Redis在Linux上的单机版和集群版安装
Redis下载及安装
下载地址
上传Redis

解压Redis
tar -xvf redis-5.0.4.tar.gz
安装redis
要求:在redis的根目录中执行
命令:
1.make
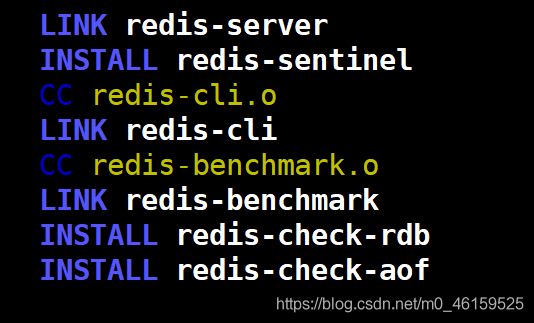
2.make install

修改redis配置文件
vim redis.conf
显示行号
说明:利用:set nu 指令显示行号

关闭IP绑定
只有去除ip绑定则远程才能访问redis.
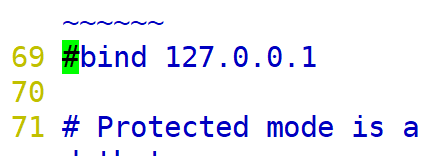
关闭保护模式

开启后台启动
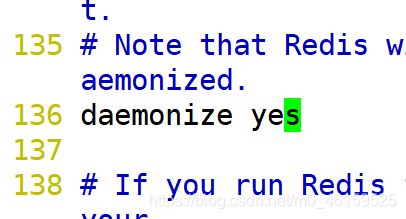
修改之后,保存退出.
Redis启动命令
基本命令
说明:启动时需要依赖redis的配置文件
启动命令:
redis-server redis.conf
关闭命令:
redis-cli -p 6379 shutdown

