OO第一单元三次作业已经完成,带给我的压力和体验不亚于计组,尽管深夜肝OO时感到辛苦感到累,但不得不承认慕然回首,自己不知不觉中已经进步了很多,学而不思则罔,思而不学则殆,在此写下这段文字来反思总结这三周的得失,来帮助自己以更好的姿态迎接下一单元的学习。
一 程序结构分析
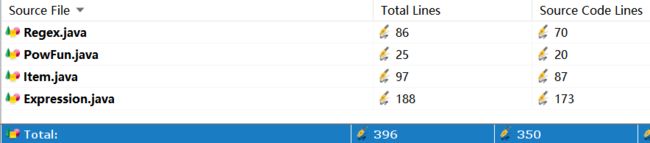
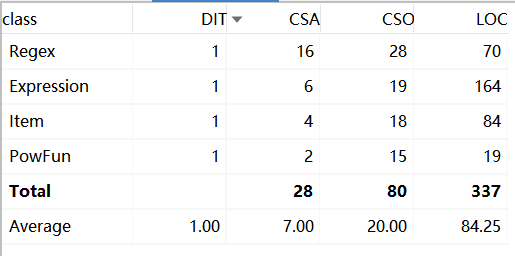
1 代码规模对量
HW1
总规模
类(属性个数,方法个数)
方法(规模,控制语句数目,分支语句数目)
HW2
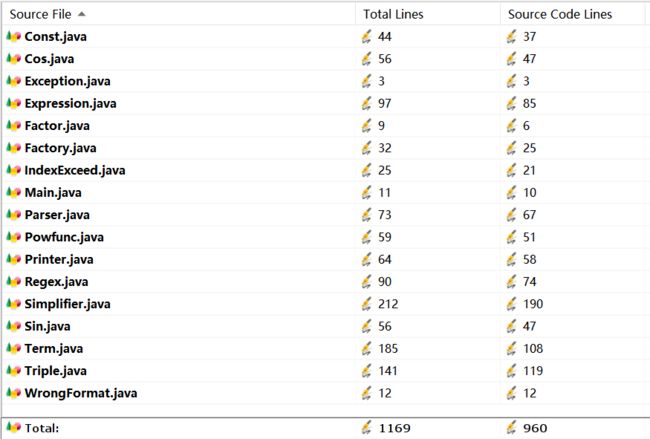
类(属性个数,方法个数)
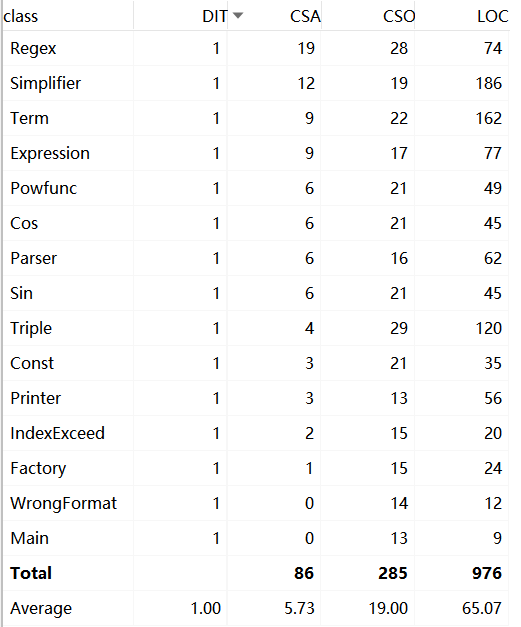
方法(规模,控制语句数目,分支语句数目)
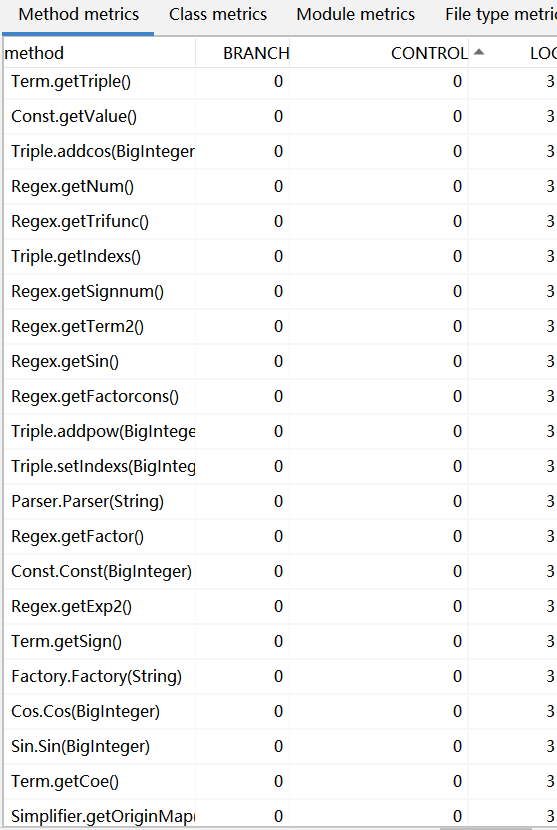
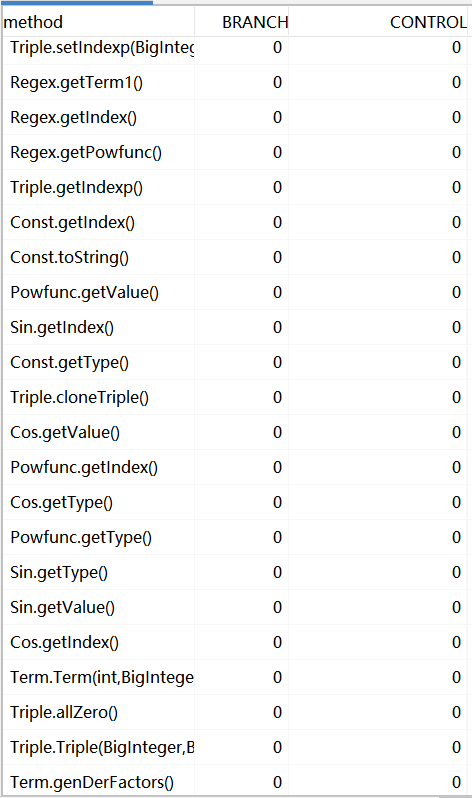
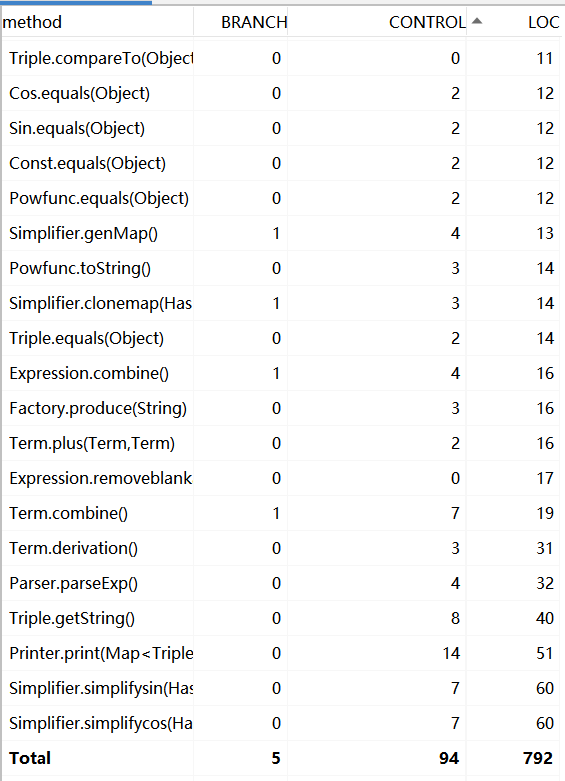
HW3
总规模
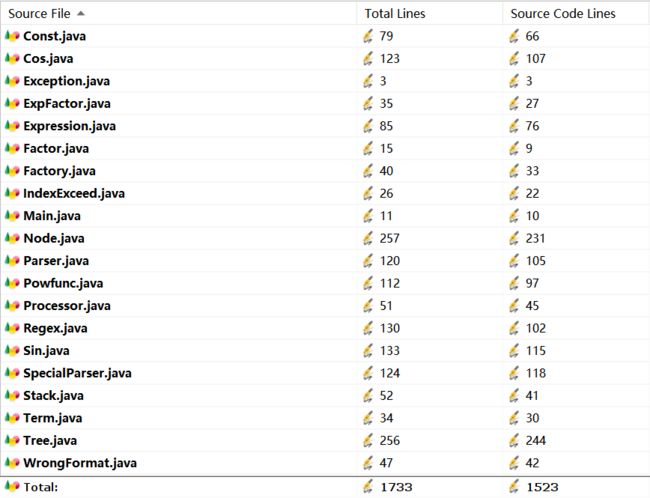
类(属性个数,方法个数)
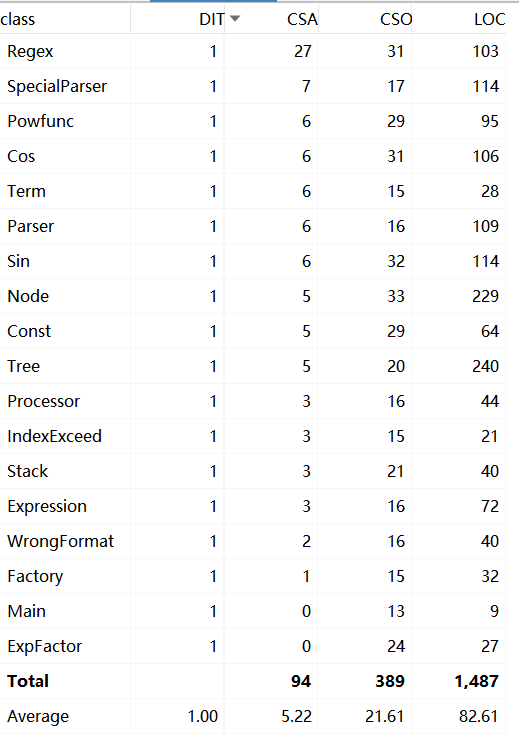
方法(规模,控制语句数目,分支语句数目)
