第一次作业
简单的幂函数求导,输入格式相当清晰,因此采用了HashMap,以指数为Key,系数为Value的方式存放表达式,并封装成Poly类,通过输出时按系数大小预排序尽可能避免了开头出现负号,因为设计过于简单并未被迭代沿用,不多叙述。
程序结构
Poly类152行,负责解析字符串,求导,输出字符串
MainClass类,负责输入输出
自己程序的Bug
未发现
发现别人程序的Bug采用的策略
手动构造特殊数据,例如输入的指数系数为正负1,0,输出的指数系数为正负1,0,允许范围内的多余正负号等数据
第二次作业
加入了sin(x)和cos(x),此时情况依然不算很复杂,初步打算可以在第一次作业的基础上,处理完空格后将sin(x)替换为y,cos(x)替换为z,从而方便数据读入,建立存放sin的指数,cos的指数,x的指数的三元组Term类,使用以Term类为Key,以系数为Value的HashMap存放表达式并封装成Poly类。
但考虑到之后作业的扩展性,没有采用初步的想法,重写了所有数据存放结构和输入处理。
程序结构
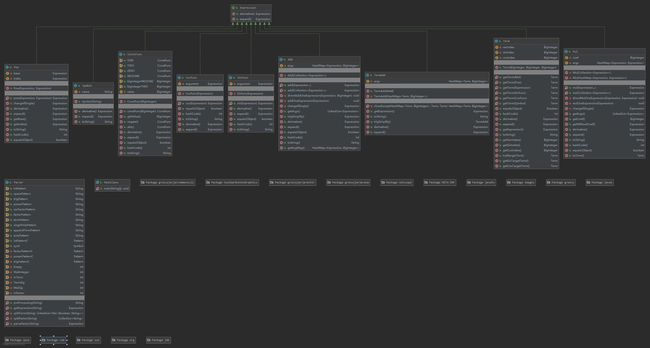
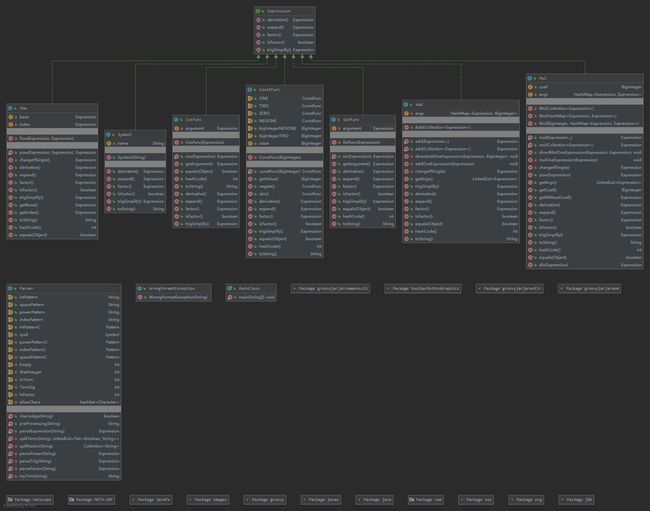
对于数据结构的建立,采用多叉表达式树表示表达式,即Expression接口,提供derivative方法求导和expand方法用于展开。
Expression接口有Add,Mul,Pow,ConstFunc,CosFunc,SinFunc,Symbol七个实现类,均被设计为不可变对象,均重载了toString方法以实现输出,显然toString方法是逐层调用子表达式的toString实现的,并且为了最简化加了一些特判
算术函数的构造器均设计为private,而通过提供public的运算方法add(args),mul(args),Pow(base,index),constFunc(biginteger),cosFunc(arg),sinFunc(arg)来获得新实例,从而使得在通过运算构造新对象的时候能够自动实现一些化简(这导致add方法返回的对象不一定为Add对象之类的情况),并使用重载提供了一些语法糖
对于输入的处理,采用了偏向于采用面向过程的方式,建立了一个没有任何属性的Parser类,这个类的所有方法均为static的,对外提供的方法是getExpression(String str),从字符串得到Expression类。内部实现则采取先split成为依旧是string的term,再split成为依旧是string的factor,这两步通过手写状态机实现,此时得到的factor已经相当简单,在通过正则表达式判断格式后通过parseFactor得到Expression类返回并在上层函数中调用Expression实现类提供的算术函数链接起来。
