- 第一次作业
- 思路
- 架构
- 复杂度分析
- Bugs
- 第二次作业
- 思路
- 架构
- 复杂度分析
- Bugs
- 第三次作业
- 思路
- 架构
- 复杂度
- 使用二叉树的优劣分析
- Bugs
- 关于评测机
- 心得体会
第一次作业
思路
表达式由各个项相加组成,每个项带有自己的符号,可正可负。第一次作业的项中只包含幂函数和常数项,所以项仅由系数和指数两个参数确定。项之间能否合并取决于x的指数,所以在表达式中采用HashMap来存储表达式中的各个项,指数作为key,方便同类项的查询。
依次确定数据结构:表达式中用HashMap存储各个项,项中包含两个属性:系数和指数。
架构
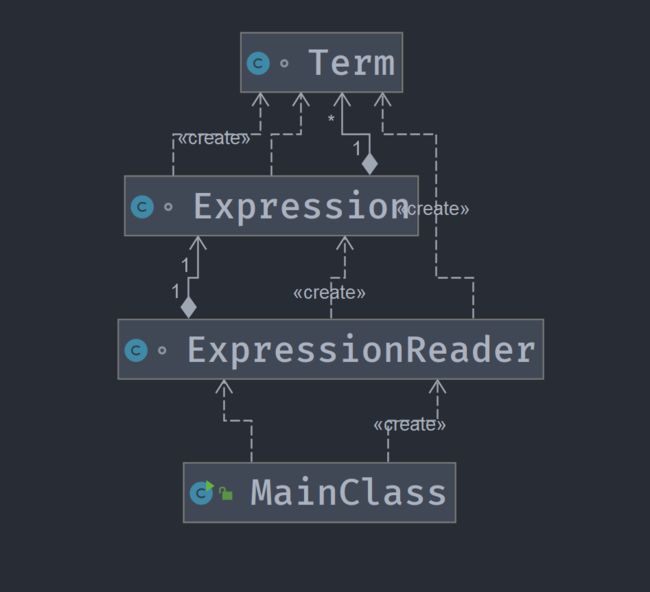
这次作业中只设计了4个类。MainClass中只包含程序的核心逻辑,main函数只有4行,所有工作交给其他类处理。ExpressionReader用于解析输入字符串并生成Expression。Expression中包含若干Term.
复杂度分析
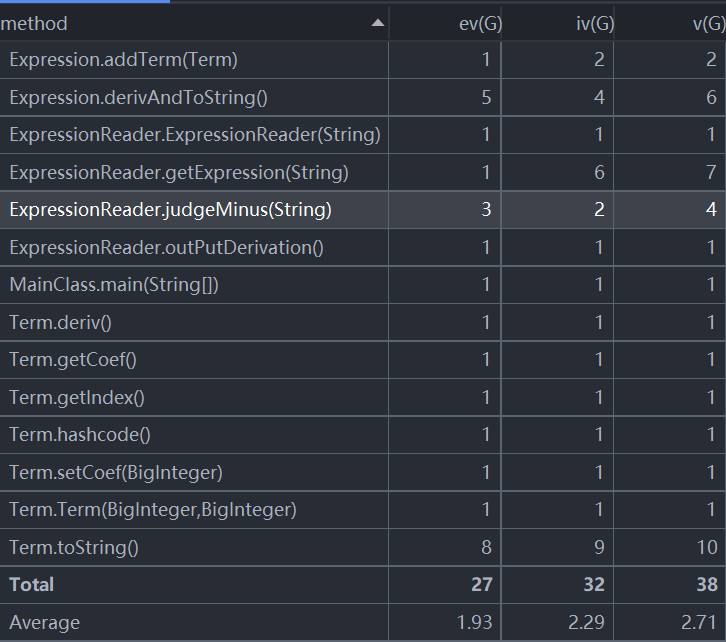
Term.toString()方法的结构化程度较高,也就是线性无关的独立路径较多。原因是这个方法中涉及到对于系数为0,+-1;指数为0,1情况的省略处理,包含了大量的if-else结构,所以独立路径较多。

作业1一共223行,主要逻辑集中在Expression中对输入的处理部分。
Bugs
本次作业在强测和互测中均未出现Bug。