redis进入客户端:
redis-cli -p 6379

SetEX方法
保证赋值操作的原子性.
//测试类的初始化操作
private Jedis jedis;
@BeforeEach //在执行@Test注解方法之前执行
public void init() {
jedis = new Jedis("192.168.126.129", 6379);
}
//问题:如果采用expire则不能保证超时时间的原子性(同时)操作!!!!
//lock锁: 死锁!!!!
@Test
public void testStringEX() throws InterruptedException {
jedis.set("abc", "测试数据的有效期"); //1.没有设定超时时间 永不过期
//int a = 1/0; //如果出错,则不能添加超时时间
jedis.expire("abc", 5); //2.设定超时
Thread.sleep(2000);
Long seconds = jedis.ttl("abc");
System.out.println("abc剩余的存活时间:"+seconds);
//jedis.persist("abc");
//保证赋值的原子性操作
jedis.setex("www", 10, "超时测试");
}
SetNX/Set方法
/**
* 需求说明:
* 1.如果key存在时,不允许修改.
* @throws InterruptedException
*/
@Test
public void testStringNX() throws InterruptedException {
/*
* jedis.set("a", "123"); jedis.set("a", "456");
* System.out.println(jedis.get("a"));
*/
/*
* if(!jedis.exists("a")) {
*
* jedis.set("a", "11111"); } System.out.println(jedis.get("a"));
*/
//如果key不存在时,则赋值
jedis.setnx("a", "123");
jedis.setnx("a", "456");
System.out.println(jedis.get("a"));
}
/**
* 1.保证超时时间的原子性操作 EX
* 2.保证如果key存在,则不允许赋值. NX
* 要求:又满足超时定义,同时满足数据不允许修改
* SetParams:参数
* EX:秒
* PX:毫秒
* NX:有值不修改
* XX:如果key不存在,则数据不修改. 只有key存在时,修改
*/
@Test
public void testStringEXNX() {
SetParams setParams = new SetParams();
setParams.ex(20).xx();
jedis.set("a", "66666666", setParams);
System.out.println(jedis.get("a"));
}
Redisd事务控制
说明:虽然redis提供了事务操作.但是该事务是一种弱事务.
只对单台redis有效.
如果有多台redis,如果需要使用事务控制,则一般使用队列的形式.
@Test
public void testTX() {
Transaction transaction = jedis.multi(); //开始事务
try {
transaction.set("a", "a");
transaction.set("b", "b");
//int a = 1/0;
transaction.exec(); //提交事务
} catch (Exception e) {
e.printStackTrace();
transaction.discard(); //事务回滚
}
}
ObjectMapper介绍
说明:ObjectMapper是com.fasterxml.jackson.databind包下的程序, 该对象是当下数据转化的主流API.
1.3.2ObjectMapper入门
说明:
1).对象转化为JSON
2).List集合转化为JSON
3).JSON转化为对象(T List)
@Test
public void test01() throws JsonProcessingException {
ItemDesc itemDesc = new ItemDesc();
itemDesc.setItemId(100L)
.setItemDesc("测试数据")
.setCreated(new Date())
.setUpdated(itemDesc.getCreated());
//1.对象转化为JSON
ObjectMapper objectMapper = new ObjectMapper();
String json = objectMapper.writeValueAsString(itemDesc);
System.out.println(json);
//2.JSON转化为对象
ItemDesc itemDesc2 = objectMapper.readValue(json, ItemDesc.class);
System.out.println(itemDesc2.toString()+":"+itemDesc2.getCreated());
}
JSON转化的原理
/**
* 原理说明:
* 1.对象转化JSON时,其实调用的是对象身上的getXXXX()方法.
* 获取所有的getLyj()方法-----之后去掉get-----首字母小写---lyj属性.
* json串中的key就是该属性.value就是属性的值. lyj:"xxxxx"
*
* 2.JSON转化为对象原理说明
* 1).定义转化对象的类型(ItemDesc.class)
* 2).利用反射机制实例化对象 class.forName(class) 现在的属性都为null
* 3).将json串解析
* object key:value
* array value1,value2
* 4).根据json串中的属性的itemId,之后调用对象的(set+首字母大写)setItemId方法实现赋值
*/
@Test
public void test03() throws JsonProcessingException {
ItemDesc itemDesc = new ItemDesc();
itemDesc.setItemId(100L)
.setItemDesc("测试数据")
.setCreated(new Date())
.setUpdated(itemDesc.getCreated());
//思考:对象转化为JSON时,底层实现如何.
String json = OBJECTMAPPER.writeValueAsString(itemDesc);
System.out.println(json);
//{id:1,name:"xxxx"}
OBJECTMAPPER.readValue(json,ItemDesc.class);
}
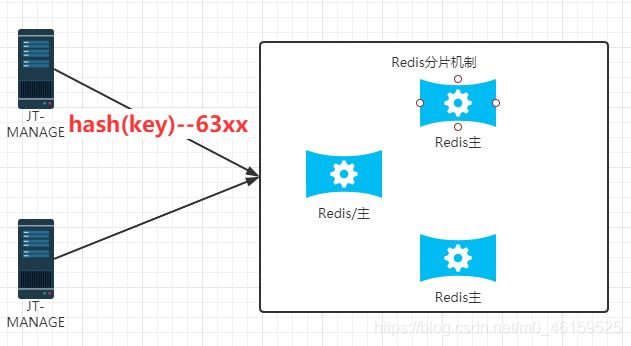
redis分片机制
需求说明
说明:由于业务需要,通常可能会将海量的数据保存到redis的内存中,实现用户快读读取.但是Redis内存容量有限,不能一味的扩大内存.因为寻址的时间大大增加,性价比不高.所以最好的方式准备多台redis分别存储数据,实现内存的扩容.提高读写效率.
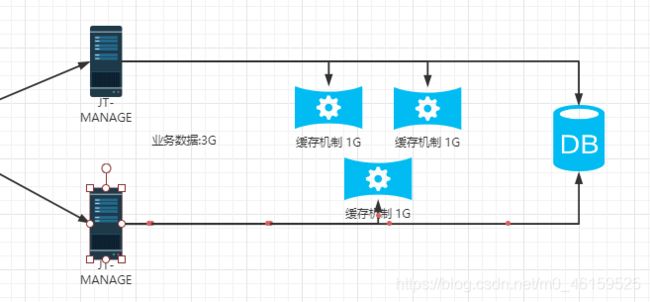
分片搭建部署
规划: 准备3台redis 6379/6380/6381
启动方式: 准备多个redis的配置文件 其中修改端口号,之后利用命令,依次执行.
redis-server 6379.conf port 6379
redis-server 6380.conf port 6380
redis-server 6381.conf port 6381
Redis分片搭建
创建分片文件目录
说明:在redis的根目录中新建一个目录shards
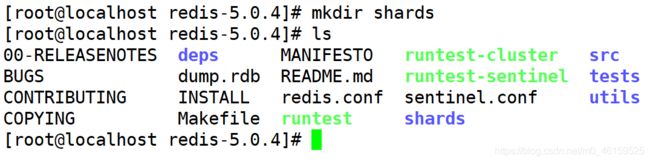
修改配置文件
1).将redis.conf的配置文件复制到shards目录中,并且改名为6379/6380/6381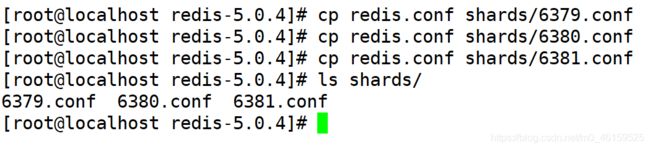
2).检索端口号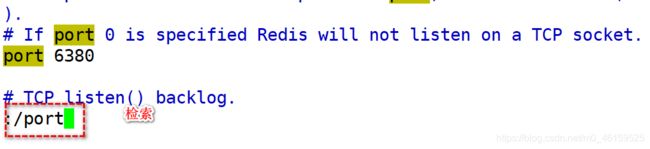
修改端口之后保存退出

