- 面向对象第一单元总结
- 单元内容
- 代码结构分析
- 第一次作业
- 第二次作业
- 第三次作业
- bug 分析
- 心得和体会
- 1.二八定律
- 2.评测机
- 3.体会
面向对象第一单元总结
单元内容
本单元的内容是表达式导函数的求解,三次作业不断完善函数种类和组合规则,具体如下:
-
简单多项式导函数的求解
-
包含简单幂函数和简单正余弦函数的导函数的求解
-
包含简单幂函数和简单正余弦函数的导函数及其组合的求解
代码结构分析
第一次作业
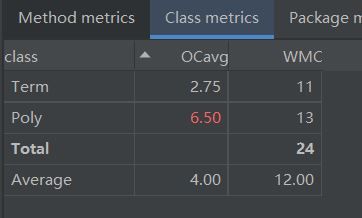
第一次作业只涉及有符号整数和幂函数两种类型的因子,结构比较简单,所以只设计了Term(项)和Poly(多项式,包括main)两个类,在Term中实现求导方法,在Poly中调用。
第一次作业抽象程度很低,导致类和方法的复杂度都很高,不易调试,最后也出现了bug,第二次重构。
第二次作业

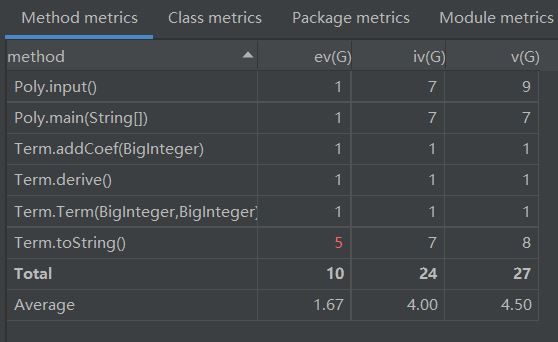
第二次作业严格按照表达式(Expression)、项(Term)、因子(Factor)的三层结构进行函数的储存和求导,并设有因子工厂和正则库。
复杂度还可以,缺点在于耦合度高,方法的设计受数据类型(参数、返回值)限制太大,不够灵活。这样的程序结构虽然可以完成第三次作业,但需要进行大量改动,不如重构。
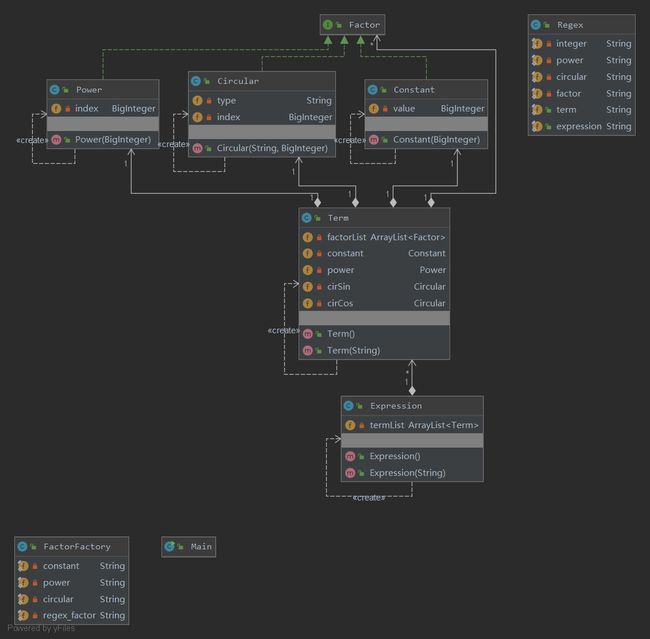
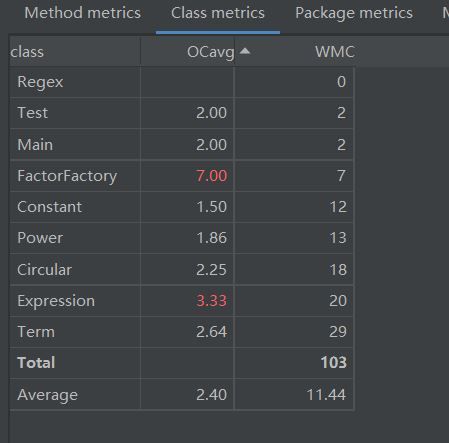
第三次作业
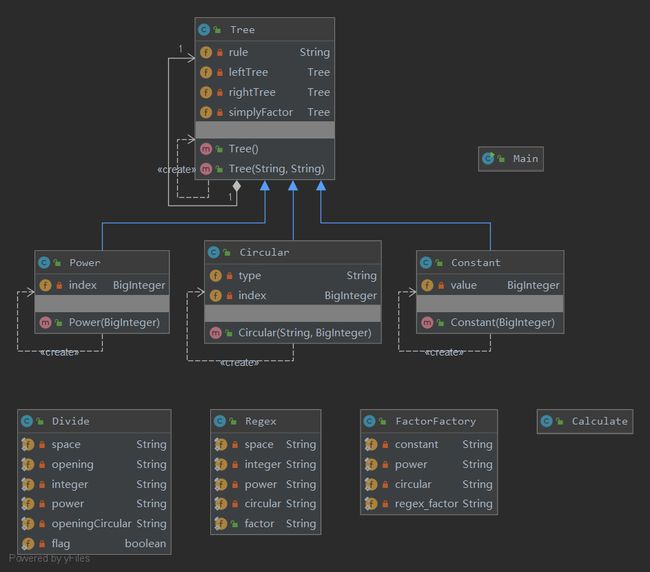
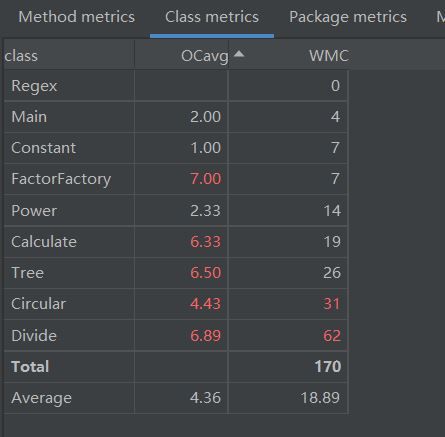
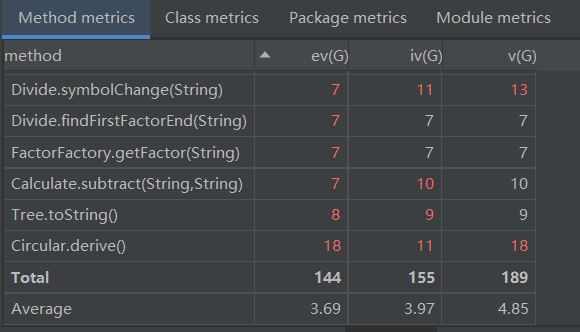
第三次作业采用二叉树(Tree)的数据结构,三种简单因子类继承Tree类,作为叶子,结构比较清晰。
用这样的结构,求导方法和 toString()方法容易实现,难点在于树的创建,需要繁杂的字符串处理方法,我程序的复杂度大多聚集于此,而且极易产生bug,debug过程中我又不断打补丁,导致程序比较“丑陋”。
关于优化:现在想一想,这次重构是不彻底的重构,我在保留原来factor类的同时,也保留了factor的工厂,这样就固化了产品的类型(不支持嵌套),与新的部分相接不紧密,factor继承Tree也是假继承。在新的结构下完全可以改写FactorFactory,不仅可以生产简单因子,也可以生产Tree类型的复杂因子。
bug 分析
