Part 1 基于度量的分析
第一单元的作业内容是表达式求导,三次作业难度逐次增加。其中本人第二三次作业的结构类似,因此放在一起进行分析
第一次作业
UML图如图
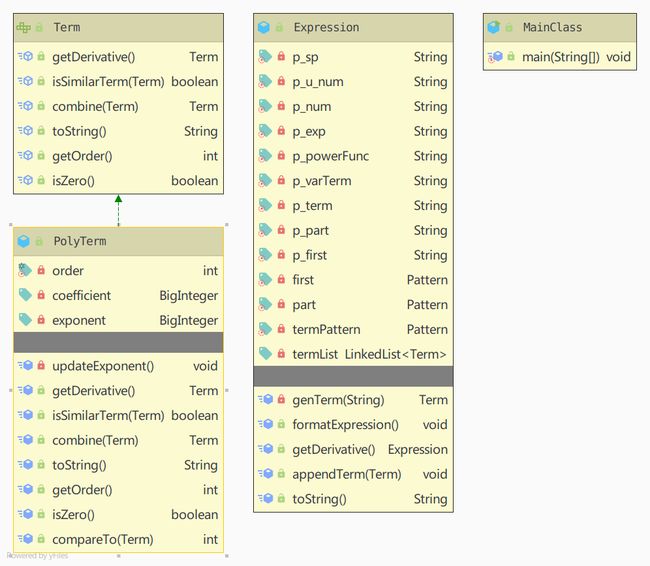
第一次作业项比较简单,可以归结为:仅有由幂函数(带系数和指数)组成的项。其中,为了可拓展性,我把项定义成为了一个接口。输入的解析由Expression类的Constructor和genTerm方法来完成,相关的正则也保存在Expression类中。Expression是一个列表中Term相加组成。求导方法按照求导规则生成新的表达式对象。
但事实上,我的实现效果现在细想来有很大问题,数据也佐证了这一点。
复杂度
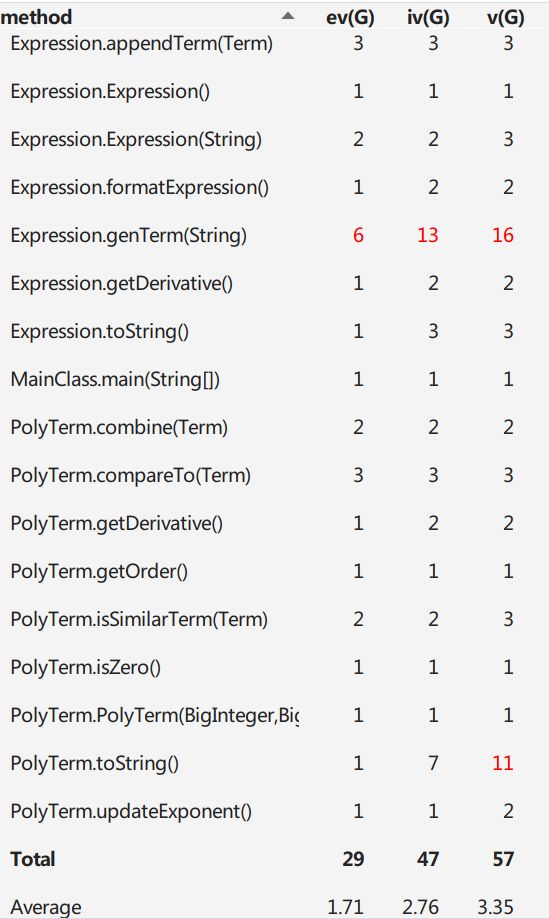
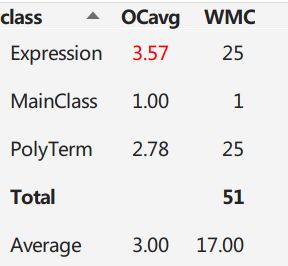
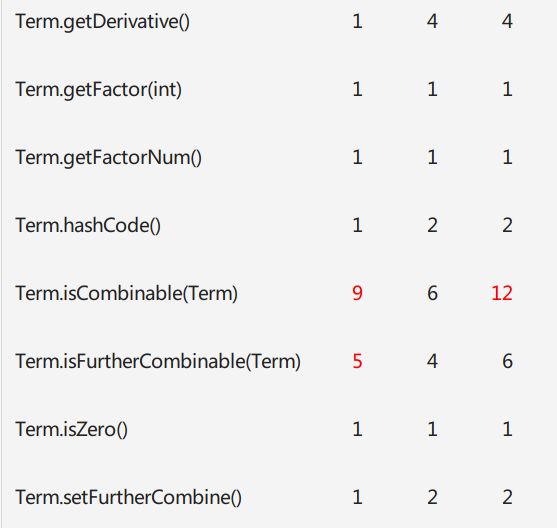
先看复杂度,ev,iv,v都是一个方法复杂度不同方面的度量,OCavg和WMC是一个类复杂度的度量。主要的值得警惕的地方(红色)很显然,就在Expression类的genTerm方法中。我在genTerm中使用了层次化构造的大正则,所以处理的代码要面对很多情况,造成了代码的复杂。
事实上,把正则、表达式生成放在Expression类中可以算是一个错误,Expression类明显因此变得过于复杂。
我目前想到的更合理架构是:采用工厂方法,ExpFactory作为一个类专门生成Expression;建立RegexExpression类,专门用来存放正则表达式。
依赖
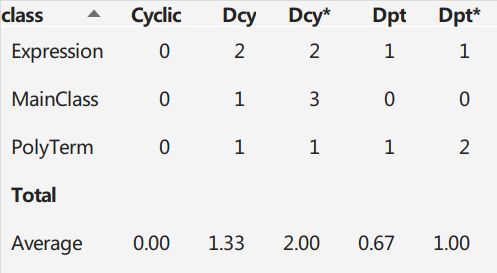
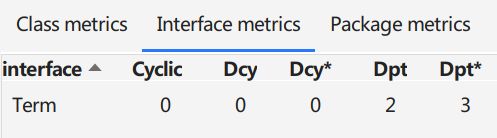