启动redis分片
启动命令:
redis-server 6379.conf & redis-server 6380.conf & redis-server 6381.conf &
检索服务启动是否正常

编辑start.sh脚本
vim start.sh

关闭redis脚本
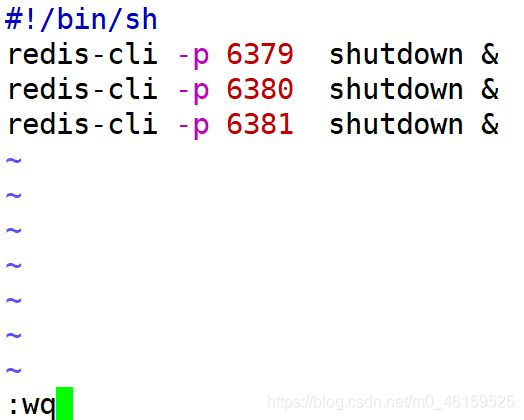
程序链接redis分片
//思考: shards的数据如何存储的????
@Test
public void testShards() {
List<JedisShardInfo> shards = new ArrayList<JedisShardInfo>();
shards.add(new JedisShardInfo("192.168.126.129",6379));
shards.add(new JedisShardInfo("192.168.126.129",6380));
shards.add(new JedisShardInfo("192.168.126.129",6381));
ShardedJedis jedis = new ShardedJedis(shards);
//利用shardedjedis对象操作的是多台redis
jedis.set("shards", "测试redis分片是否正常!!!!");
System.out.println(jedis.get("shards"));
}
Redis 持久化策略
概念
说明:redis的运行环境是内存中,其特点是断电或者宕机即数据清空.为了保证数据的有效性,提高用户的查询效率.所以内存的数据必须持久化.定期将内存中的数据写入到执行的文件中(磁盘中).如果redis服务器宕机了.如果下次重启时,则先读取持久化文件实现数据的恢复.
RDB 模式
说明:
- RDB 模式是 redis 的默认的持久化策略。
- Redis 会定期的将数据以快照的形式保存的RDB文件中。
风险:RDB 模式由于定期保存数据,所以可能会造成丢失数据。 - RDB 模式由于记录的是内存数据的快照,所以持久化的效率较高。
- 新的快照会覆盖旧的快照,每次保留的都是新的数据,持久化文件的大小,相对固定。
命令
-
save 指令 表示告诉redis立即将内存数据进行持久化操作.(同步) 可能造成线程的阻塞。

-
bgsave指令 以异步的形式执行持久化操作

持久化配置策略
save 900 1 如果在900秒内,用户执行了1次更新操作,则持久化1次
save 300 10 如果在300秒内,用户执行了10次更新操作,则持久化1次
save 60 10000 如果在60秒内,用户执行了10000次更新操作,则持久化1次
原则:用户操作越快,则持久化的周期越短.
思考问题:
save 1 1 由于save指令是阻塞的,所以该操作会极大的影响执行效率.
bgsave 1 1 异步操作 有可能导致内存数据与持久化文件中的数据不一致.
持久化文件名称配置

持久化文件路径配置
持久化文件默认的路径是 ./ 当前目录.