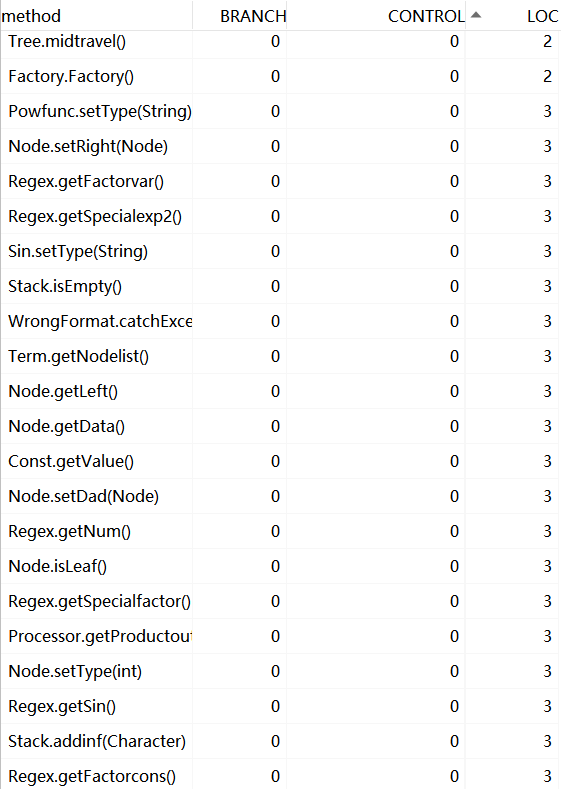
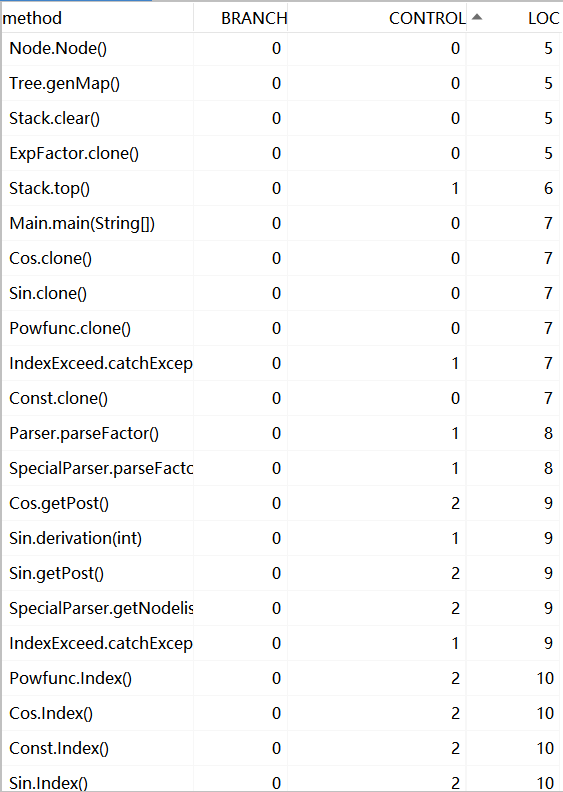
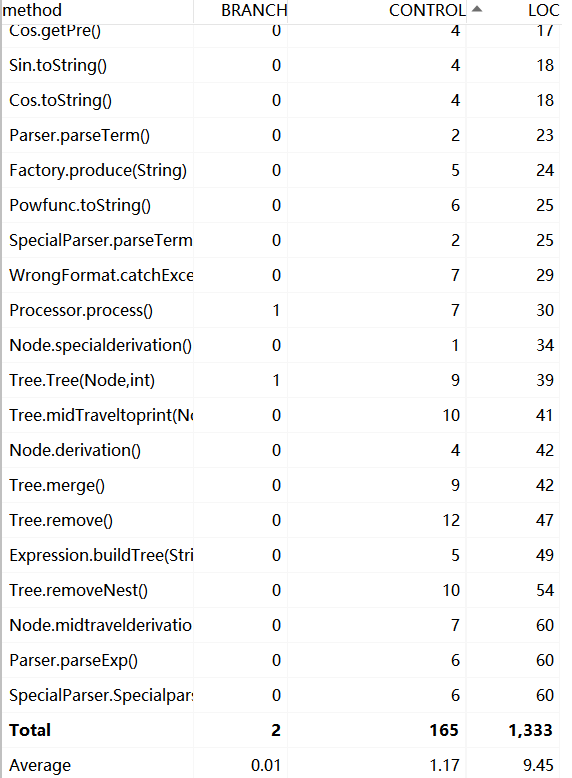
从三次作业的数据来看,无论是代码量还是类的数量,都在很明显的在增加,类中的属性方法略有增加。
这与三次作业功能迭代扩展相符合。
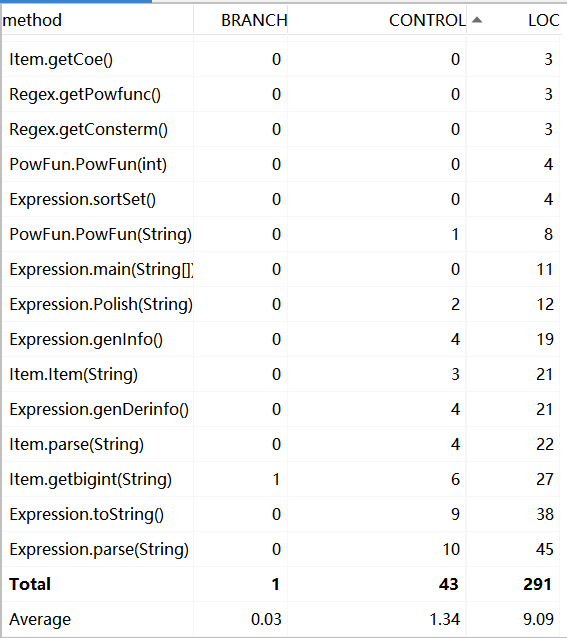
2 代码复杂度、耦合性分析
在这个环节我主要使用了IDEA内置的MetricsReloaded插件进行度量,其中主要包括以下几个参数
ev(G)基本复杂度,是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
Iv(G)模块设计复杂度,是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
v(G)圈复杂度,是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。
PS:摘自博客:https://www.cnblogs.com/daleida/p/12526833.html**
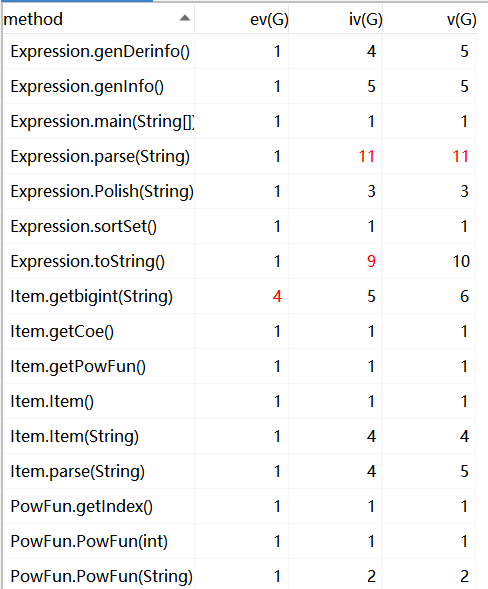
HW1
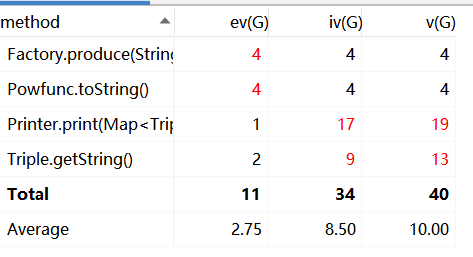
