前言
第一单元的作业主要是以多项式求导为载体来训练我们的面向对象的思维,难度循序渐进,复杂度也一直在提高,但是面向对象的体现性也越来越强,当然带来的优势与便利也在逐步提升。下面的内容主要从需求分析,代码结构与框架,复杂度分析,如何测试四个方面来对每一次作业进行总结。
第一次作业
需求分析
第一次作业需要我们对简单多项式进行求导,只需要支持简单的幂函数加上常数项即可,且项与项之间只有加法和减法,难度并不是很大。
代码结构与框架
写第一次作业时我竟然神奇地忽略了指导书中的正则表达式指导,并且本身对其的使用并不是很了解,便没有使用正则表达式对输入进行处理,而是使用简单粗暴的情况判断对整行的输入进行了一个读取。所以大部分篇幅都是对输入的处理上。因为多项式的结构比较简单,只是新建了一个项类,用于存储该项的常数项系数,幂函数的指数项。大致处理过程就是一个项一个项的读入,放入hashmap中,放入的时候合并同类项,当整个表达式都读取完毕后,再从hashmap中取出来进行逐项求导,求导后再放入一个待输出的hashmap中。因为要是输出的长度尽可能的短,便加上了一个比较长的输出处理函数,先输出正的项,最后输出负的项,并且对一些能省略的符号都进行省略。所以最后得到的程序就是两个大类,一个是项类,一个就是集各种功能于一身的主类。
复杂度分析
因为不涉及多个类之间的调用,仅是一个类之间函数的调用,所以循环依赖和继承树的深度都为0。但是由于输入处理没有采用正则表达式,所以带来的循环与条件语句显得比较复杂。
如何测试
本次采用了一向使用的自己自动生成数据测试的测试方法,由于没有使用过python,所以自己用java写了一个自动生成测试程序的代码,可以随机的生成测试数据。
因为种类较多,所以随机生成数据的代码较长。


import java.util.Random; public class MainClass { private static int op1;//+- private static int op2;//+- private static int op3;//m private static int op4;//x private static int op5;//** private static int op6;//+- private static int op7;//n public static void main(String[] args) { int col = 0; while (col < 80) { print_Symbol(); print_Space(); print_coefficientSymbol(); print_coefficient(); print_Space(); print_multiply(); print_Space(); print_x(); print_Space(); print_power(); print_Space(); print_indexSymbol(); print_index(); print_Space(); col++; } } public static void print_Symbol() { Random rd = new Random(); op1 = rd.nextInt(2); if (op1 == 0) { System.out.print('+'); } else { System.out.print('-'); } } public static void print_Space() { Random rd = new Random(); int op = rd.nextInt(3); while (op > 