AOF 模式
说明:
- AOF模式默认条件下是关闭状态,需要手动开启
- AOF模式可以实现实时持久化操作.可以有效的解决数据丢失问题.
- AOF模式做持久化操作时,记录的是用户的操作过程.
- AOF的持久化文件相对较大,恢复数据的速度较慢.
AOF模式配置

AOF持久化策略
appendfsync always 当用户更新了redis,则追加用户操作记录到aof文件中
appendfsync everysec 每秒持久化一次. 略低于rdb模式.
appendfsync no 不持久化(不主动持久化,由操作系统决定什么时候持久化) 该操作一般不配.
关于持久化操作的总结
规则:
1.如果内存数据可以允许少量的数据丢失,则首选rdb
2.如果内存数据存储的是业务数据不允许丢失,则选用aof模式.(AOF文件相对较大,所以定期维护.)
3.redis中所有的操作都是单进程单线程操作.(串行的)所以不会造成线程并发性问题.
Redis内存策略
内存策略前提
说明:redis的数据保存在内存中,但是内存资源是有限的.如果需要存储海量的数据,则将之前的旧的数据应该先删除,之后再新增.
问题:如何判断数据是旧的?
redis定义内存大小
说明:redis中提供了9种内存机制,可以根据其中不同的算法,实现内存数据的优化.
1).修改redis内存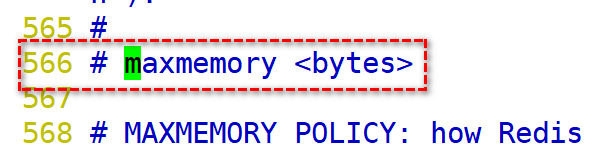
2).进制换算
内存优化算法介绍
-
volatile-lru 在设定了超时时间的数据中采用 lru算法
-
allkeys-lru . 所有数据采用lru算法
-
volatile-lfu 在设定了超时时间的数据中采用lfu算法
-
allkeys-lfu 所有数据采用lfu算法
-
volatile-random 设定了超时时间的数据采用随机算法
-
allkeys-random ->随机删除数据
-
volatile-ttl 设定了超时时间的数据,采用ttl算法
-
noeviction 不删除任何数据,只是报错返回.
修改内存策略设置: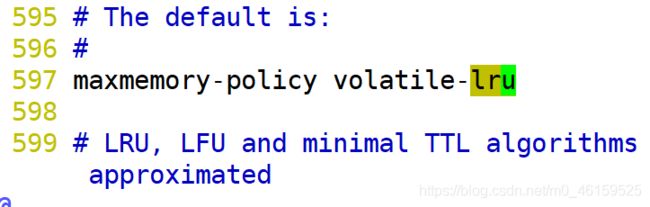
缓存穿透
场景说明:
有个坏人得知数据库中没有name="xxx"的数据.则多线程并发操作访问name="xxx"的数据.
说明:访问数据库中压根不存在的数据,则导致缓存失效.所有的请求都访问数据库.导致数据库有宕机的风险.称之为缓存穿透.
解决方案:
一般做数据的有效性的校验.
缓存击穿
场景说明:美国的暴乱信息,则redis缓存服务器中存储.但是该数据设定了有效期.当数据有效期时间一到,该数据就会在内存中删除.如果在这时有海量的用户访问"暴乱信息"则都会去查询数据库,导致数据库在一定的时间内并发增多,数据库有宕机的风险.
说明:某个热点数据(1个数据)由于超时/删除,导致大量的用户请求在同一时间访问数据库.
如何解决:
1.将热点数据永久保存.
2.添加互斥(排它)锁(每次只能有一个用户访问数据库/第二次走缓存) lock操作
缓存雪崩
说明: 在redis内存中的数据,在一定的时间内,有大量的缓存数据失效(多个),这时用户大量的访问缓存服务器,但是缓存中没有指定数据,则访问数据库.容易出现数据库宕机的现象.
如何解决:
-
让热点数据永久有效
-
设定超时时间采用随机数. 让超时的数据不要在同一时间发生
-
设定多级缓存
Redis 哨兵
分片环境问题
说明:根据测试 redis如果采用分片的机制,如果将来有1台redis宕机,则直接影响程序正常的执行.
如何解决:高可用 当redis服务器宕机可以自动的实现主从的切换.
前提条件: 需要配置缓存数据同步,数据的同步是实现高可用的前提条件.
如果没有数据同步 即使实现了高可用,则也可能由于从服务器中没有数据而导致缓存雪崩效应.
redis主从搭建
搭建规模
规定: 6379主 /6380,6381从
要求: 必须实现主从的同步
redis准备工作
1).复制shards文件目录
cp -r shards sentinel
2).删除持久化文件 dump.rdb
3).检查主机的状态
命令: 进入redis客户端中执行如下指令
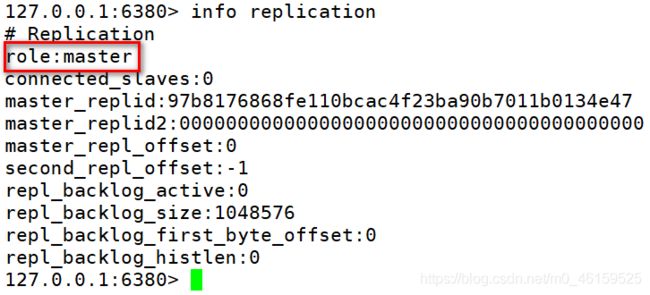
Redis主从实现
6379主机 6380/6381从机 6379----6380----6381-----6379
- 主从挂载命令:
slaveof 主机IP 主机端口
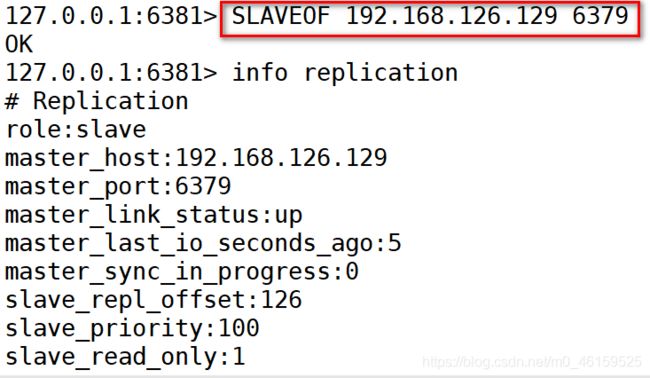
-
检查主机的状态
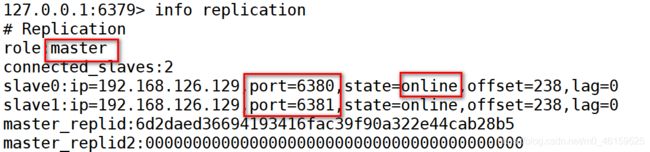
-
主从测试
1).当搭建主从结构之后,用户操作主机,从机可以自动的实现数据的同步.
2).搭建主从结构之后,从机是只读操作,不允许写入.
3).不要使用主从结构,测试分片API.