由于HW2和HW3的方法数过于繁多,故只列举复杂度异常的方法
HW2
HW3
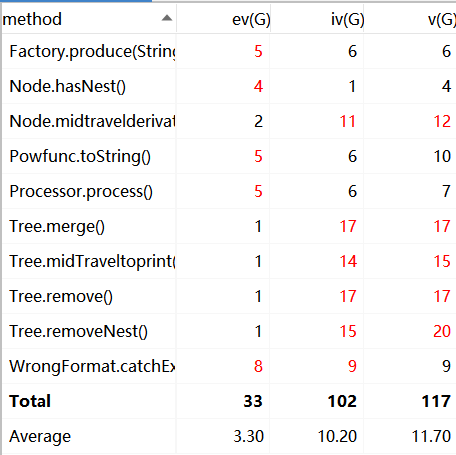
从图中可以看出:我的代码复杂度还是超标的,日后的联系需要多注意代码复杂度的降低
其中HW1超标的方法是Expression类的parse方法、toString方法以及item的getbigint方法,因为expression的两个方法一个是负责解析全部字符串,另一个是负责输出表达式,两个都涉及复杂的条件判断和格式处理,所以比较臃肿。而item的getbigint的方法是我自己写了一个状态机将带符号整数转化为biginteger,其实后来发现在new biginteger时直接将字符串形式的带符号整数作为参数传入即可。
HW2超标
Printer的print方法:复杂臃肿的原因与HW1的toString方法相同
Factory的produce方法:这个我有点好奇为什么会超标,按理说逻辑很简单因为这个方法只是传入一个字符串,返回一个factor类
powFunc的toString方法:这个也是设计简化的各种情况的判断,导致过于冗杂。
至于HW3,超标方法太多太多,而且主要是与新增加的两个类Node和Tree有关,究其所以是因为我在这部分代码中使用了大量的ifelse语句以覆盖所有可能的情况,在简化表达式树的过程中的remove, removenest,merge;例如在输出的过程中的midtreaveltoprint等等,事后回想很大一部分ifelse可以通过事先在输入时进行简单的处理来简化。