最后为了方便实现更复杂的三角化简,额外建立了Term(三元组)和TermAdd(Term,BigInteger的HashMap)类并提供相关化简方法,将得到的Expression类先转换为TermAdd后再化简。
数据分析如下图
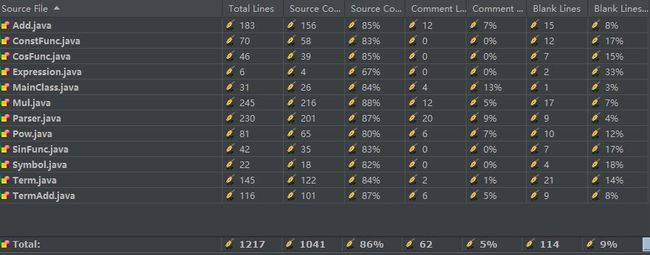
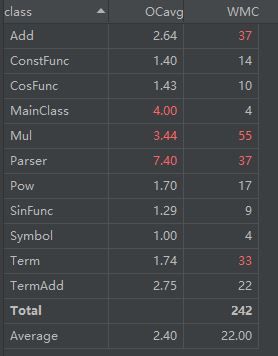
可以看到Add,Mul,Parser为三个较大的类,占据代码行数很多,循环复杂度也高,Parser类独自实现了输入处理,涉及到多个正则表达式和两个状态机,因此较为复杂
而Add类为多元加法,采用Expression,BigInteger的HashMap处理数据,每一个子表达式被提取系数后作为Key,而系数作为Value,目的是能够自然合并加法表达式。
Mul类采取了类似Add类的措施实现合并同底数的乘法,因为不知道第三次作业的扩展方向,支持了Expression作为指数以方便扩展。
因为加法和乘法具有很多很好的性质,这两个类的化简和输出方法是程序的主体部分。而Pow,ConstFunc,CosFunc,SinFunc,Symbol则分别表示了幂指函数,常数,cos,sin,变量。
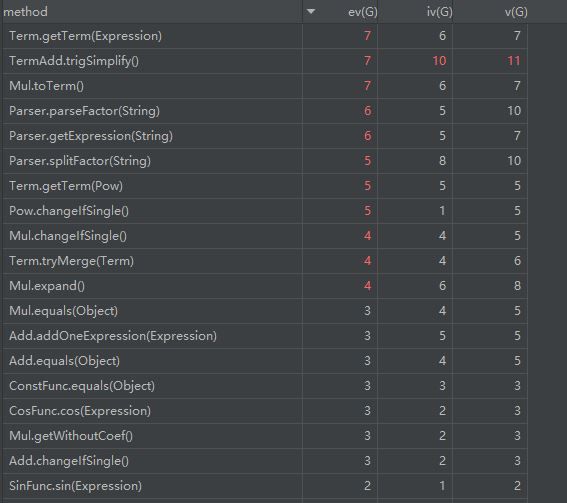

截取部分ev较高的方法数据来看,不考虑Term,TermAdd类相关的方法,因为这两个是针对第二次作业的输入特点来化简搭建的临时脚手架,没有做太多设计结构上的考虑,说简单点就是临时瞎写的。。。
可以看到Parser类的parseFactor,getExpression,splitFactor占据前三,具有很高的复杂度,其原因可能在于解析字符串时的多层循环、条件语句嵌套,且思维偏向面向过程。
从抽象层次深度来说,没有使用到继承,使用了一个接口Expression。个人而言,并未发现表达式处理中有什么需要构造更深层次的抽象结构的需求。
自己程序的Bug
发现1个Bug在Parser类,数据读入时,由于调用了trim方法,将空格与水平制表符以外的非法空白字符也去除了从而无法正确识别WRONG FORMAT,通过将trim换为只去除开头结尾的空格和水平制表符的myTrim完成了修复,
发现别人Bug时采用的策略
写数据生成器与对拍器,通过正则表达式随机生成一组数字,空白项等基本元素,然后按照形式化定义逐层随机拼接生成数据,在生成基本元素时除了随机生成,额外加入了正负1,0等特殊数据。
由于自动生成的表达式一般偏长,手动添加了一些短表达式,如仅数字,单字符,双字符,单项之类的表达式加入对拍。
第三次作业
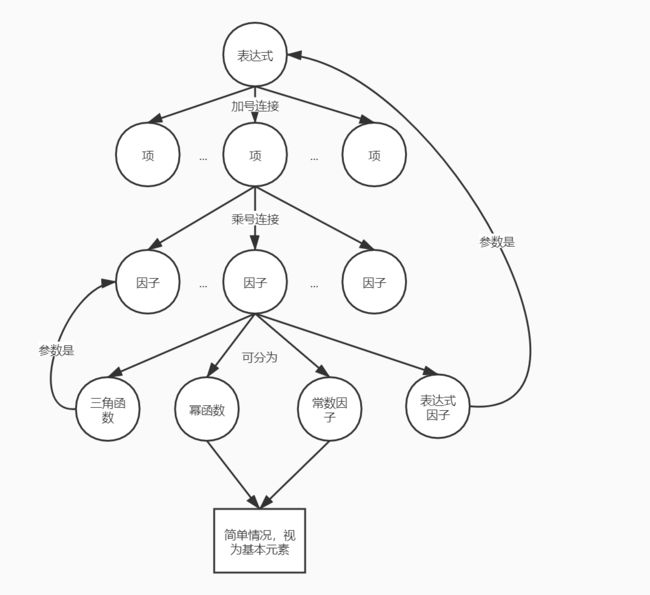