再看依赖关系,整体来说比较正常,我主要使用了接口,DIT是1.
从数据上看,第一次作业似乎问题只在Expression类上,但事实上,这个设计大有问题,这直接导致我第二周作业全盘推倒重来,几乎成为一个噩梦。
相信大家已经看出来了,幂函数更适合作为一个因子,而不是一个项。此外,还有一个关键的设计问题是,要不要把常数和幂函数分开。从第一次作业的角度来看,这两种方式差异不大,但是从后面的作业来看,分开&保证项里有常数是一个更好的选择,可以省去大量的判断,而且让各自的功能更专一,从后面的代码上看,幂函数是最复杂的一个,所以这样拆开也是一种很好的拆分。此外,保证项里有常数实际是一个很危险的操作,所以我实现时既保证了一定有常数,又预防了没有常数的情况。
DesigniteJava分析

DesigniteJava分析得到的结果是,我最大的bad smell是Unutilized Abstraction,很尴尬,我本来是照着可扩展性强的方向设计的,结果到最后反而是直接推倒重写了
第二、三次作业
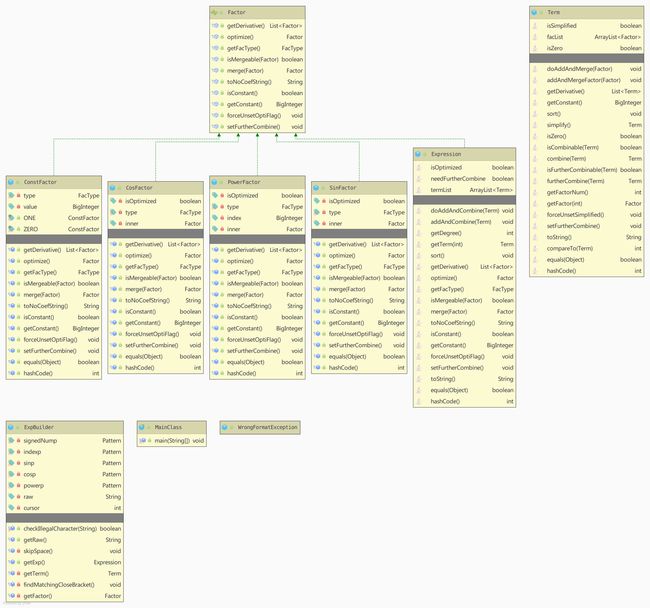
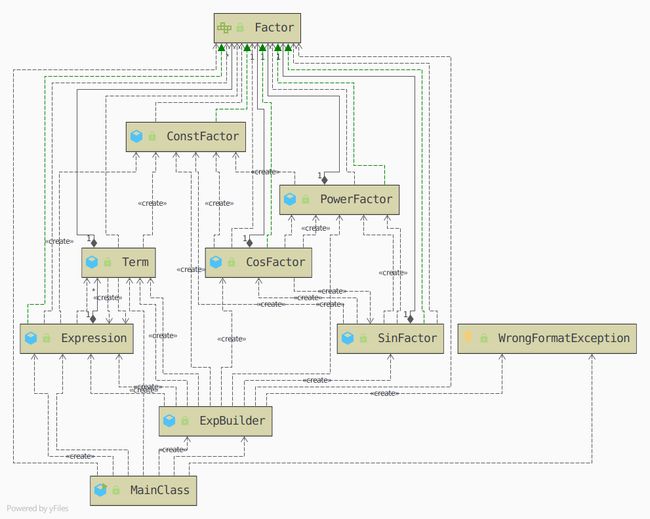
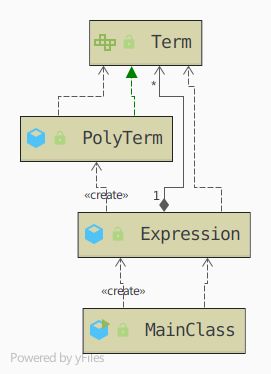
UML如图(第三次作业)
看上去可能有点乱,事实上,这是一个表达式-项-因子的递归嵌套结构,因子作为一个接口实现。表达式也实现因子这个接口。这就为套娃留出了足够的空间。
表达式的解析由ExpBuilder这样一个工厂类进行,错误时抛出WrongFormatException省去大量检测。
求导时递归调用,一个Factor求导生成新的Factor List对象。
优化时,optimize方法也是生成新的对象,而涉及到合并的操作则在添加项的同时完成。