3 扩展DIT
第一次作业里内容较少,所以没有抽象继承和接口,在第二三次作业,使用了工厂模式,建立factor接口包括conct,powFunc,Sin,Cos四个类,还建立了Exception接口,包括WrongFormat和IndexExceed两类。
4 类图
HW1
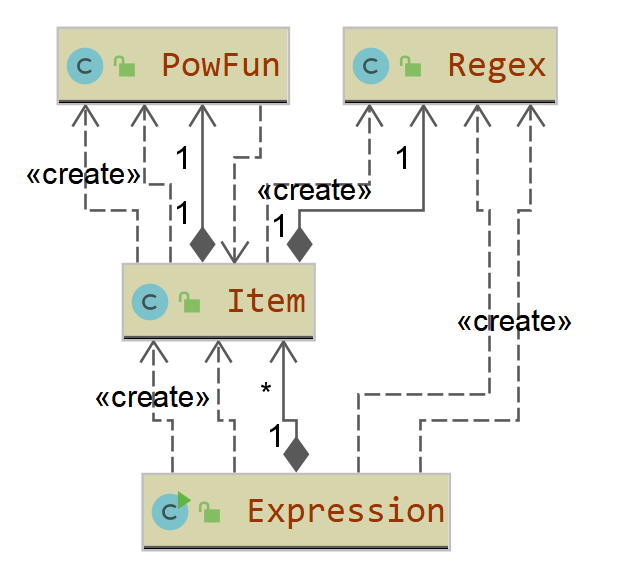
第一次作业中,我使用了三个类。Expression负责输入输出求导合并,Iteml负责对解析项,powFunc类负责存储幂函数信息,Regex负责保存需要使用的正则表达式。
我认为这次作业中成功之处在于:
-
自己逐渐从面向过程开始面向对象转变了
-
通过多个类的合作分工,将问题拆分各个击破
-
对表达式进行了充分的化简。
失败之处在于:
-
Expression类的承担的功能太多,可以适当将功能分给其他类
-
可扩展性不强
HW2
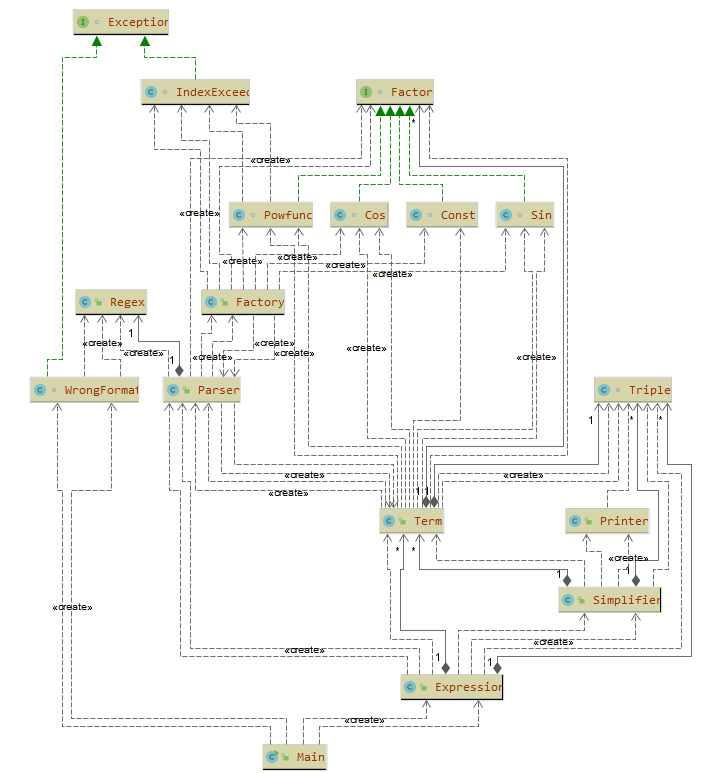
第二次作业在第一次作业的架构进行了大范围的优化,每个功能大致都有一个类来负责,例如pirnter,simplifier,parser,存取数据的类也有了term,triple,以及实现factor接口的类。
我认为这次作业的成功之处在于:
-
分工明确,逻辑清晰
-
大大提高了可扩展性
-