0) { System.out.print(" "); op--; } } public static void print_coefficientSymbol() { Random rd = new Random(); op1 = rd.nextInt(3); if (op1 == 0) { return; } else if (op1 == 1) { System.out.print('+'); } else { System.out.print('-'); } } public static void print_coefficient() { Random rd = new Random(); if (op1 == 0) { op2 = rd.nextInt(2); if (op2 == 0) { return; } } op2 = 1; int length = rd.nextInt(1) + 1; StringBuilder sb = new StringBuilder(); while (length > 0) { int number = rd.nextInt(3); sb.append(number); length--; } System.out.print(sb.toString()); } public static void print_multiply() { Random rd = new Random(); if (op2 == 1) { op3 = rd.nextInt(2); if (op3 == 0) { return; } else { System.out.print("*"); } } } public static void print_x() { Random rd = new Random(); if (op3 == 1) { op4 = 1; System.out.print("x"); } else if (op2 == 1) { op4 = 0; return; } else if (op1 != 0) { System.out.print("x"); op4 = 1; } else { op4 = rd.nextInt(2); if (op4 == 0) { return; } else { System.out.print("x"); } } } public static void print_power() { Random rd = new Random(); if (op4 == 0) { op5 = 0; return; } else { op5 = rd.nextInt(2); if (op5 == 0) { return; } else { System.out.print("**"); } } } public static void print_indexSymbol() { if (op5 == 0) { op6 = 0; return; } else { Random rd = new Random(); op6 = rd.nextInt(3); if (op6 == 0) { return; } else if (op6 == 1) { System.out.print("+"); } else { System.out.print("-"); } } } public static void print_index() { if (op5 == 0) { op7 = 0; return; } else { Random rd = new Random(); int length = rd.nextInt(1) + 1; op7 = 1; StringBuilder sb = new StringBuilder(); while (length > 0) { int number = rd.nextInt(3); sb.append(number); length--; } System.out.print(sb.toString()); } } }