为了节省时间,添加了isOptimized标志来避免在建立表达式的过程中对没有变化的项做无用的优化,forceUnsetOptiflag方法来清除这个标志位以便于进行彻底的优化。
在第三次作业中,添加了furtherCombine相关的方法来进一步减少长度捞性能分(虽然最后关头还是为了避免bug回滚了(而且回滚后还是有点小bug(悲。
当然,这个架构还有很多可进步的点,最大的问题就是Term,Term项上下都要依赖,严重提高了程序的复杂度和Bug出现的可能性。
此外,细心的读者可能已经注意到,这里我因子的操作方式是类似字符串这种不可变对象的,但是Expression和Term都是可以动态变化的(添加新的项/因子),目前我的做法是,在将某个因子构建完成、或加入一个容器之后,就再也不改变他,以防因为浅拷贝出现的各种问题。但这种需要“额外知识”才能更改代码的做法显然降低了软件的可维护性。
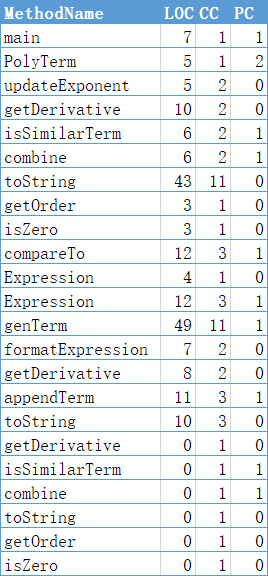
行数(第三次)
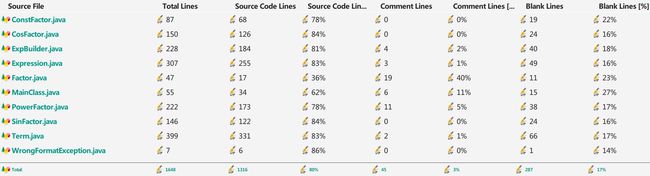
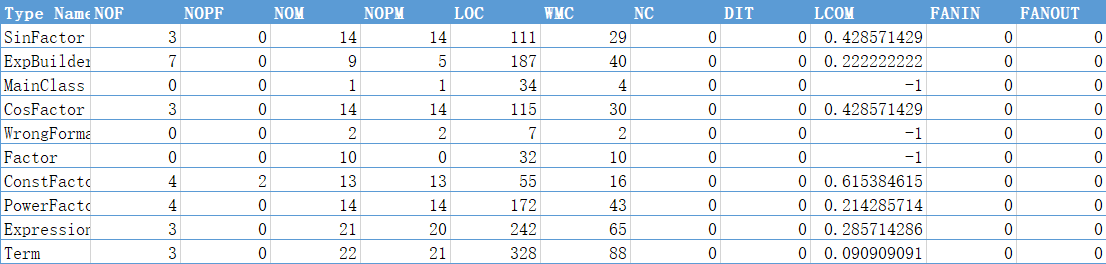
可以看到,这次作业规模不小,最多的代码在Term上(部分原因是Term有两套合并同类项算法),然后是Expression,ExpBuilder,除表达式外因子中幂函数的代码最为复杂,这很好的说明了拆开幂函数和常数的必要性
复杂度
二/三次作业复杂度只能用爆炸形容,如图(以下均为第三次内容,第二次->第三次我仅更改了读入部分和加入了一定优化)
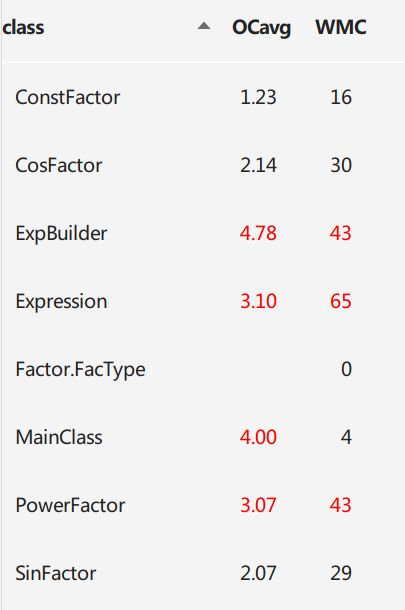

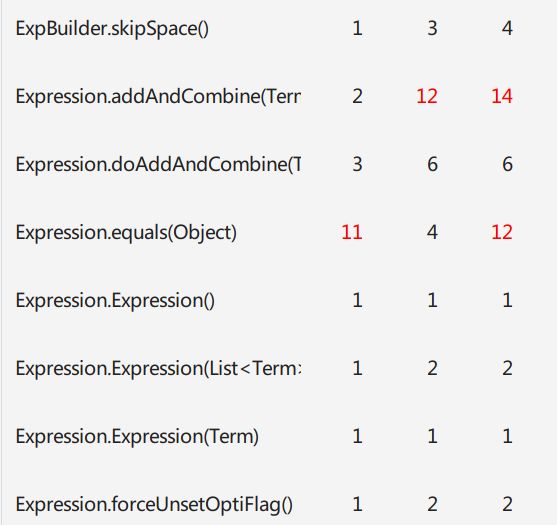