主从配置有效期
说明:
1).默认条件下通过slaveof指令,指定的主从结构只能在内存中有效.如果服务器关机重启,则该结构失效,需要手动修改.
2).如果需要指定永久的配置,则需要修改配置文件redis.conf. 但是该文件不能由用户自己操作.最好由哨兵/集群的策略完成.
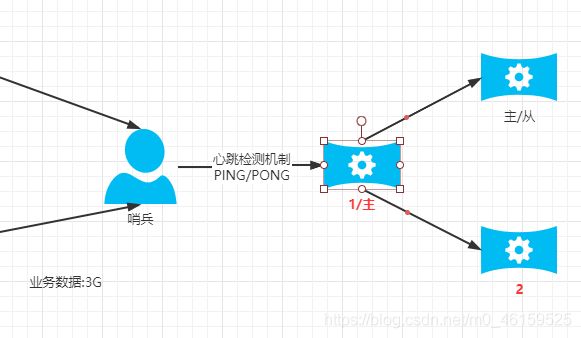
哨兵工作原理(集群前提)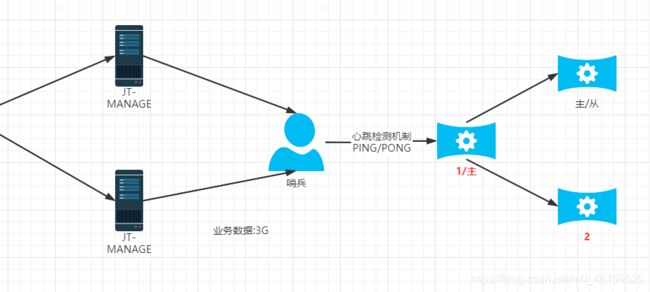
哨兵主要作用: 实现了redis节点的高可用(HA)
工作流程:
- 当哨兵启动时,首先要监控当前redis的主机.并且从主机中获取所有的从机信息。
- 当redis主机宕机之后,哨兵通过心跳检测机制检验主机是否宕机.如果连续3次都没有获取主机的反馈,则断定主机宕机.之后根据算法筛选出新的主机.
- 当哨兵选举出新的主机之后,则为了保证主从的关系,则会动态的修改各自的redis.conf配置文件.并且将其他的节点标识为新主机的从.
编辑哨兵配置文件
- 复制哨兵的配置文件到sentinel目录中
cp sentinel.conf sentinel