HW1有1个bug:处理符号时少了一个分支,没有什么代表性,究其原因还是分层抽象做得不好,复杂度太高
HW2有1个bug:题面理解错误(...),暂且不谈
HW3有2个bug:
-
树的创建
如果第一项前是 ‘-’ ,需要补0,变成 “0 - A” 的形式,所以第一项的符号我是单独处理的,处理后会删掉这1-2个符号。这个操作应该只在第一项前使用,而我在处理所有的expression时都调用了,会多余地删掉符号,形如 “---x” 的WF就判断不出了。
debug:加了一个static的开关,只在第一次处理expression时打开。
-
用 ‘-’ 连接的两个expression,提取出 ‘-’ 后,后一个expression没变号
A - B + C 应该提取出 A 和 B - C ,用 - 连接。
debug:写了一个变号方法。
互测
参考评论区同学的帖子,搭了评测机对拍,效果还不错,尤其在C屋
互测的时候还是有些惊讶,指导书上的样例都能测出几个bug,有时候输进去1或者x就出错了,同学们(包括我)还是要细致一点,老实把样例测试了。
心得和体会
1.二八定律
我对第一单元的最大体会可能就是这个“二八定律”了,用我自己的经历来说就是,在整个程序结构中只占20%的部分,我在上面花费了80%的精力,而最后的bug 100%处于这个部分。这无疑是令人失落的,所以我痛定思痛,仔细想了想原因。
在我想来,这个定律是一个伪命题,究其原因还是结构设计的不好,将太多内容囤积在一处所致。本来占据40%左右的几个程序,因为我事先没有想清楚,设计的时候将他们混为一体,于是就感觉像是20%了。而这一部分程序超额实现了它本身不该有的功能,自然比较复杂,思考时更费神。
拿我的第三次作业举例子,我设计Divide类的初衷很简单,就是实现这样一个效果:把一个表达式一分为二,不可分返回null,甚至不用判断WF,说占20%并不夸张,然而,我最终足足写了300行,才填满了各种坑。
抛开自身水平不行的因素,以我的能力,如何把它做得更好?首先是对于不同种类的表达式,divide的方式不同,可以分开处理;其次是和Tree的创建结合,是不是可以再创造一个TreeFactory,在Divide和Tree之间搭一座桥,这样代码可能会更加友好。
2.评测机
写一个自己的误区吧,就是自己的矛攻不破自己的盾。我是觉得自己写的评测机测不出自己的bug,每次都是互测开始的时候才开始修评测机,然而第三次作业的bug太大了,随便测测都能测出来,有点后悔。还是分情况看,自己的代码也可以跑跑。
3.体会
三次作业两次重构,每次都有bug,分越来越低……这个结果实在没什么值得高兴的地方。还是要做好架构,认真自测,一步一个脚印。