第一次作业出现的一个bug在输出的处理上,x**-1次方输出时为了简便漏掉了一个判断选项,导致输出-x,在互测时惨遭毒手,同一个x**-1被hack了18次。
第二次作业
需求分析
第二次作业在第一次的基础上迭代增加了三角函数类,并且一个项之间增加了乘法的运算,即输入一个项时不会是简单的一个幂函数加上常数项的形式。并且这次作业加上了异常处理的需求,即在输入不符合表达式结构的式子时需要输出WRONG FORMAT!
代码结构与框架
这次看到了正则表达式指导的文档,并在输入处理上采用了正则表达式的形式,一下子降低了输入处理的复杂度。第二次作业采用的策略是先逐项读取,再进行因子分析,即先利用正则表达式一个一个项进行读取,再从每个项中分出因子,因为总共只有四类因子,即常数因子,幂函数因子,三角函数的两类因子。所以新建了一个项类专门管理每个项。之后的求导与输出便和第一次作业的处理相类似,因为观察到每个项的求导形式固定,所以仅需一个求导函数即可对整个项进行求导。求导后得到的新的项仍然存在hashmap中。不过这次的化简处理较为复杂,而本人仅对于平方和为一的条件进行展开并化简,但不能化到最简,因为会涉及到大量的递归处理。
而对异常输入的处理也放在了input类中,利用正则表达式进行判断,如果没有找到符合正则表达式的式子,则直接输出WRONG FORMAT!如果找到了符合条件的最长表达式但是不是原表达式则同样输出异常。
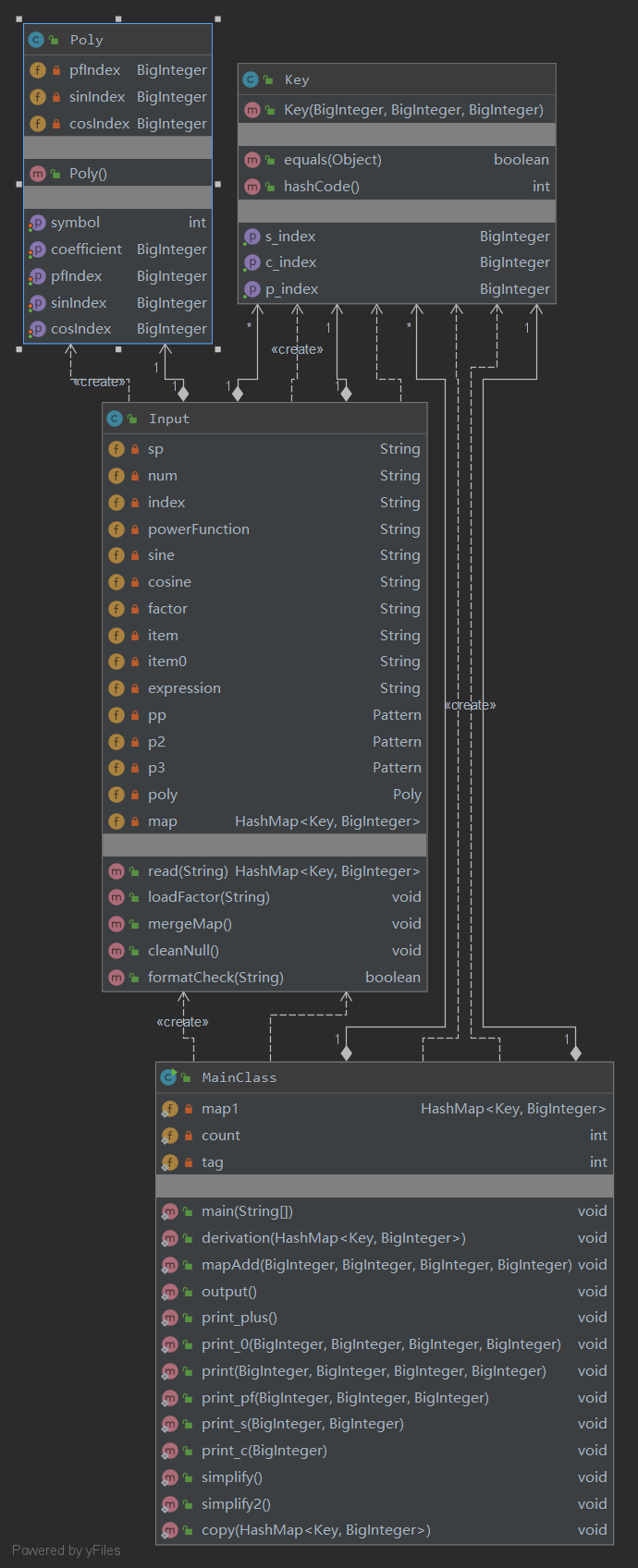
复杂度分析
因为这次作业没有涉及到类之间的多重调用,所以复杂度仍然没有体现性。
如何测试
第二次作业的测试方法完全使用了全自动的测试方法,即利用强大的python工具实现对代码的自动测试,随机生成数据的采用了python的xeger包,即可根据正则表达式随机生成想要的数据,并利用windows批处理工具加上python代码实现正确性的自动对拍。
这次自己的程序并没有出现bug,而互测屋里的其他同学都或多或少的出现了bug,大多都是在一些细节的处理上。例如有的同学-1仅仅输出了一个负号,还有的同学项与项之间在特定情况下少了一个符号,还有一个同学在特定情况下结果总会多出一个sin(x)。
第三次作业
需求分析
第三次作业一下子加大了难度,在第二次作业的基础上迭代增加了递归的操作,并且增加了表达式因子,即引入了对括号的处理。即三角函数里的括号里的内容可以无限递归下去。
代码结构与框架
第三次作业的输入处理仍然延续采用了正则表达式的结构,不过需要对表达式进行预先的处理。格式检查这一操作则放在整个程序的第一步,这次的格式检查难度也极大地提升了,不能是简单的字符串匹配,而是要加上递归的检查与处理,即先将所有的表达式因子转换成同等的字符,在每次检查时去掉嵌套,再进入嵌套中进一步检查,从而达到从外到内检查整个表达式的目的。
在检查格式无误的情况下,再将整个表达式中的空白字符全部删除,再进行输出处理与求导操作。
这次主要是利用了各类函数共同实现求导接口的方式来对整个表达式来进行求导。同时也采用了层次化的思想来完成对整个作业的处理。即将整个表达式看成项之间的依次加减叠加,每个项内各个因子的相乘叠加,因子之内的嵌套叠加,从而求导时按照此规律递归求导。这次并没有利用任何结构去存取相关的项,因子或系数等,直接用一个待输出的表达式存取递归求导返回的表达式。最后便可在这个求导后得到的表达式上进行化简的处理。