第二次作业
思路
这次作业中项之间有了相乘关系,也增加了三角函数因子。这次作业的数据结构与作业一大体相同,项也是仅由一个项由指数和三个系数确定,所以项中只有指数和系数两个属性。表达式中仍然采用HashMap存储各个项,key是项的指数,也是为了便于查找同类项。这次作业中的指数采用一个新的类TermIndex来表示,它可以看作是由x,sin(x),cos(x)指数构成的三元组,便于指数的统一管理。
架构

与第一次作业不同的是,这次采用了三个解析类:ExpressionReader,TermReader,ItemReader.它们只包含一个方法,该方法的作用是输入字符串,解析并返回 表达式/项/因子。
ExpressionReader利用正则表达式发现了一个项之后,把这个表示项的子串交给TermReader处理;TermReader发现了一个因子之后,把这个表示因子的子串交给ItemReader解析。这样就完成了任务的向下分解。
最底层的ItemReader逻辑非常简单,只需要识别出因子的类别和相关信息(常数因子的值,或者其他因子的指数)即可。而上层的ExpressionReader和TermReader只需要把下层Reader返回的项/因子进行组合生成表达式/项,逻辑也很简单。
复杂度分析
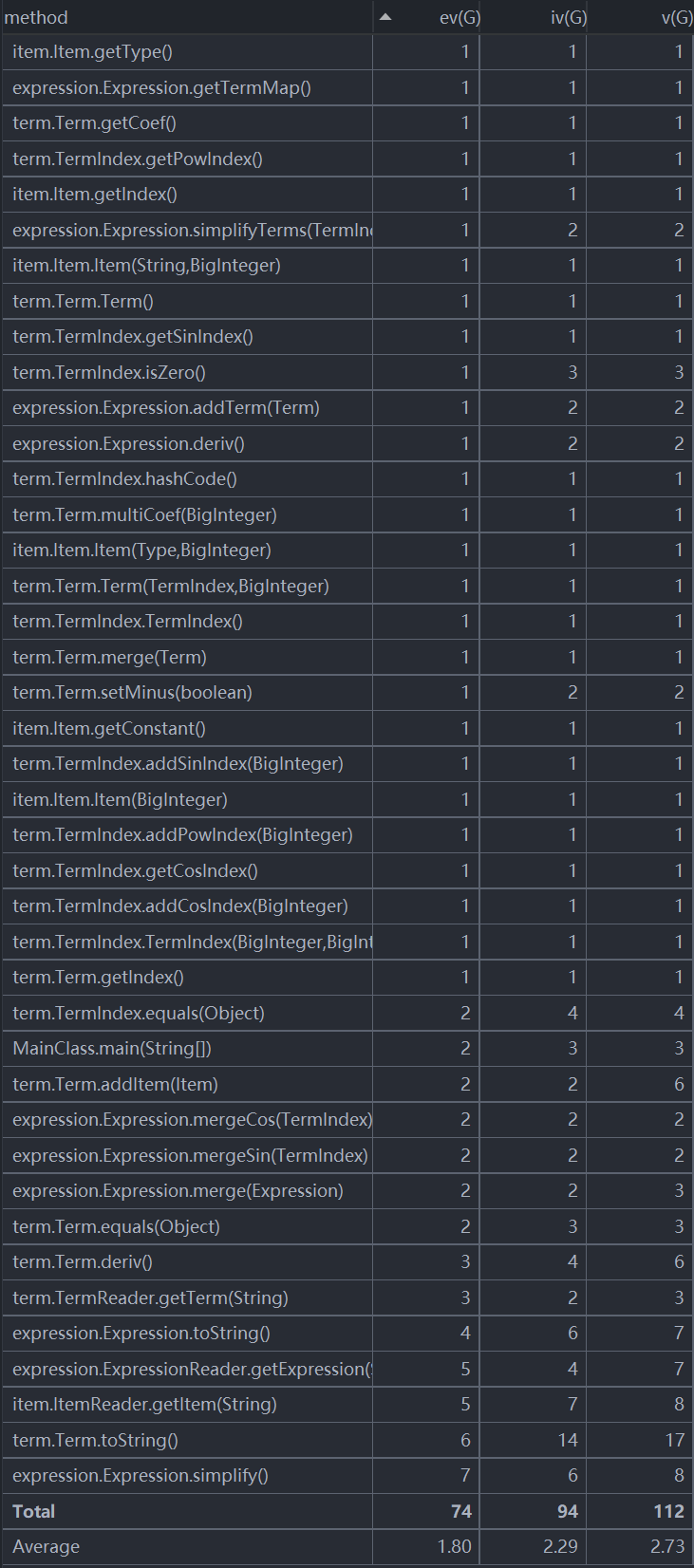
可以看出这次作业的平均复杂度不高,但是有部分方法的复杂度很高。比如和第一次作业相同的toString().这次作业中的化简用方法symplify()的结构化程度很高,原因是作业时间未能安排妥当,在DDL当天中午才开始写优化部分,导致写的很仓促,没有进行细致的思考,写出了一个纯面向过程的方法。