- 编辑哨兵配置文件
vim sentinel.conf
- 关闭保护模式(去除注释)

4. 修改后台启动

5. 修改哨兵监控
哨兵 监控 主机(变量名称) 主机IP 主机端口 1票同意生效
sentinel
onitor mymaster 192.168.126.129 6379 1

- 调整选举时间

- 修改选举超时时间.如果时间到了还没有完成选举则重新选举

哨兵高可用测试
- 启动redis哨兵服务
redis-sentinel sentinel.conf
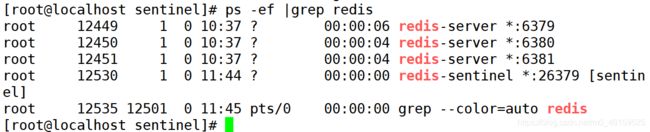
- 检查主机的状态
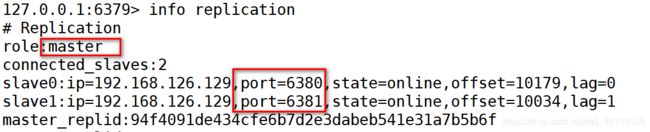
- 关闭主机等待10秒
[root@localhost sentinel]# redis-cli -p 6379 shutdown
- 检查新的主从结构

- 重启6379检查主从状态
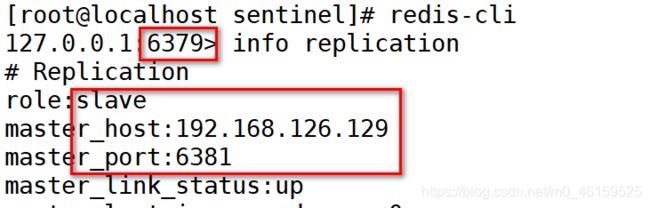
如果上述操作成功.,则哨兵搭建正常.
搭建错误解决方法
-
关闭所有的redis和哨兵服务.
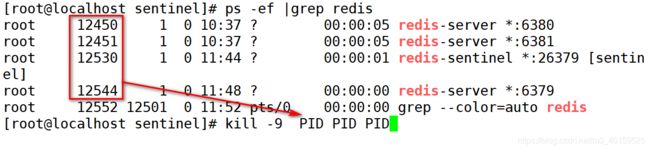
-
删除哨兵的所有的文件目录
-
重新配置salveof主从结构
-
重新配置哨兵的配置文件.
哨兵入门案例
public class TestRedisSentinel {
@Test
public void test01() {
//定义哨兵的集合信息 host:port
Set<String> sentinels = new HashSet<String>();
sentinels.add("192.168.126.129:26379");
JedisSentinelPool pool = new JedisSentinelPool("mymaster", sentinels);
Jedis jedis = pool.getResource();
jedis.set("aa", "你好我是哨兵机制!!!!");
System.out.println(jedis.get("aa"));
}
}
关于分片和哨兵总结
Redis分片特点
-
Redis分片机制可以实现Redis内存数据的扩容.
-
Redis分片机制中,是业务服务器进行一致性hash的计算.而redis服务器只需要负责数据的存储即可.所以redis分片机制性能更高.
-
Redis分片机制本身没有实现高可用的效果.如果redis节点缺失,则直接影响用户的使用.
Redis哨兵特点
-
redis哨兵实现了redis节点的高可用.
-
redis哨兵机制不能实现内存数据的扩容
-
哨兵本身没有实现高可用.哨兵如何宕机,则直接影响用户使用
Redis集群
为什么要搭建集群
通常,为了提高网站响应速度,总是把热点数据保存在内存中而不是直接从后端数据库中读取。
Redis是一个很好的Cache工具。大型网站应用,热点数据量往往巨大,几十G上百G是很正常的事儿。
由于内存大小的限制,使用一台 Redis 实例显然无法满足需求,这时就需要使用多台 Redis作为缓存数据库。但是如何保证数据存储的一致性呢,这时就需要搭建redis集群.采用合理的机制,保证用户的正常的访问需求.
采用redis集群,可以保证数据分散存储,同时保证数据存储的一致性.并且在内部实现高可用的机制.实现了服务故障的自动迁移.
集群搭建计划
主从划分:
3台主机 3台从机共6台 端口划分7000-7005
集群搭建
准备集群文件夹
- 准备集群文件夹
Mkdir cluster
- 在cluster文件夹中分别创建7000-7005文件夹