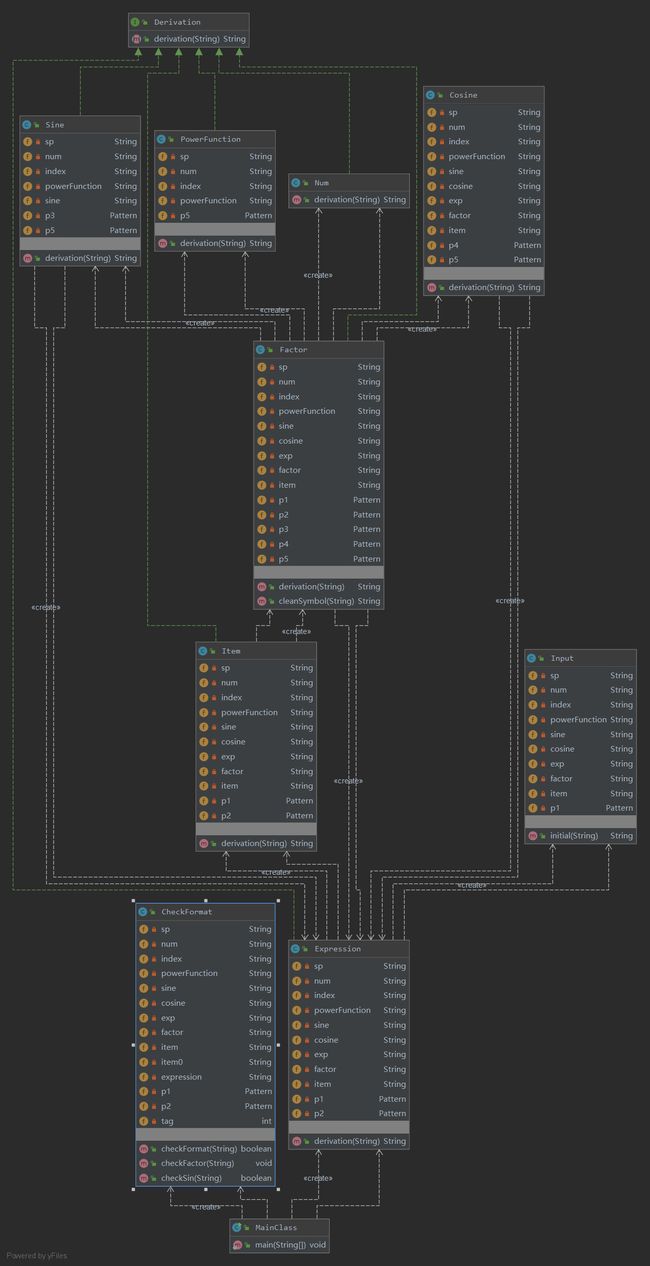
复杂度分析
本次作业的复杂度主要体现在了类之间的循环递归调用的层面上。
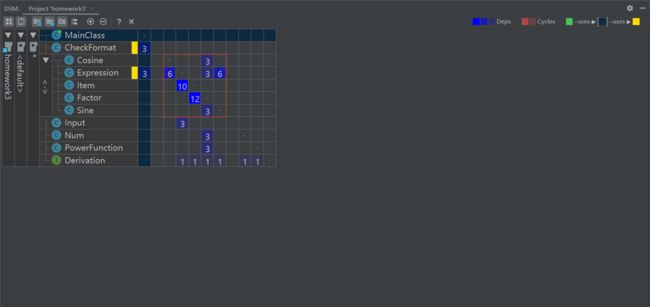
如何测试
本次由于表达式是递归结果,直接由python的xeger包是不能生成的,需要使用一定的技巧来控制生成,并且只需要加入一些控制变量即可控制嵌套的深度等。主要采用了表达式替换的策略,即将可以嵌套的地方用符号标记,再从标记的地方递归生成表达式,当达到指定嵌套深度时,停止表达式的继续嵌套。
import random from xeger import Xeger fo = open("raw_poly.txt", "w") expressionRegex = "^(@[+-]{1,2})*@$" termRegex = "^(#\\*)*#$" sinFactorRegex = "^[ \\t]*sin[ \\t]*\\(~\\)([ \\t]*\\*\\*[ \\t]*(\\+)?[1-9]\\d{0,1})?$" cosFactorRegex = "^[ \\t]*cos[ \\t]*\\(~\\)([ \\t]*\\*\\*[ \\t]*(\\+)?[1-9]\\d{0,1})?$" powerFactorRegex = "^[ \\t]*x[ \\t]*([ \\t]*\\*\\*[ \\t]*(\\+)?[1-9]\\d{0,1})?$" constFactorRegex = "^[ \\t]*[+-]?(([1-9]\\d{0,1})|0)$" exprFactorRegex = "^\\(!\\)$" x = Xeger(limit=2) def generate(): max_round = 2 result: str = x.xeger(expressionRegex) generate_round = 0 while True: generate_round += 1 for termCount in range(result.count('@')): result = result.replace('@', x.xeger(termRegex), 1) for factorCount in range(result.count('#')): factor_type = random.randint(0, 4) if factor_type == 0: if generate_round > max_round: result = result.replace('#', x.xeger(powerFactorRegex), 1) else: result = result.replace('#', x.xeger(sinFactorRegex), 1) elif factor_type == 1: if generate_round > max_round: result = result.replace('#', x.xeger(powerFactorRegex), 1) else: result = result.replace('#', x.xeger(cosFactorRegex), 1) elif factor_type == 2: result = result.replace('#', x.xeger(powerFactorRegex), 1) elif factor_type == 3: result = result.replace('#', x.xeger(constFactorRegex), 