使用了递归化简得方法,化简工作完成得很好
失败之处在于:
-
没有预测到第三次作业括号迭代,可扩展性不能达到第三次作业服务的程度。
HW3
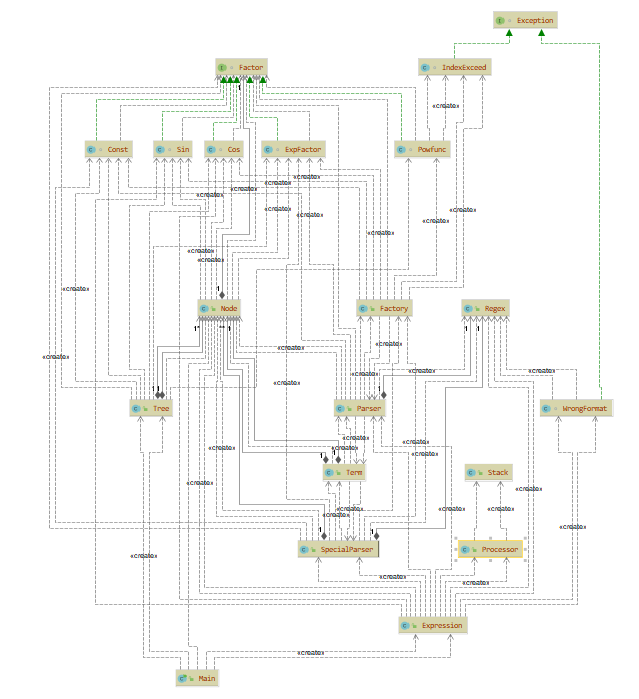
第三次作业结构发生了根本性的变化,我没有再采用map的形式来保存数据,而是使用了表达式树的结构
这次作业的成功之处在于:
-
使用了表达式树,成功处理了从第二次次作业到第三次作业的难度飞跃
失败之处在于:
-
在处理输入过程中使用的方法过于复杂,导致后续的简化输入表达式树的过程中也很复杂,因此花了很长时间在这方面debug
-
思路一开始不清晰,忘了函数传入的结点是形参,所以即使结点发生改变,原来的表达式树的结点也并没有任何改变
-
由于时间问题和稳妥起见,没有进行任何优化
二 分析自己的bug
HW1
第一次作业公测和互测均未出现bug
HW2
第二次作业时,出现了一个同质bug,我在合并同类项的过程中,覆写的compareTo出现了错误,具体表现为:
compareto比较的参数有幂函数的指数(a),sin的指数(b),cos的指数(c),为了在比较的同时实现排序,可是我脑子一时不清晰采用的二进制的思想,将最后比较的标准设为a×4+b×2+c。
HW3
第三次作业一共出现了三个bug
1 我在用栈处理表达式的过程中,没有进行越界判断
2 我在遇到乘法和嵌套的两个结点求导时,需要节点分裂,没有用一个括号将这俩结点包住再进行求导。