复制配置文件
说明:
将redis根目录中的redis.conf文件复制到cluster/7000/ 并以原名保存
编辑配置文件
-
注释本地绑定IP地址

-
关闭保护模式

-
修改端口号

-
启动后台启动

-
修改pid文件

-
修改持久化文件路径

-
设定内存优化策略

-
关闭AOF模式

-
开启集群配置
- 开启集群配置文件

- 开启集群配置文件
-
修改集群超时时间

复制修改后的配置文件
说明:将7000文件夹下的redis.conf文件分别复制到7001-7005中
[root@localhost cluster]# cp 7000/redis.conf 7001/
[root@localhost cluster]# cp 7000/redis.conf 7002/
[root@localhost cluster]# cp 7000/redis.conf 7003/
[root@localhost cluster]# cp 7000/redis.conf 7004/
[root@localhost cluster]# cp 7000/redis.conf 7005/
批量修改
说明:分别将7001-7005文件中的7000改为对应的端口号的名称,
修改时注意方向键的使用
通过脚本编辑启动/关闭指令
- 创建启动脚本 vim start.sh
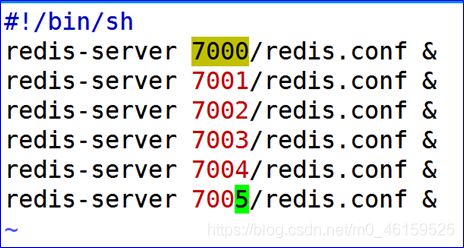
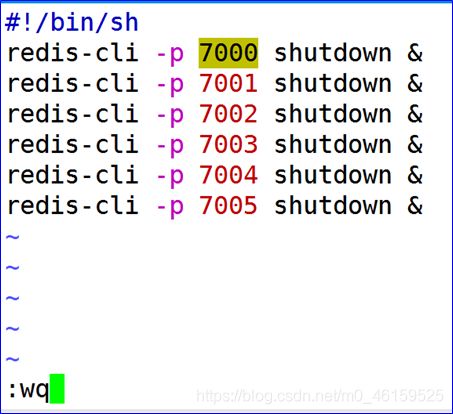
- 编辑关闭的脚本 vim shutdown.sh
- 启动redis节点
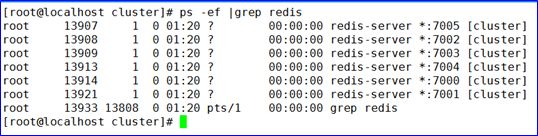
sh start.sh
- 检查redis节点启动是否正常
1.2.7 创建redis集群
#5.0版本执行 使用C语言内部管理集群
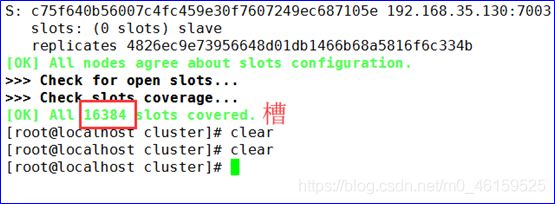
redis-cli --cluster create --cluster-replicas 1 192.168.35.130:7000 192.168.35.130:7001 192.168.35.130:7002 192.168.35.130:7003 192.168.35.130:7004 192.168.35.130:7005