1) elif factor_type == 4: if generate_round > max_round: result = result.replace('#', x.xeger(powerFactorRegex), 1) else: result = result.replace('#', x.xeger(exprFactorRegex), 1) for innerCount in range(result.count('~')): factor_type = random.randint(0, 4) if factor_type == 0: if generate_round > max_round: result = result.replace('~', x.xeger(powerFactorRegex), 1) else: result = result.replace('~', x.xeger(sinFactorRegex), 1) elif factor_type == 1: if generate_round > max_round: result = result.replace('~', x.xeger(powerFactorRegex), 1) else: result = result.replace('~', x.xeger(cosFactorRegex), 1) elif factor_type == 2: result = result.replace('~', x.xeger(powerFactorRegex), 1) elif factor_type == 3: result.replace('~', x.xeger(constFactorRegex), 1) elif factor_type == 4: if generate_round > max_round: result = result.replace('~', x.xeger(powerFactorRegex), 1) else: result = result.replace('~', x.xeger(exprFactorRegex), 1) for exprCount in range(result.count('!')): result = result.replace('!', x.xeger(expressionRegex), 1) if result.find('@') == -1 and result.find('#') == -1 and result.find('~') == -1 and result.find('!') == -1: break return result str = generate() fo.write(str + "\n")
这次程序出现了两个本不该出现的bug,在检查输入式子格式的时候竟然把cos的最后一个字母当成了n,导致如果输入中cos后嵌套的表达式中出现格式错误将忽略。还有一个bug就是为了减少括号而在表达式递归加减时没有对后面的表达式套上括号,这样就导致了如果括号外面是负号,如果括号里面是多个式子时就会出现负号的错误。
在互测阶段仍然是使用自动测试程序对他人的程序进行测试,大多数bug都是在多重嵌套是细节上出现了错误。
总结与反思
在第一单元的作业练习中,虽然并没有淋漓尽致地将面向对象的思想应用到作业当中,但在思考与体验的过程中也慢慢地领略了面向对象的思维特点与处理方法,并在和老师同学助教的交流中受益匪浅,也学会了一些重要的操作,更是对java语言的进一步了解与熟悉。相信在后续的oo作业中,能尽最大可能地将面向对象的思维应用到其中去。