复杂度最大的是ExpBuilder,仔细想了一想,应该是getFactor的锅,为了方便我把对所有因子的解析放在了一个方法getFactor里,实际上完全可以把不同的因子分开设置一个方法来处理。复杂度分析证实了我的想法。

再接下来复杂度较大的就是Term类了,无论第二次还是第三次作业,Term都既要与Expression打交道,又要与Factor打交道,同时承担了最多的化简任务,可以说设计的着实不太好。
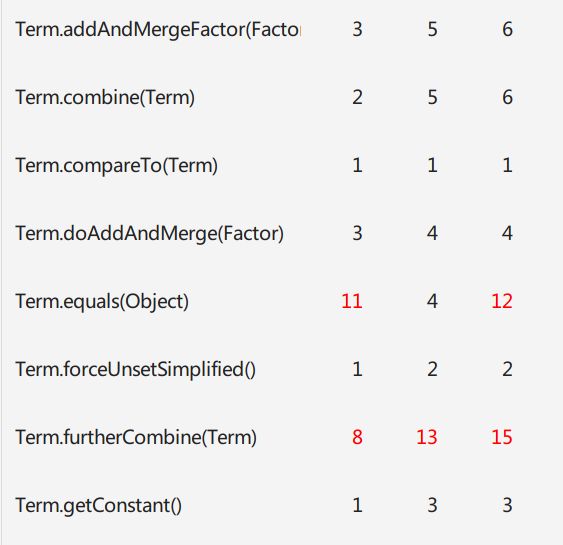
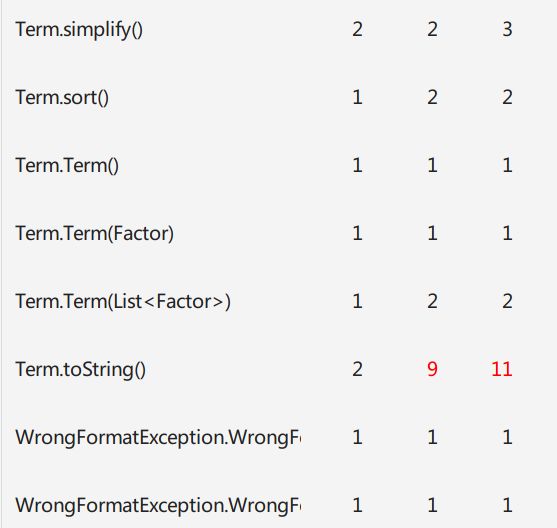
Term的复杂度主要表现在:优化合并(第二次三角,第三次带括号)和输出上,这也是程序的设计难度。
Expression类,复杂度也集中在化简和添加项上

依赖
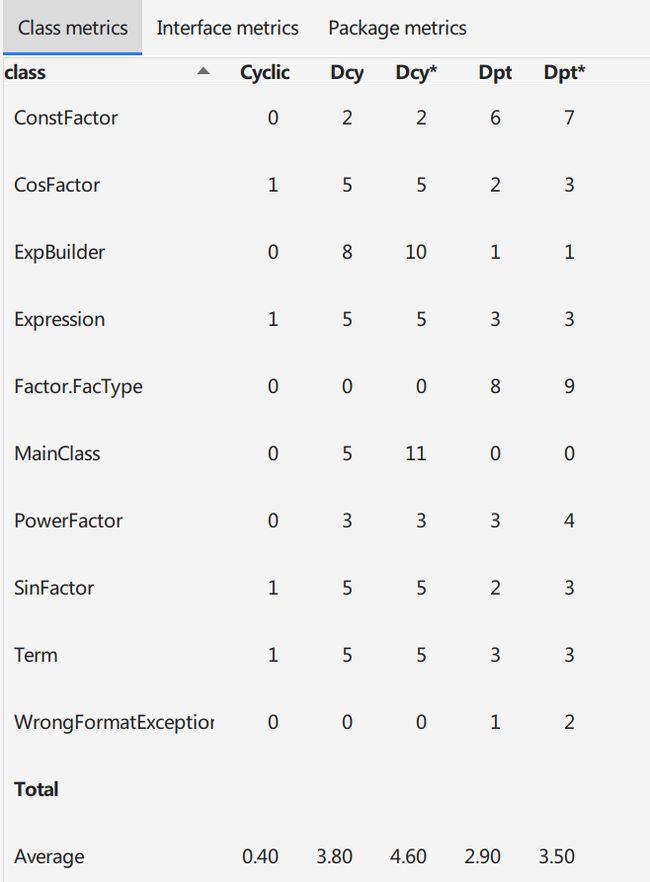
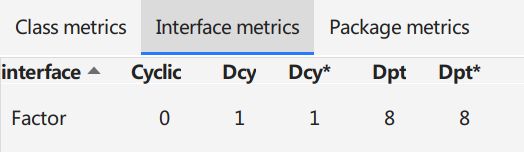
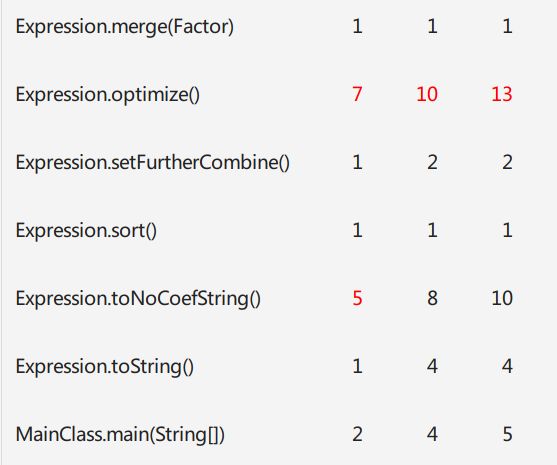
依赖关系仍然整体来说比较正常,我主要使用了接口,DIT是1.正是因为使用了接口,才尽量减少了Cylic型依赖
DesigniteJava分析
DesigniteJava检测得到,Design smell最严重的还是Unutilized Abstraction,的确,我这个架构在最开始的时候还考虑了幂函数的嵌套等问题;但此外还有Insufficient Modularizatio问题,在Expression和Term中,这证实了我的想法,这两个类应该进一步重新规划。
Implemention smell中10个Complex Method,5个Complex Conditional(溜,主要还是上面说的Expression和Term里。还有几个Magic Number,但是这些所谓“魔数”其实只是求导和优化产生的数学结果,所以我认为并不重要。