本次作业代码共597行,去除空白后523行
Bugs
本次作业优化之外的部分在动手之前做了较长时间的设计,没有出现BUG。但是优化部分由于写得仓促,测试不充分,导致强测和互测中都被发现了BUG。
BUG的原因是优化方法中流程控制错误,导致在一些情况中过早退出,使得优化后的新表达式缺少了一些本应该有的项。
第三次作业
思路
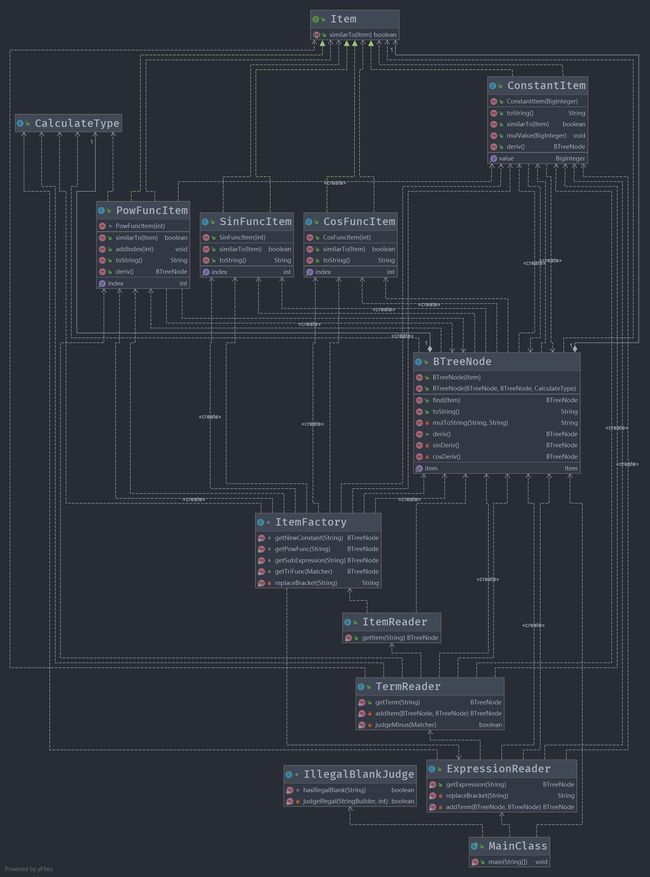
第三次作业发生了较大变化,因为加入了表达式因子,且三角函数中可以也嵌套表达式了。这个变化使得我需要对第二次作业进行重构,因为第二次作业中我用一个四元组表示项(系数,三个指数),但是这次的项中可以包含表达式,项不再能仅由几个数字确定了,所以表达式也不再能采用HashMap这个结构来存储项的信息了。所以这次作业中我重构了表达式的数据结构,使用二叉树来表示表达式。二叉树的叶子节点表示因子,非叶子节点表示运算(加,减,乘,嵌套)。
架构
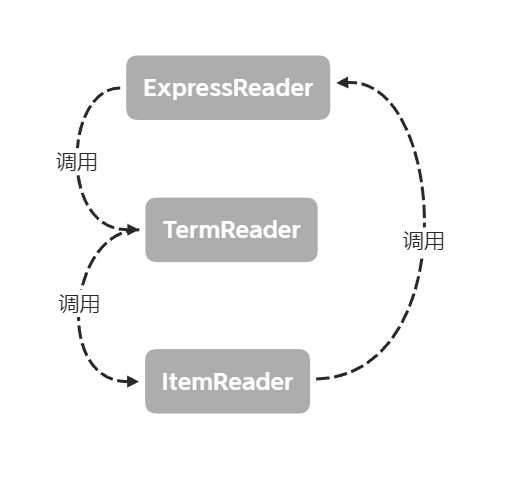
在解析方面沿用第二次作业的三个Reader将任务逐层分解的架构,由于因子可以是表达式,这次的ItemReader可以调用ExpressionReader,如下图:
其中由于因子出现了多种因子,我采用接口的方式管理四种因子类。因子的生成采用了工厂模式,详见下面的UML类图。