3 我在简化输出表达式时,多删去了一类括号嵌套
三、分析自己发现别人bug所采用的策略
这次的互测我主要采用的还是手动测试集的方式,手动测试集包括一般性数据和边界数据,但是我觉得下个单元有必要搭建自动测试机
第一次作业我发现了两个bug,同学A在标准输入1时,输出为空,显然这是优化过度的问题,解决方法也很简单,最后输出判断字符串是否是空,如果为空直接输出零即可,同学B的正则表达式的书写出现了错误:[\t| ],z在java的正则表达式中[abc]即有abc其中任何一个的意思,所以同学B加上|属于画蛇添足,不过虽然我找到的这个bug不能hack(因为输入数据不符合格式),但还是有必要指出。
第二次作业,可能是我的时间不太充足,构造的测试集过少过简单,没有发现任何bug,但是互测阶段过去后,我发现一些很易于察觉的bug我都没有察觉,所以我才决定下次作业需要搭一个测评机。
第三次作业,我hack了两个bug,同学A对于sin^49×sin^2判定为wf,同学B对sin(0)^0×x的输出直接为零,我猜测可能是优化时出现了问题,省略底数为0的幂函数和三角函数,但对于指导书给的这个特殊情况没有进行重分考虑。
四、应用对象创建模式
在第一次作业中,我使用Expression类来作为多项式表达式类,在其中通过产生符号-项的map,其中item类中包括幂函数的系数和多个连续相乘幂函数的指数的arraylist,然后通过regex类管理需要的正则表达式,成功实现了Exp-term-func的逐步划分。