Avg LOCC 128.3,还是比较大的,Avg LOCM只有10.03,倒也不算太大。
架构分析与重构思路
基于上面的数据,我们不难看出,问题的核心是Expression和Term这两个类,特别是Term,整个体系中只有它不能用Factor接口调用。
自然的,我的想法就是,让项也成为一个因子!但是这样一来,完美的嵌套结构就会出一点问题。考虑到其实,存在只有一个项的表达式,我们不妨改变一下递归定义。
Expression的特征是由项加起来构成的,考虑到有的项只有一个因子,我们现在又计划把项作为因子,不妨把他的定义改为,因子相加的产物,同时还实现因子接口。将其称作AddItem。
类似的,把Term的定义改为因子相乘的产物,同时还实现因子接口。将其称作MulItem。这样可以极大地简化编码和不必要的嵌套。
对于嵌套,可以继续沿用基本因子内置负荷构成的方法。
Part 2 程序Bug分析
在第一、二次作业中,我的程序在强测、互测和自己的测试中均未发现Bug,原因可能是我在提交前都用了自己设计的评测机进行了大量测试,以及设计时的小规模验证(有点TDD的意思了)。
第三次作业在强测、互测中仍未发现Bug ,然而事实上在本人后来的自测中发现还是存在两个Bug。(谢各位大佬手下留情(溜
- Expression类和Term类的equals方法重写时出错,导致使用indexOf时得到错误结果,引发Bug
- 合并同类项时,未考虑一个项中存在多个相同因子的情况,导致出错
触发条件:项的因子数相同,但是因子会重复出现,且重复出现的次数不同,就有可能在合并同类项时触发。
样例:
(x+1)*(x+1)*(x+2)+(x+2)*(x+2)*(x+1)
x*(x+1)+x*(x+1)*(x+1)+x*(x+1)