redis集群高可用测试
- 关闭redis主机.检查是否自动实现故障迁移.
- 再次启动关闭的主机.检查是否能够实现自动的挂载.
一般情况下 能够实现主从挂载
个别情况: 宕机后的节点重启,可能挂载到其他主节点中(7001-7002) 正确的
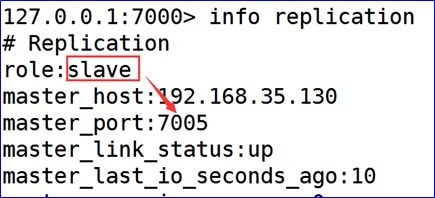
Redis集群原理
Redis集群高可用推选原理
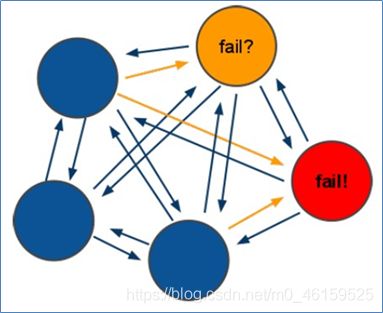
原理说明:
Redis的所有节点都会保存当前redis集群中的全部主从状态信息.并且每个节点都能够相互通信.当一个节点发生宕机现象.则集群中的其他节点通过PING-PONG检测机制检查Redis节点是否宕机.当有半数以上的节点认为宕机.则认为主节点宕机.同时由Redis剩余的主节点进入选举机制.投票选举链接宕机的主节点的从机.实现故障迁移.
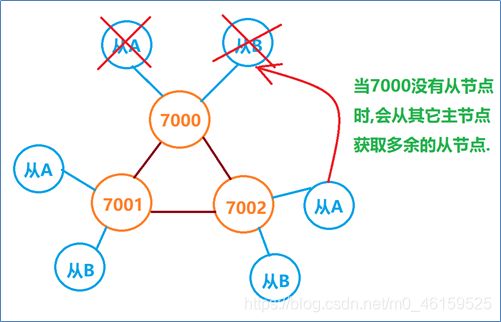
Redis集群宕机条件
特点:集群中如果主机宕机,那么从机可以继续提供服务,
当主机中没有从机时,则向其它主机借用多余的从机.继续提供服务.如果主机宕机时没有从机可用,则集群崩溃.
答案:9个redis节点,节点宕机5-7次时集群才崩溃.
Redis hash槽存储数据原理
说明: RedisCluster(redis分区)采用此分区,所有的键根据哈希函数(CRC16[key]%16384)映射到0-16383槽内,共16384个槽位,每个节点维护部分槽及槽所映射的键值数据.根据主节点的个数,均衡划分区间.
算法:哈希函数: Hash()=CRC16[key]%16384

当向redis集群中插入数据时,首先将key进行计算.之后将计算结果匹配到具体的某一个槽的区间内,之后再将数据set到管理该槽的节点中.

Redis 集群入门测试
public class TestRedisCluster {
@Test
public void test01() {
Set<HostAndPort> set = new HashSet<HostAndPort>();
set.add(new HostAndPort("192.168.126.129", 7000));
set.add(new HostAndPort("192.168.126.129", 7001));
set.add(new HostAndPort("192.168.126.129", 7002));
set.add(new HostAndPort("192.168.126.129", 7003));
set.add(new HostAndPort("192.168.126.129", 7004));
set.add(new HostAndPort("192.168.126.129", 7005));
//链接redis的集群
JedisCluster jedisCluster = new JedisCluster(set);
jedisCluster.set("cluster", "redis集群搭建成功 哈哈哈哈");
System.out.println(jedisCluster.get("cluster"));
}
}
本文内容均来自江哥笔记。