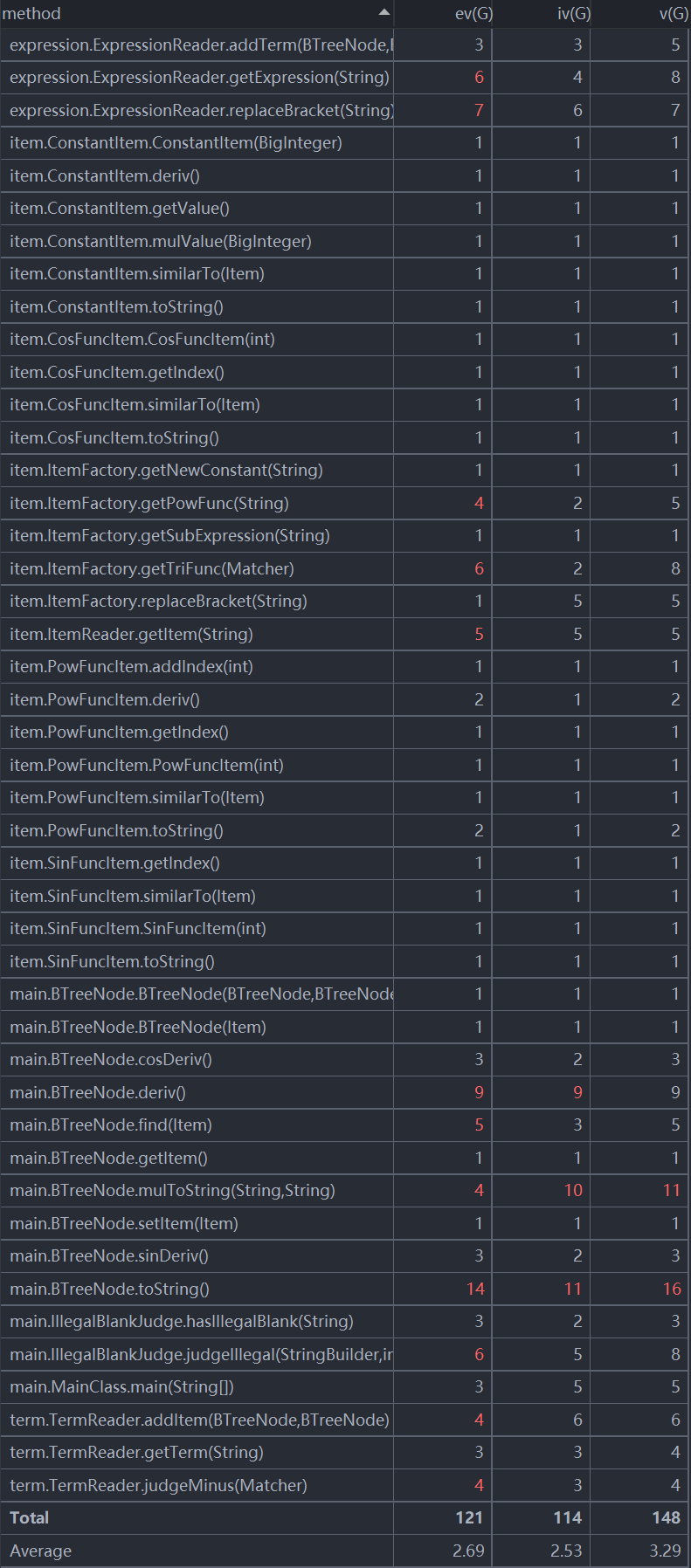
复杂度
下图是各类的复杂度:
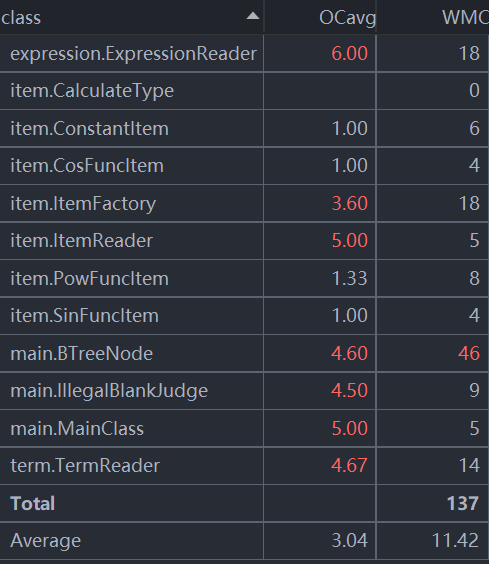
这次作业的难度有较大提升,复杂度方面相较上一次作业有较明显的提升。复杂度最大的方法仍然是toString()方法和因子解析用的方法ItemReader.getItem()下属的一些列方法,因为这两个方法涉及到了因子的多种不同的,但是并列的情况,所以出现了很多if-else结构。另外一个复杂度很大的方法是求导用方法deriv(),因为涉及到了对四种运算分别建模的操作。
使用二叉树的优劣分析
我在第三次作业中使用二叉树来的数据结构来存储表达式,与用List结构在功能上有一些不同。
优点:
- 方便对加,减,乘,嵌套四种运算进行建模,可以递归调用子节点的求导方法,符合我们现实应用中的求导步骤。比如:
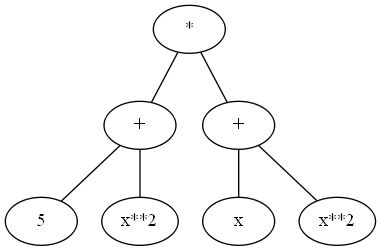
在对这个表达式进行求导的时候,只需根据调用根节点的求导方法,结果是leftChild.deriv() * rightChild + RightChild.deriv() * leftChild。至于子节点求导结果是什么,调用子节点的求导方法就可以了。
缺点 :
- 非常难以优化。因为用二叉树表示表达式增添了原本不存在的层次关系。比如
sin(x)**2 + 1 + cos(x)**2:
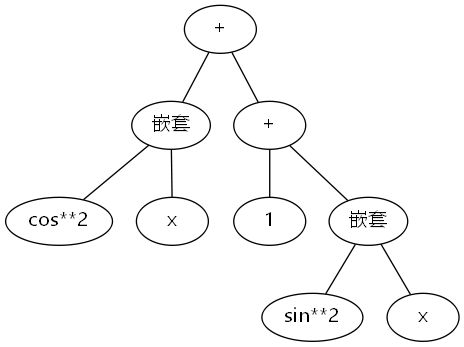