第二次作业的对象在第一次的基础上大大优化,首先有Expression保存多项式的信息即符号-项的map,然后在Expression类中将解析输出简化分别交给parser,printer,simplifier,解析的过程大致与第一次作业相同,逐步向下拆分解析,不过第二次作业实现了Factor的接口和Factor的工厂,可以根据解析得到的factor字符串创建幂函数,三角函数,常数三种函数,另外也实现了exception接口,用于捕捉wf和指数过大两种的异常。
第三次作业
结构发生根本性变化,在表达式类中用表达式树的结构来存储表达式类,每个中间结点存储两个结点的运算法则,每个叶子结点存储一个因子,解析的过程需要使用stack类来辅助解析具有括号迭代的表达式,剩余解析的过程与作业二类似,逐层拆分拆到factor层次就使用工厂创建一个factor并用一个叶子结点来存储,其余的不同还有递归求导和结点分裂,输出也是递归输出。
五、对比和心得体会
对比
通过阅读学习优秀同学的代码,我认为优秀代码都有值得以下突出的特性:
-
逻辑清晰代码简洁:优秀同学的代码逻辑清晰简洁,各个类都比较精简,各个类功能简单明确,可以直观地看出不同模块针对的是哪一需求,可读性很强,而且读起来也很舒服,反观我的代码在这方面还有待提升,部分方法写的冗杂晦涩难懂,而且有的类自己嫌麻烦一些多余的方法也没有去掉。
-