加入了嵌套结构,因为第二次作业在数据结构上实际已经支持了任意层的嵌套,并且完成了一部分相关的化简,在输入处理层面上已经考虑到了空格格式异常以及层层分割的递归解析字符串表达式,第三次作业其实没有进行多少改动,主要内容在于调整输入处理以支持嵌套,去除了临时的Term和TermAdd类以及相关的三角化简,Expression接口增加了更复杂的化简手段,提公因式factor和三角化简trigsimplify,由于三角函数内可以填因子却不可以填表达式,因此添加isFactor方法来判断是否为因子。
总结来说,程序需要完成输入数据的处理、表达式的求导、表达式的化简、表达式的输出四个部分,以下再逐一概括一下
一、输入数据的处理完全遵循形式化定义分层解决
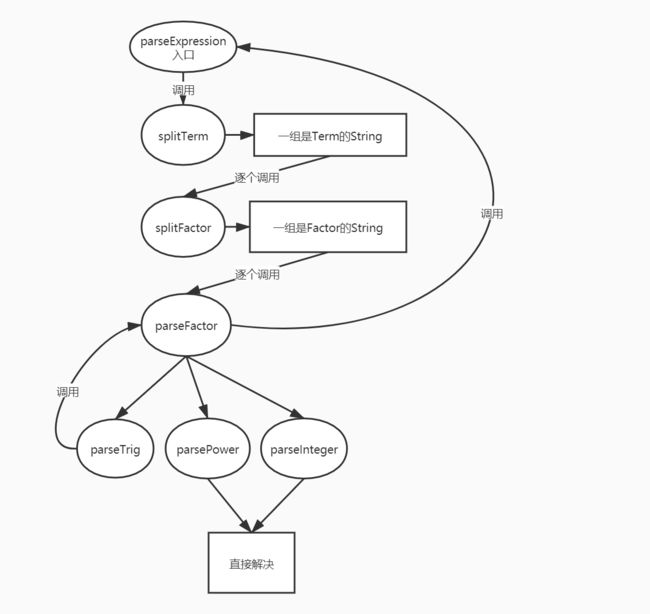
每一级的parse都只去除该级定义中允许的空格,解析该层的结构,判断得出该级能够判断出的WRONG FORMAT,提取出下一级的元素,而 parseExpression由于过于复杂被分出两个子方法来完成split,它们均使用有限状态机来实现,通过记录遇到的未匹配左括号数目避免划开括号,使用StringBuilder暂存读取的数据,简单来说,splitTerm就是找出裸加号之间的部分并且去除两端空格,splitFactor就是找出裸乘号之间的部分并且去除两端空格,绝大多数的异常将在parseFactor识别到因子不符合以下四种中任意一种的格式时抛出,parseFactor四种情况中最复杂的方法为parseTrig,因为它需要区分两种三角函数,并且提取内部的因子和后部的指数,而parseFactor遇到表达式因子的时候,直接去掉两端括号后调用parseExpression。
二、表达式的求导由每个表达式实现类的deriverate方法完成,Symbol类,ConstFunc类的求导返回值是naive的,而SinFunc类,CosFunc类,Pow类则需要调用子表达式的求导方法,Add类,Mul类作为多元函数求导方法较为复杂,Add类是简单的将子表达式求导后调用add方法求和,而Mul类则用到了n元乘法求导法则,进行了一个O(N^2)的计算。
三、表达式的化简,化简的思路主要是合并同类项、提公因式、计算出可计算的值、sin(e)**2+cos(e)**2=1,由于有些表达式可能在展开后出现可合并的同类项,因此需要expand方法。首先通过对构造方法的实现与封装,实现了合并同类项,计算可计算的值、去除0系数等等工作,然后提供化简的三种方法expand展开,factor提公因式,trigsimplify三角化简均由Add类的对应方法作为主要部分,它先对所有子表达式调用该方法,然后将子表达式出现的Mul类拆开(expand)或将子表达式中的因子提出(factor)或将子表达式中的可合并三角函数合并(trigsimplify),其它类的化简方法则负责对所有子表达式逐层调用对应方法,鉴于factor和trigsimplify几乎总是使表达式变短,而expand却不一定,最后在main中尝试调用expand+factor+trigsimplify,factor+trigsimplify,不化简单,然后选择最短的结果输出。