总的来说,这两个错误都是在Expression和Term这两个最复杂的类里。其次,错误来源于在程序设计阶段时,我默认会把一项中所有的相同因子合并,这样就不会出现问题。但是在第二次作业到第三次作业的迭代中,这个“隐藏约定”被打破了,因为幂函数不能嵌套。
总结出的一点规律就是,尽量不要在程序中存在“隐藏约定”,这样很容易在迭代开发中出错。而且就算加以注释,其实也没有很合适的地方。
Part 3 发现他人程序Bug所采用的策略
- 直接上评测机跑(溜
看见Bug能修就修修完继续跑(加速溜- 第一次作业:关注正则,看是否会有误判,关注特殊情况下的输出
- 第二次作业:除第一次外,额外关注优化
和投机取巧(某位同学投机没注意到long范围和负数限制被当场爆破) - 第三次作业:除前两次外,关注同类项合并以及优化带来的错误(就是自己的错),还有优化带来的格式错误(
cos(),(1+x)*(1+x)把括号给去了导致错误)等。
Part 4 应用对象创建模式
基本在第一部分的时候已经分析过具体的重构方法了,此外:
- 首先,使用工厂方法,创建表达式时,注意工厂方法内部的拆分
- Expression和Term分别用AddItem和MulItem代替,形成一种多叉树的结构
- 合并时采用迭代器模式
- 尽量使用Clone避免浅拷贝问题
Part 5 对比与心得体会
- 不要在不该拓展的时候瞎拓展,留出拓展空间固然重要,也不要过于复杂化问题
- 千万不要有“隐藏约定”,Bug最容易在这里出现
- 代码不能太过复杂,该拆则拆
- 当你连注释都不知道写在哪合适的时候,就该思考自己的设计是否合理了
OO第一单元总体还是比较平稳,个人最艰难的时候是第二周试图一步到位。其实一开始就设计好的架构并不一定是最好的,在开发的过程中可能就有更好的方法出现。所以如何迭代开发,在可拓展和过度复杂化问题间找到一个平衡,这是我下一步要努力的方向。