严谨的命名:我认为这些优秀同学的代码还有一个亮点就是命名,命名可以说是代码非常小但又不可忽视的一部分,优秀代码中的命名规则符合驼峰原则,并且变量名根据真实功能取英文全称,既不会出现二义性也对其功能一目了然,而我的部分变量名很随意的命名例如in,s,output,input等等,所以我觉得在这些方面还需要进步。
心得
这三次作业我其实经历了很多,进步也很大。
第一次作业由于我寒假有些事情,pre的进度落下了一周,所以第一周我相当于一边写pre,一遍写hw1,所以就导致了我在没有经过面向对象的仔细思考,而急躁地采取一main到底的方式去写hw1,最后的结果很显然,在周五晚上我第一次提交:WrongAnswer!,然后我就按照正常程序走去debug,可是由于一开始思路不正确bug越de越多,我逐渐开始崩溃,因为明天就是ddl了,我抱着脑袋看着屏幕什么也做不下去,心态确实崩了眼睛也很不舒服,于是我洗了个澡让自己浮躁的心沉了下来。洗完澡后我首先阅读了讨论区大佬的帖子感到有所启发,然后我就不碰电脑,仔细用草稿本将思路仔细的理了一遍,之后做出了一个大胆的决定:前面的全部推翻直接重构,我清晰的记得那是晚上一点半,然后我睡了四个小时,早上五点半起来肝到上午九点,提交AC!,整个过程不到四个小时,而重构前我所花费的时间大概是两倍以上。
所以我懂得了:
一 切记切记切记(重说三)想好了再动手
二 多主动提问多阅读大佬的帖子确实对自己大有帮助,这是OO和计组都教会我们的
三 自己每写好一个部分一定要做好充分的测试,我重构前debug太久就是小错误积少成多