四、表达式的输出,由于每个Expression的实现类都可以直接调用子表达式的toString得到输出,然后按照自己的类型恰当的拼接即可,每个类需要做的工作都非常少,因此toString的实现很简单,结果也很简洁。
其余结构均与第二次作业基本相同,数据分析图表也基本一致,不再重复。
自己程序的Bug
未发现
发现别人Bug时采用的策略
与第二次作业相同
应用对象创建模式重构
没有直接使用构造函数创建对象,关于对象创建,考虑到是对于表达式的建模,认为应该通过运算符(由于Java不可重载运算符,因此指算术函数)来创建表达式对象,因此除了最基本的Symbol类使用构造函数创建,ConstFunc类由BigInteger构造,其余的类的构造器均为private的,以Add类为例,对外提供方法public static Expression add(Collection
心得体会
本单元中从第二次作业开始,对类间的功能划分比较明确清晰,在此基础上实现输入、化简、输出时充分体会到了其好处,并且具有很好的扩展性,用一个新的类将各种运算函数add,mul,pow,constfunc,sin,cos聚合起来,以避免使用运算函数时需要去对应的类调用,同时使用这些方法可以直接再增加实现一些sub,div等方法也许会更好一些,但是当时懒了懒就没有做。
一些类的实现,类内部的各个方法功能划分、方法实现还不够简单清楚,导致存在一些偏长的方法,循环/条件嵌套过深的方法,内聚性低的方法。
例如,在化简工作做到后期的时候,发现是否确实有必要使用Map来存放Add类和Mul类的内部数据是一个值得考虑的问题,注意到Expression均是不可变对象,因此合并同类项仅仅发生在出现一个新实例的时候,如果在构造器或者提供的运算函数中采用Map临时存放数据,在合并完毕后转换为对应的List存放对于这两个类内部的方法实现可以提供很多方便,因为很多方法的实现都需要进行遍历,而Map导致经常需要专门处理Value(即Add中子表达式的系数,Mul中子表达式的指数),导致额外的代码甚至是遗忘处理导致Bug,事实上为了解决此问题,我不得不实现了一个getArgList方法来得到对应的List。
还有一个小问题是hashcode方法没有采用Objects.hash这种现成的库函数(因为当时不知道),而且在将各个属性的hashcode加权加起来的时候不仅没使用2的幂-1作为系数,甚至直接采用了2的幂作为加权系数,导致冲突量可能会很大,当然在数据量极小、运算时间充沛的情况下并没有引发任何问题。
另外在三次互测中我总共只找到一次他人Bug,而第一和第三次作业的互测屋中都有着几个被别人发现却被我忽略的问题,提醒我也许需要更多地考虑如何构造测试数据,一方面是手动写出特殊数据,另一方面也是编写数据生成器时可以采用怎样更好的策略。