sin(x)**2和cos(x)**2很难搜索到彼此的存在,所以化简难度很高,我在本次作业中并没有对这种情况进行化简。
Bugs
这次作业中我在强测和互测中都被发现了TLE的Bug,原因是我在toString()方法中,本应分别调用一次leftChild.toString()和 rightChild.toString(),但是由于复制粘贴出现的失误,分别调用了两次,导致复杂度是正常的2的n次幂倍。
关于评测机
受启发于讨论区中一篇关于自动测试的帖子,我在第一次作业的时候用python和命令行搭建了自动评测机,原理是利用python的xeger库根据正则表达式随机生成测试数据,再利用sympy库对结果进行结算于比对。使用命令行重复运行pyhton脚本与java程序,利用重定向来传递数据,达到全自动测试的效果。
自动评测机的不足是生成的大部分数据都是普通数据,难以生成边界数据,所以对代码的静态检查对于debug仍然十分重要。
心得体会
- OO作业考验的不仅仅是我们面向对象的工程能力,还有时间管理的能力。随着作业难度的上升,单次作业占用的时间也越来越多,如果时间管理出了问题,在DDL前一两天才开始写的话,是几乎不可能写出高质量的作业的。
- 面向对象的设计确实与之前面向结构的设计思想有很大的不同。面向对象的设计中可以根据现实世界来建模,让我们的代码更加容易理解,也更容易发现bug。面向对象的设计中更重视对架构的设计,自己设计出了一个很满意的架构是一件很有满足感的事情。
- 见识到了同学们优秀的代码之后,更加深刻的认识到了自己和他人的差距,我仍然有很长的路要走。