构建在RPC之上的。简单的rpc调用过程如上图:
当Client调用远程的方法时,先将要调用的方法名、参数等信息按RPC协议转换为RPC消息,然后再通过某种传输协议(TCP、HTTP等)将RPC消息传输到Server端。
Server端接到请求后将RPC消息按协议转换为调用请求,并执行方法,将执行后的结果按类似的过程返回给Client端,完成一次RPC调用。
服务注册&发现
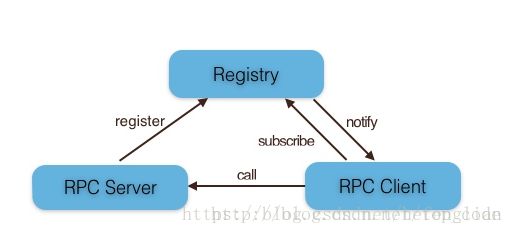
服务提供者启动后主动向注册中心注册机器ip、port以及提供的服务列表;
服务消费者启动时向注册中心获取服务提供方地址列表,可实现软负载均衡和Failover;
使用到的技术
1、动态代理
生成 client stub和server stub需要用到 Java 动态代理技术 ,我们可以使用JDK原生的动态代理机制,可以使用一些开源字节码工具框架 如:CgLib、Javassist等。
2、序列化
为了能在网络上传输和接收 Java对象,我们需要对它进行 序列化和反序列化操作。
* 序列化:将Java对象转换成byte[]的过程,也就是编码的过程;
* 反序列化:将byte[]转换成Java对象的过程;
可以使用Java原生的序列化机制,但是效率非常低,推荐使用一些开源的、成熟的序列化技术,例如:protobuf、Thrift、hessian、Kryo、Msgpack
关于序列化工具性能比较可以参考:jvm-serializers
3、NIO
当前很多RPC框架都直接基于netty这一IO通信框架,比如阿里巴巴的HSF、dubbo,Hadoop Avro,推荐使用Netty 作为底层通信框架。
4、服务注册中心
可选技术:
* Redis
* Zookeeper
https://www.w3cschool.cn/zookeeper/zookeeper_fundamentals.html
* Consul
* Etcd
开源的优秀RPC框架
阿里巴巴 Dubbo:https://github.com/alibaba/dubbo
新浪微博 Motan:https://github.com/weibocom/motan
gRPC:https://github.com/grpc/grpc
rpcx :https://github.com/smallnest/rpcx
Apache Thrift :https://thrift.apache.org/
参考
http://www.importnew.com/22003.html(*)
https://blog.csdn.net/top_code/article/details/54615853